For years, businesses have relied on ETL (Extract, Transform, Load) as the primary method for centralizing data and driving analytics. While it’s effective for generating historical reports, it often leaves important insights trapped in data warehouses, keeping them out of reach from the tools that could put them to optimal use.
According to McKinsey, fewer than 20% of companies fully used advanced analytics. This means most businesses struggle to make real-time data-driven decisions.
Traditional ETL systems pull data, clean it, and store it in a central location, which is ideal for generating reports. But when it comes to providing real-time, up-to-date information, business teams are left in the dark.
Reverse ETL solves this problem by pushing insights from the data warehouse back into the tools like CRMs, marketing platforms, or customer support systems, which teams actually use. Providing real-time access to this data empowers you to break down silos and drastically reduce the time spent manually wrangling data.
In this guide, we’ll discuss how Reverse ETL functions, the role of data streaming, and key best practices for data analysts looking to activate data at scale.
How Reverse ETL Works Empowers Data Analysts
Reverse ETL is a powerful tool for data analysts. It solves a major problem businesses face: acting on data stored in warehouses in real time. Traditional ETL centralizes data for analysis, but Reverse ETL sends that data back into tools used daily. It activates data by feeding real-time updates directly into business applications.
How Does Reverse ETL Work?
Reverse ETL follows a straightforward but impactful process. It moves data from a data warehouse to operational tools like CRMs, marketing platforms, and business applications. Here’s how it works:
- Extract: In a Reverse ETL workflow, the process begins with querying a data warehouse (e.g., ClicData, Snowflake, Redshift, BigQuery) to retrieve curated or modeled data that’s ready for operational use.
- Transform: The extracted data is optionally reshaped or mapped to match the schema and constraints of the destination system (e.g., renaming fields, formatting values, ensuring compatibility).
- Load: The final data is delivered to operational systems—such as CRMs, marketing platforms, or support tools—via APIs or native connectors, enabling real-time or scheduled synchronization.
This process ensures that teams have real-time, actionable insights within the tools they use daily.
Automating Repetitive Workflows
Reverse ETL simplifies repetitive tasks, reducing the need for complex SQL queries and manual data exports. Once set up, data automatically flows between the warehouse and operational tools, requiring no manual input. This process saves time and keeps data updated across systems, ensuring everyone in the organization has access to the latest information.
Removing Engineering Bottlenecks
Reverse ETL removes the bottlenecks caused by relying on data engineers. Engineers must create custom scripts or APIs for each data request in traditional systems. Reverse ETL let’s data analysts manage the flow of data, speeding up the process and making data available instantly. This shift is especially important for small businesses that might not have the resources for large engineering teams.
For larger organizations with multiple departments, reverse ETL eliminates silos between departments. With all teams working with the same up-to-date data, decisions can be made quickly without waiting for approval or custom work.
Real-Time Decision-Making
For data analysts, Reverse ETL is a way to activate data, enabling businesses to use insights in real time. It streamlines workflows, improves efficiency, and drives better results across departments.
A clear example is managing customer churn, which is the percentage of customers who leave or cancel their service within a given period. The cost of customer churn (also called customer attrition) is significant for companies relying on long-term customer relationships since it has a long-term impact on growth, brand loyalty, and reputation.
Reverse ETL can empower data analysts to operationalize data and help organizational departments address customer churn more effectively. Key data, like usage patterns and payment history, can be sent to tools used by customer support or marketing teams. This empowers teams to immediately act upon early signs of churn and improve retention.
Likewise, reverse ETL allows you to operationalize data and trigger real-time actions. A reverse ETL workflow can prompt an automated response when data is updated. For example, when a particular customer’s usage drops or the system detects a payment delay, the relevant account manager can be directly alerted via email. Addressing risks to customer churn in real time can help your organization keep customers satisfied.
Introducing Data Stream: A Next-Gen Reverse ETL Solution
As businesses push for faster, data-driven decisions, traditional ETL and Reverse ETL systems often can’t keep up with the demand for real-time data syncing. ClicData’s Data Stream solves this problem by automating real-time data transfer, ensuring smooth integration between systems and tools.
What is Data Stream in ClicData?
Data Stream provides a solution that keeps data synced between sources and operational systems. It allows users to choose when they want to execute it via a schedule, and almost in real-time (executed once every minute). It removes the need for batch processing, ensuring data is up to date without complex workflows or custom code.
Data Stream helps with:
- Data Syncing: Unlike batch processing, Data Stream updates data ensuring tools always reflect the latest information.
