I think it’s time we see machine learning for what it really is: a human-made algorithm, coupled with human-made assumptions, supported by a human-made science called mathematics.
That is why any expectation that machines can go beyond the bounds of what they were programmed to do will only result in disappointment, failures, and, in the worst cases, death and disaster.
Sounds grim, doesn’t it? But here’s the problem: machine learning did nothing for the hundreds of cities and regions that were affected by COVID-19. Why was that? Was it because those regions failed to put regulations in place to stop the transmission? Or was it because—even with them in place—we chose to ignore them? Both, most likely.
Machine learning failed to predict anything for those regions because nothing like it had ever happened at such a scale in those regions before.
You see, to date, the number of parameters—including assumptions, dates, population, and other data that affect what machine learning can predict about pandemics —turns out to be nothing.
I am not a conspiracy theorist.
But by the same token, I find it hard to believe or accept that although we can predict churn rates and fraud and we can land staging rockets upright upon their return from the stratosphere, yet in spite of having amassed almost a year’s worth of data from multitudes of hospitals, cities, countries, and regions, we still can’t predict the spread and death curve of such a virus.
Some claim we are missing data or the data is faulty, but if that is the case, then we have to ask if there is any natural or human-driven process that doesn’t have faulty, missing or poor-quality data. And, if we do have all the data—close to 100% of the data—why would we want or need AI? What is left to predict, segment, or forecast?
The Model
To select the right model for making predictions, a sample of the data must get fed into a variety of algorithms, and the most fitting ones are then selected. Then the remainder of the data is fed into the chosen algorithms to start making predictions or forecasts.
The process could help hospitals and cities alike allocate resources and be better prepared—providing an early warning system of sorts, one that does not tax the entire country with economic distress, bankruptcies, unemployment, and other health issues, but focuses attention and remedies in predicted regions.
AI could correlate airline travel data with new COVID hot zones to see if travel restrictions should be imposed. In fact, these models could include not just travel data but store sales, movie ticket sales, or something as simple as the weather. In areas that are not designated as hot zones, people could go out more, with or without masks.
Do we see any outcomes of this kind? No.
There are no models. No predictions. There aren’t even any hypotheses. There’s only a see-saw of government decrees that somehow forbid nightclubs but allow movie theatres, that ask everyone to wear masks but keep borders open, that come up with new regulations, but they won’t start until next month!
Pessimism Will Get You Nowhere
This blog is criticism about AI and ML and how it has failed us—not how any particular government, municipality, or health organization chooses to implement restriction rules.
It is a critical analysis of how data science has failed us at a time when it matters most. I mean, it’s OK to predict fraud; the worst that can happen is someone’s credit card gets blocked when they try to pay for something, and they will call their credit card company and release the hold anyway. Problem solved. Minimal impact. Definitely not life-threatening.
The customer churn was off by 10%. So what; big deal. Next year, we will do better. Our target numbers will be revamped to reflect the new data. No impact. No deaths.
Your video game bot just stands around doing nothing, Watson or AlphaGo lost at checkers. Your website chatbot has no clue how to reply to a certain customer. So what? Next time: “Good try. Let’s change some additional code to make it better.”
But we are not talking about trivial things now, are we? This is what we want AI to do in the end, isn’t it? Make our lives better, safer, and healthier?
But how can we trust a self-driving car powered by AI if we can’t even predict where, when, and how many are going to be affected by a virus — or even if we will ever be able to stop wearing masks?
“They Know”
Of course, we can think that someone out there knows—some highly-intelligent scientist or government entity has it all figured it out. But that, of course, is not true.
The truth is that AI and ML are just what we always knew them to be: programs built by humans to accomplish specific tasks only. When confronted with doing anything outside of what they are programmed to do, they will just throw exceptions. In some cases, fatal exceptions.
Nearly a year’s worth of data later, and no lessons have been learned, as there is nothing to learn. The models are built, and they are all wrong. Predicting elections is easy—there’s typically a one in two chance of getting it right. But modeling COVID is not something that is feasible today or for the next 25 years, most likely.
Will AI Ever Become a Reality?
Yes, it will. And while I am pointing out that today’s AI is nothing more than a service-driven, data analyst/developer-led activity and that what we hear about it is just a bunch of marketing and sales buzzwords, I also believe that the future will eventually lead to the emergence of a self-learning machine that will finally be capable of helping humankind—or at least those able to afford it.
But, for that to become a reality, a few things will have to happen first.
Stateless Machines
Most machines today rely on coding that references a state to understand its next action. If “On,” then “Do this,” If “Off,” then “Do that.” Multiple-choice options are still variations of the same principle. For example, “Switch” or “Case” statements iterate via several options and then decide on one option to continue processing.
Stateless machines work differently, however. In essence, several events can be taking place at the same time, which exposes the machine’s own state and triggers what to do next. This is very advantageous because multiple data chunks could be processed and reprocessed independently, contributing to a larger assessment of the statistical model.
Quantum Machines
Much like stateful coding, the fact that computer processors still operate with 0s and 1s makes coding simple but by no means efficient or speedy.
Advancing work in quantum technology would allow for a much less binary way of assessing model properties while providing a higher degree of accuracy.

