Between 2021 and 2023, the world generated half of all existing data! As we are creating more and more data, companies are now exploiting it and tend be as data-driven as possible.
However, most of the time their data is inconsistent, incomplete, duplicated, or even erroneous making it unusable for analytics. This is why data cleaning is a crucial step in the data management and analytics process.
We’ll start by defining the principles of data cleaning to explore the five steps you and your organization should take to improve the quality of your data.
What’s the impact of bad data on your business
As much as data integration and data visualization are important steps in your analytics project, data cleaning might just be the most critical one. Data cleaning is about fixing incorrect, incomplete, duplicate or otherwise erroneous data in a data set.
Data cleaning is actually more than a step you take, it’s an iterative requires continuous adjustments as your teams consume the data, or as the data eco-system evolves. It’s a process.
Without any data cleaning process implemented, the data in use can achieve the exact opposite of the expected outcome: providing inaccurate results causing erroneous analysis, biased conclusions or ultimately bad decisions.
Let’s just take 2 very simple and common examples of the impact of bad data on your business:
Case 1: Data teams’s time is wasted on fixing bad data entry
Bad data entry will cost an enormous amount of time to data teams responsible to clean it as they the errors occur. This is a necessary step, but could be prevented with a clear and simple data entry process. Data teams would then focus on where they actually bring value: data analysis and insight discovery!
Case 2: Making decisions on incomplete or not representative datasets
The whole purpose of data analysis is to avoid gut-based decisions and assumptions, right? But including incomplete or small datasets in your analysis will biaise your conclusions and decisions.
Let’s just take a concrete example. Your services team conducted a customer satisfaction survey to reveal the NPS but only collected 100 customer feedback. This is too small of a dataset, not representative of how the product or services is perceived by the customer community. You can’t – and should not – draw any conclusion nor take any action based on this data.
These two examples alone should tip the balance towards defining and deploying quickly clear and simple processes to ensure the quality of the data and finally provide accurate analysis to business users.
5 steps to improve your data cleaning process
Step 1 – Ensuring data accuracy
Is the data accurate and reliable? You need to check for errors, inconsistencies and discrepancies in your datasets. For example:
- Your CRM dataset includes City and your Shipping system gives you ZIP Codes,
- Or you have duplicated and inconsistent data from manual entry.

In this example, ZIPCODE’s format must be 5 numbers only. So, you can’t have both ZIP Codes and City in the same cell. You need to split the values into two distinct columns to make the dataset ready for analytics.
Then, check for duplicates to be removed like in this example on the left. This type of inconsistency can occur when data comes from multiple systems or when data is manually entered. In such situations, you need to set rules to define which system is the right source.
Step 2 – Identifying incomplete data
One of the most common examples is missing data in your CRM. Typically, you’d need at least the prospects name, email address, and phone number to be able to follow up with them. Any missing values or blank fields that should contain data is a missed opportunity for your sales team. This would reveal that some critical fields in your data entry forms are not mandatory.
Let’s just take an example of a customer data with basic information: Customer ID, ZIPCODE and CITY.
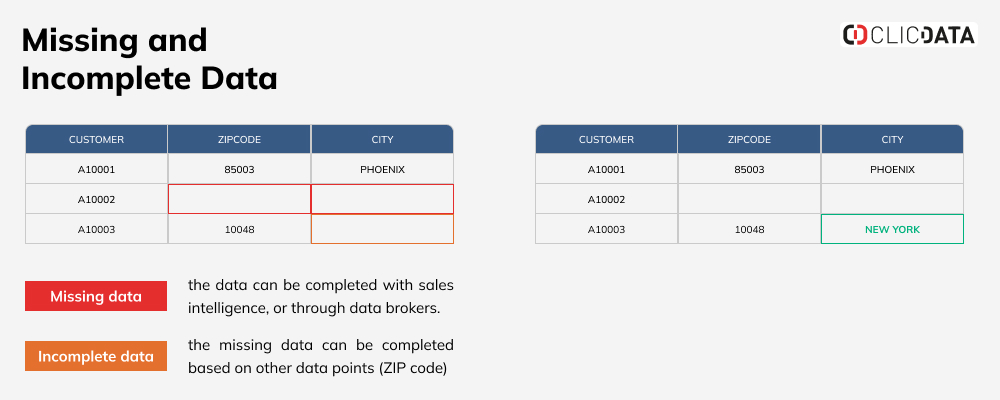
We have no information about the location of Customer A10002 so your sales and marketing teams would not be able to include them in any kind of segmented campaigns. The information could be uncovered with some additional legwork: qualification from the sales team, a call center or even data vendors.
Customer A10003 is missing the City but it can easily be recovered based on the ZIPCODE value.
This is only applicable when your datasets are missing only a few data points that could easily and quickly be filled. On the other hand, if your datasets has more wholes than Swiss cheese, you have a much bigger issue. The data is not usable for any kind of analysis or at least, reliable analysis!
Step 3 – Always making your data consistent!
Data consistency, or data standardisation, is the process of ensuring the uniformity the information coming from multiple systems.