- Direct Integration: It easily connects with data warehouses, SaaS apps, and APIs, without requiring complex coding.
- Event-Driven Updates: Data Stream updates only relevant records, reducing unnecessary system load and making the process more efficient.
How Data Stream Differs from Traditional ETL & Reverse ETL
While ETL and Reverse ETL help move data between systems, they operate in batches and often introduce delays. This is where Data Stream stands out.
- ETL (Extract, Transform, Load): Traditional ETL moves data from operational systems to a warehouse for analysis. While useful for long-term analysis, it doesn’t support real-time decision-making.
- Reverse ETL: Reverse ETL moves processed data back into operational systems like CRMs or marketing tools. However, it’s often limited to periodic updates rather than continuous syncing.
- Data Stream: Unlike both ETL and Reverse ETL, Data Stream enables data syncing upto one refresh per minute. This keeps operational tools up-to-date without delays or batch updates.
ClicData’s Dual Support for ETL and Reverse ETL
ClicData simplifies workflows by supporting both ETL and Reverse ETL in one platform. Whether you need to move data into a warehouse for analysis or push real-time insights to operational tools, Data Stream automates both tasks, reducing bottlenecks and giving teams immediate access to the data they need.
ClicData’s Data Stream offers powerful features to streamline data workflows:
- No Complex Pipelines: Traditional workflows often require custom scripts and manual steps. With Data Stream, everything is automated, ensuring smooth data flow.
- Multi-Source Compatibility:
- Databases: Data Stream handles primary keys effectively, ensuring data consistency and preventing duplication.
Setting Up a Reverse ETL Workflow in Data Stream in 3 Easy Steps
Getting started with a Reverse ETL workflow in Data Stream is easy using ClicData’s no-code/low-code framework. Here’s a quick guide:
- Configure the Data Source: Connect to your data warehouse (e.g., Snowflake, BigQuery, Redshift) and select the relevant tables or queries.
- Define the Destination: Choose the operational tool or application (e.g., HubSpot, Salesforce, Google Ads) and map the data fields.
- Automate Data Syncing: Set triggers for automatic syncing (e.g., “Sync new customer data every 5 minutes”) and apply filters to send only relevant updates (e.g., updates for active customers).
This simple setup ensures data stays up-to-date, giving teams immediate access to insights without the need for manual exports or batch updates.
Use Case: Retaining Customers for a SaaS Subscription Business
Many businesses use past data to track churn, but it’s too late by then. Companies must act in real time to keep customers, not after they leave.
Powered by ClicData’s Data Stream module, reverse ETL automatically moves customer data between systems. This allows you to keep teams updated with real-time information. It connects data from CRMs, payment systems, and support platforms, then pushes it into marketing tools and customer success platforms.
With this setup, teams can see early warning signs, reach out to disengaged users, and send targeted campaigns before customers churn. Let’s review how reverse ETL can help a SaaS-based subscription provide personalized insights to different teams across the organization.
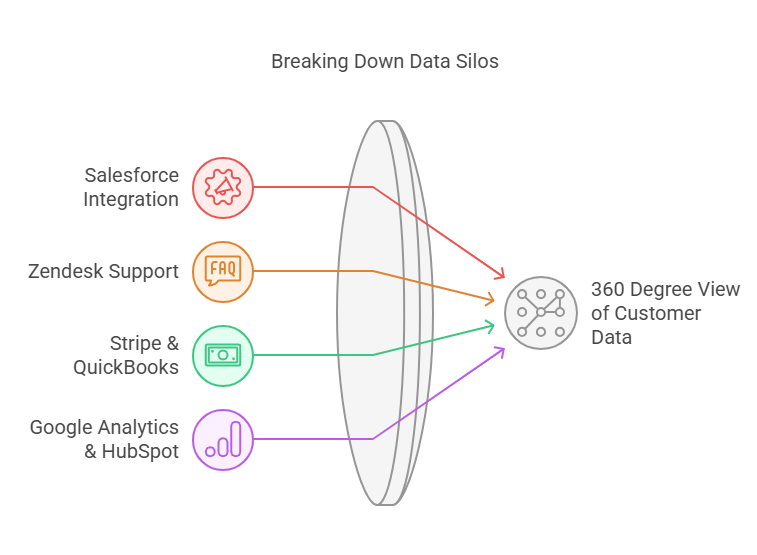
Step 1: Centralizing and Cleaning Data to Eliminate Silos
The SaaS company must gain a 360-degree view of customer data to understand why customers churn. Usually, customer data is fragmented across different departments. When teams work with disconnected information, customer engagement efforts become inefficient.