Faster and Better Databases
Much of the work we’ve done to make databases faster has been offset by the fact that we also make them more flexible. Node-based or document-based databases, a.k.a. NoSQL databases are good examples of this. But as a result of making the databases more flexible, their ability to do aggregations and analysis of the data becomes more difficult. At the same time, faster disk technology (SSD and RAM-based storage such as Redis) offsets the performance hit along with other approaches, such as columnar or vertical data storage.
Still, much of the reading and processing data bottlenecks have to do with the database’s capacity and performance. There’s more data and better data for the machine learning models, but it comes with a slower speed to process it.
Unfortunately, while we have been able to make tremendous headway, at a logarithmic pace, in increasing the capacity of disks, we are still very linear when it comes to read speed.
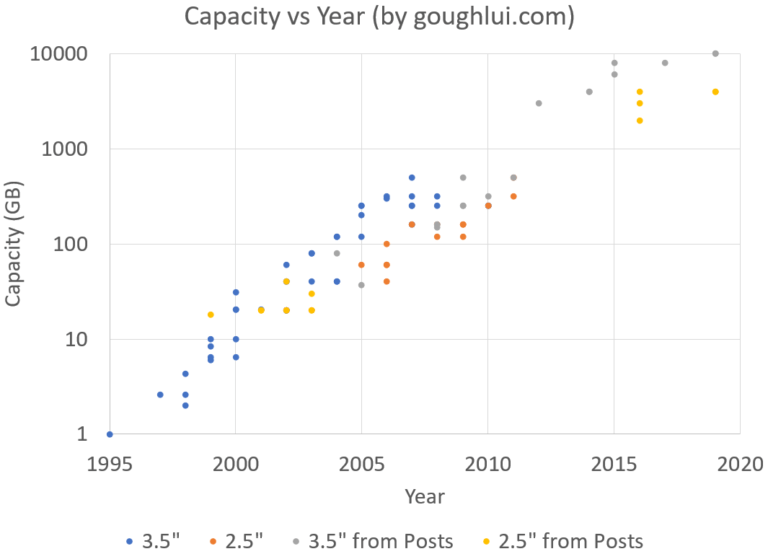
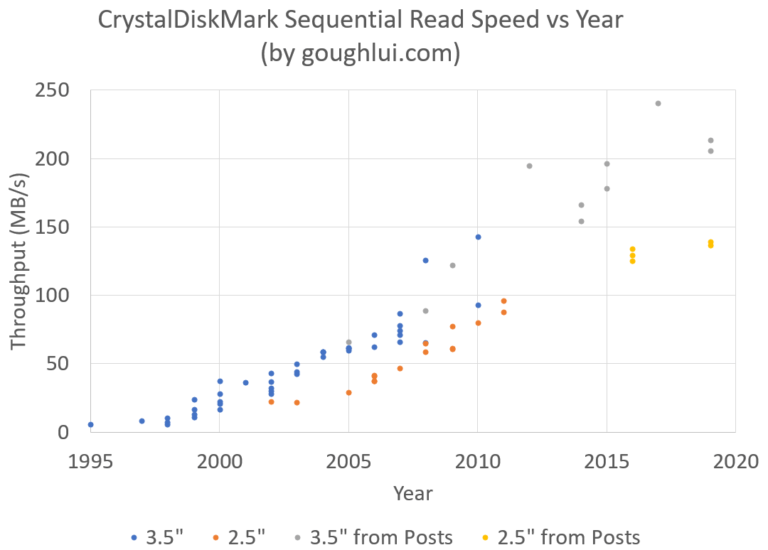
via Goughlui.com
Unlike the rate of capacity increase, disk drives have a linear rate of performance increase.
New Programming Languages
Considering all of the above, we will need new programming languages, syntax, and compilers. Any programmer today can tell you that one of the most difficult things to program is asynchronous codes, multi-threaded applications, and event-code, so you can imagine that, with stateless and quantum machines capable of data crunching at a very high speed, the code itself needs to be adapted to handle it.
Python and R are great languages for machine learning, but they are almost 4G—simplistic languages that perform poorly and are interpreted, not compiled. (As for those who feel otherwise, simply remove PVM from a machine to see if it runs natively.)
Data Collection
One final concern, which might have little to do with technology, is the fact that machines can only learn from data that exists. One of the biggest issues with COVID-19 is the fact that data is missing, badly-reported, not reported at all, reported in shifts or batches, politically distorted (as countries, regions, and hospitals under-report to appear safer or not affected), or otherwise just numerically inaccurate. You can read more about that topic in my previous post “Illiteracy, Innumeracy & Illogicality.”
Summary
In an effort to make things more newsworthy and appealing to readers, media and marketing companies often present a distorted view of what Artificial Intelligence and Machine Learning is and what it can do.
Although AI and ML are a very important thread in data science and computing, they are merely software algorithms at an early stage of development, not yet perfected nor ready for primetime use. At best, they are a simple set of instructions, pre-packaged by developers, to calculate a response based on a known set of variables and events and achieved by artificial neural networks and other deep learning methods that require extensive training—both from humans and from itself.
At their very best, AI and ML can win a game of chess or checkers. At their worst, they are vaporware, software that doesn’t exist or really does nothing to help us, especially when we need it such as with the current COVID-19 pandemic.