ClicData solves this issue by integrating data from multiple platforms into a single, unified system. The platform supports 250+ connectors and lets you connect data from essential business tools like Salesforce, Zendesk, Google Analytics, Stripe, and QuickBooks. Integrating data from these sources helps sales, marketing, and customer support eliminate silos and create a single source of truth for analysis.
Step 2: Data Sync with ClicData’s Data Stream
Data syncs can empower the SaaS business to engage with customers more effectively and prevent churn. ClicData helps users automate data synchronization across marketing, sales, and support tools. This keeps all departments aligned with the latest customer insights.
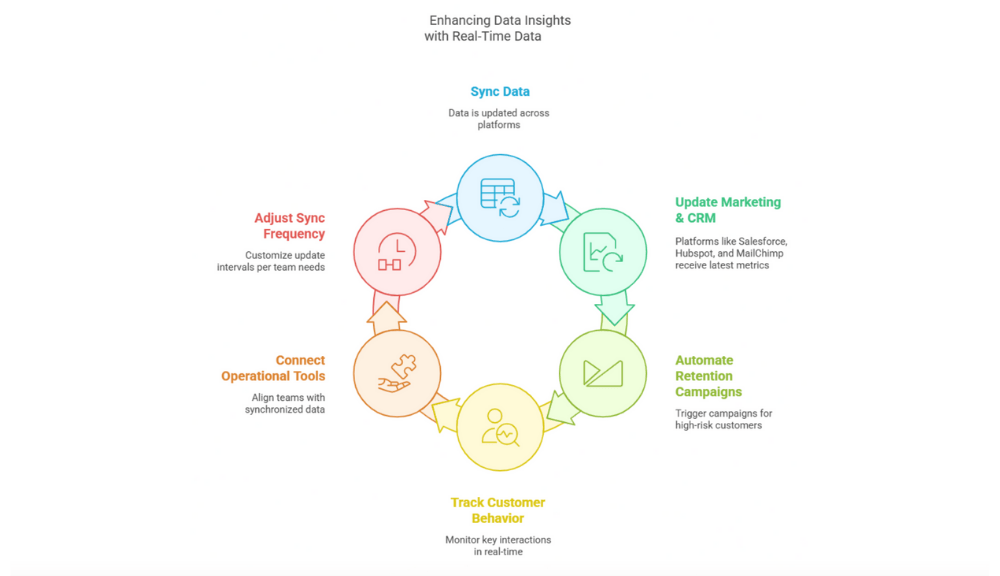
Syncing Data to Marketing and CRM Platforms
ClicData connects platforms with the latest customer engagement metrics, churn risk scores, and behavioral data. This real-time sync allows marketing and customer success teams to make informed decisions instead of relying on delayed reports.
Automating Retention Campaigns
ClicData enables a SaaS business to automate retention campaigns the moment a customer shows signs of churn. High-risk customers are flagged in Salesforce or HubSpot, triggering personalized outreach, whether it’s a special offer, a loyalty reward, or a targeted email. No manual input is needed, allowing the business to keep retention efforts fast and efficient.
Tracking Customer Behavior in Real Time
Customer activity provides valuable signals for engagement teams. In ClicData, you can build indicators to track key interactions. This includes dropped usage, late payments, or abandoned carts. Next, it syncs them with sales and support tools. Zendesk can trigger proactive support outreach, while Salesforce can alert sales teams to check in before the customer disengages completely.
Connecting Operational Tools
Data integration keeps teams aligned. ClicData’s Data Stream syncs critical customer data across various platforms like Salesforce, HubSpot, and Zendesk. Collaboration becomes seamless when all teams work with the same real-time data, and responses become more effective.
Setting the Right Sync Frequency
Every team moves at its own speed. ClicData’s Data Stream let’s SaaS businesses adjust sync frequency to fit their needs. The sales team can get churn risk and payment updates in Salesforce every five minutes. Simultaneously, the customer support team can refresh data in Zendesk every ten minutes, helping support teams stay informed without overloading the system.
Moreover, with real-time data flowing across platforms, the SaaS business doesn’t have to rely on manual updates. As a result, teams can engage customers at the right time, automate retention strategies, and stay ahead of churn risks.
Step 3: Automate Reports and Dashboards with Churn Insights
ClicData automates personalized reports and dashboards, giving teams a predictive view of customer behavior. We have analyzed the customer churn dataset to showcase how various churn-related insights can be delivered to different teams.
- Support Call Volume & Issue Escalation: Customers who receive four or more support calls in a billing cycle are more likely to leave.
- Contract Type & Commitment Level: Monthly subscribers churn more frequently than those on annual plans.
- Older Customers Are Leaving at a Higher Rate: Despite making 1.33 times more support calls than those aged 46 and below, older customers are still more likely to churn.
- Payment Delays & Churn Risk: Customers delaying payments by 13+ days are 20% more likely to cancel.
- Usage Drop-Offs: A 30% drop in engagement over two billing cycles signals a higher churn probability.
Tracking these insights allows teams to take immediate action:
- Sales teams can prioritize contract renewals for at-risk customers.
- Marketing teams can automate re-engagement campaigns based on churn probability.
- Customer success teams can focus on customers showing early signs of disengagement.
Let’s see how ClicData empowers sales, marketing, and customer success teams to take proactive steps to retain customers before they leave through personalized dashboards.
Live Dashboards for Real-Time Collaboration
Dashboards provide a central place to track key churn indicators. With ClicData, the SaaS business can monitor real-time data and respond to early warning signs. ClicData enables live dashboard links. This allows executives, sales teams, and marketing managers to access up-to-date insights without manual exports. These dashboards provide:
- Timely decision-making: Churn risk data updates in real time, helping teams respond faster.
- Seamless collaboration: Sales, marketing, and customer success teams stay aligned with the same data.
- White-labeled branding: Dashboards can be customized for presentations, ensuring consistency across reports.
Automated Reports for Key Stakeholders
Scheduled reports keep leadership and key teams informed without requiring manual updates. ClicData automates email reports for these and many other such business insights, covering:
- At-risk customer segments: Sales teams receive weekly reports to target customers for contract renewals.
- Engagement trends: Marketing teams get real-time updates on campaign performance.
- Retention campaign effectiveness: Customer success teams track high-support customers to resolve issues before they escalate.
Step 4: Personalized Customer Engagement
The SaaS subscription business can leverage ClicData’s reverse ETL capabilities to automatically provide personalized insights to different teams in real time.
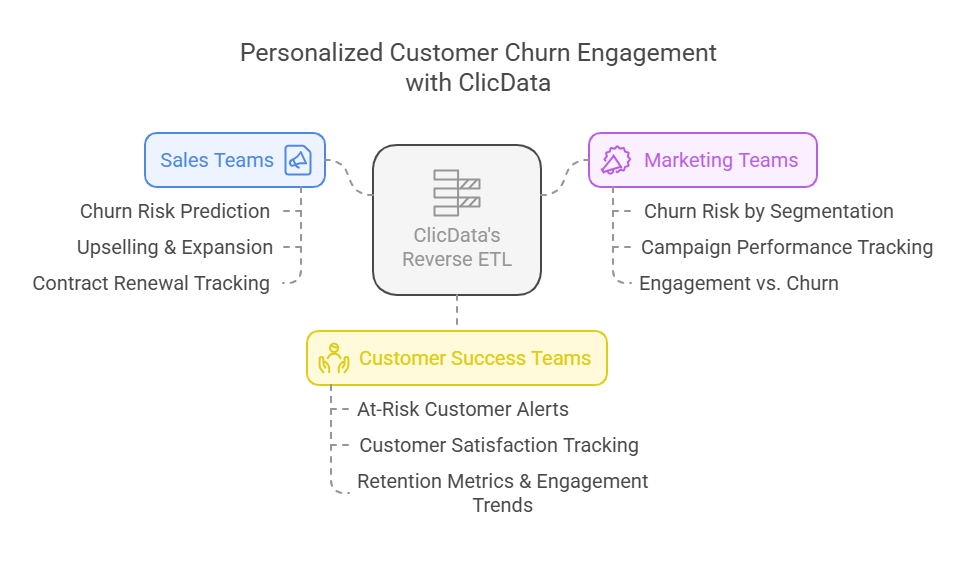
Using automated dashboards and reports, the SaaS businesses can track churn in real time, automate outreach efforts, and predict customer behavior. With this system in place, each department can use personalized insights according to their needs:
Sales Dashboards: Enhancing Retention and Revenue
- Churn Risk Prediction: Customers aged 46 and older have a significantly higher churn rate of 76.8%, compared to 48.1% for younger users. These older customers also make 1.33 times more support calls but still face greater churn risk. To counteract churn, sales teams should focus on older customers, offering personalized retention offers like longer contract terms or loyalty incentives. ClicData alerts enable the sales team to target these high-risk customers early by analyzing their usage patterns and supporting interactions.
- Upselling & Expansion: Customers using core products without premium features are prime candidates for upselling. ClicData can help identify customers actively using basic products but not upgrading to premium offerings. Sales teams can then engage them with promotions or trials to increase both revenue and retention by encouraging them to move to higher-tier subscriptions.
- Contract Renewal Tracking: Monthly subscribers tend to churn at a higher rate than those on quarterly or annual plans. Using churn risk data, sales teams can focus on monthly subscribers whose contracts are nearing expiration. Offering incentives like discounts or added features can encourage these customers to opt for longer-term commitments, reducing churn and increasing lifetime value.
Marketing Dashboards: Data-Driven Engagement
- Churn Risk by Segmentation: Customers who reduce usage by 30% over two billing cycles are more likely to churn, particularly those on monthly contracts or those experiencing payment delays. Marketing can segment customers based on these usage drops and contract types, creating automated, personalized re-engagement campaigns. Offering loyalty rewards, payment flexibility, or tutorials can boost customer engagement and lower churn risk.
- Campaign Performance Tracking: Retention campaigns aimed at customers with payment delays show higher success when offering flexible payment options. Marketing teams can analyze campaign performance using dashboards and adjust messaging to emphasize flexible payment plans or grace periods. This approach can improve customer retention for those facing financial challenges, enhancing both loyalty and lifetime value.
- Engagement vs. Churn: Customers with low engagement (e.g., email open rates under 15%) are twice as likely to churn. Marketing teams can use Reverse ETL alerts to pinpoint low-engagement customers and promptly send targeted content like feature tutorials, exclusive offers, or reminder emails to rekindle engagement and prevent churn.
Customer Success Dashboards: Proactive Support and Retention
- At-Risk Customer Alerts: Customers who make four or more support calls within a billing cycle are at a higher risk of churn. With real-time alerts, customer success teams can quickly identify these customers and provide immediate, personalized support. Offering dedicated agents or VIP service tiers can resolve issues more efficiently and prevent churn.
- Customer Satisfaction Tracking: Older customers tend to make more support calls but still show higher dissatisfaction, which increases churn risk. The customer success team should prioritize outreach to older customers with personalized retention strategies like VIP service or tailored check-ins. Proactive service addressing their concerns can turn dissatisfied customers into loyal advocates, significantly lowering churn rates.
- Retention Metrics & Engagement Trends: Customers who delay payments by over 13 days or show a 30% decline in engagement are more likely to churn. These high-risk customers can be flagged using Reverse ETL for targeted outreach. Offering special promotions, product demos, or flexible payment options can encourage these customers to remain active, improving overall engagement and retention.
Key Considerations for Implementing Reverse ETL with Data Stream
To make the process smooth and effective, several key factors must be addressed when implementing Reverse ETL with ClicData’s Data Stream. These factors focus on data quality, security, and ensuring everything works well across systems.
Data Governance
Good data governance ensures that the data flowing to operational tools is accurate and consistent. With ClicData, automated workflows help maintain data quality and meet compliance standards like GDPR or CCPA. Data validation rules and ongoing monitoring help ensure that the data from your data warehouse to your operational tools is reliable and usable.
Latency vs. Batch Processing
Determining how often to update data is crucial. For some cases, real-time data syncs are necessary, such as tracking churn risks for customer success teams. However, batch processing might work better for other data types, like sales forecasting. ClicData allows you to use both real-time and scheduled syncs, letting you prioritize the most important data while optimizing resources.
Security and Access Control
Security is vital when moving data between systems. ClicData uses role-based access control (RBAC) to ensure that only authorized users can access or modify sensitive information. Access can be segmented by department or job function to limit who can see and change the data. Encryption during data transmission ensures that sensitive information remains protected throughout the process.
Tech Stack Integration
Reverse ETL requires smooth integration between your data warehouse and business applications. ClicData simplifies this process by supporting many databases, APIs, and tools.
Conclusion: Why Data Analysts Should Use ClicData
As businesses rely on data for faster decision-making, real-time insights into operational tools are key. ClicData simplifies this process, removing the need for manual workflows and complex integrations.
Using ClicData, data analysts can ensure that data is always available when needed, whether in real time or through scheduled updates. This allows teams to respond quickly to changes, engage at-risk customers, and improve decision-making. This way, analysts can bridge the gap between data storage and action, driving better results for the business and its customers.Try ClicData’s today and take your data-driven decision-making to the next level.