The most common value that needs to be cleaned and standardised is the DATE field. No one and no system seem to agree on one standard date format.
- 01/13/2023
- 01-13-2023
- 13/01/2023
- 13-01-2023
- 13-Jan-2023
- …
You get the picture.
It gets worse if you deal with different units of measurement – kilometers, meters, for those who use the metric system… Then throw in a mix of currencies and you got yourself a winning combo!
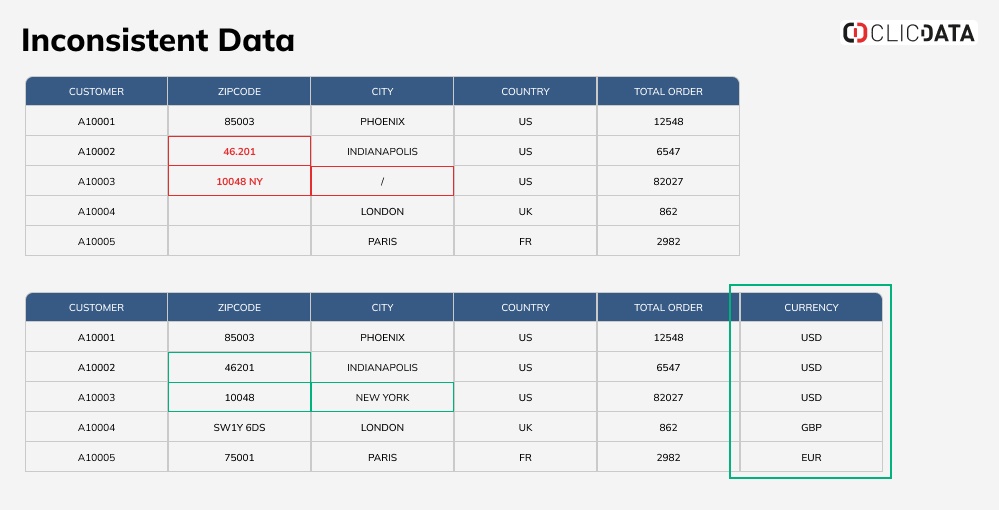
In this example we cleaned up the ZIPCODES and City based on the rules established earlier, but one issue remains. The format of the data in TOTAL ORDER seems to be correct but one information is missing – the currency. If data is used without any additional information, a sum could be done to get the total oders. But the results would just be wrong as it would mix amounts in USD, GBP and EUR. The solution here is to add a new CURRENCY column based on the COUNTRY values. Then, currency and change rate could be taken into account in the calculation.
Pro tip: In order to keep your data consistent at all times, you need to define format rules and apply it across all systems. If the data is manually entered, you need to educate your business users on the importance and the business impact of consistent data entry and make the process as simple as possible. You could also implement a format validation process as an insurance.
Step 4 – Keep your data fresh!
Keeping your data up-to-date is a cornerstone of efficient data analytics and business operations.
Imagine the impact of outdated data on an eCommerce shop parcel deliverability ratio, or the impact on inventory management if the product stock is not updated in real-time on their website.
That is mostly caused by a lack of data refresh automation or the tools are disconnected.
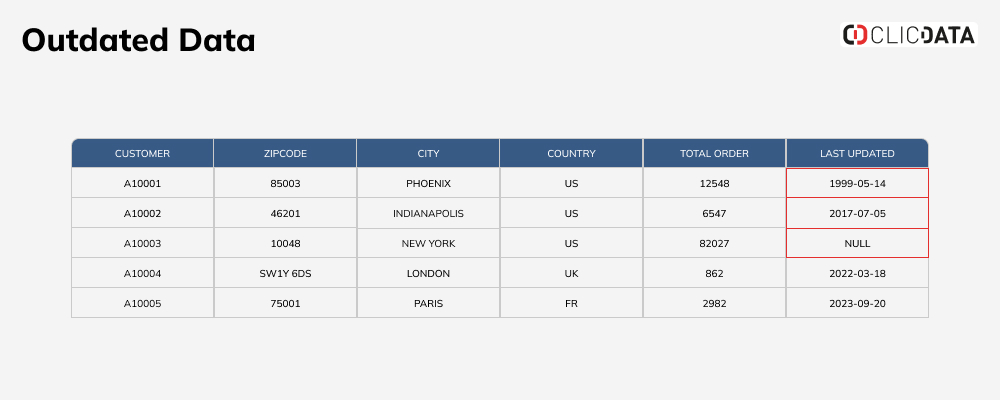
In this example, the data seems to be outdated, especially, if emails are sent to those customers. The risk here is to get a majority of IASP. You could set up alerts when customer critical information is aging to increase deliverability. For reporting purposes, you should connect your data source directly to your data analytics platform and automate the data refresh on a weekly or monthly basis depending on the business needs.
Step 5 – Your data is only useful if it’s accessible by the stakeholders
Business data tends to sit in the tools and some of which are not accessible by key stakeholders for a variety of reasons: working in silos, they don’t have the right permissions, they don’t know where the data is in the analytics tool, or just because historical data is no longer available in business tools.
That slows down the data analysis and ultimately the decision-making process.
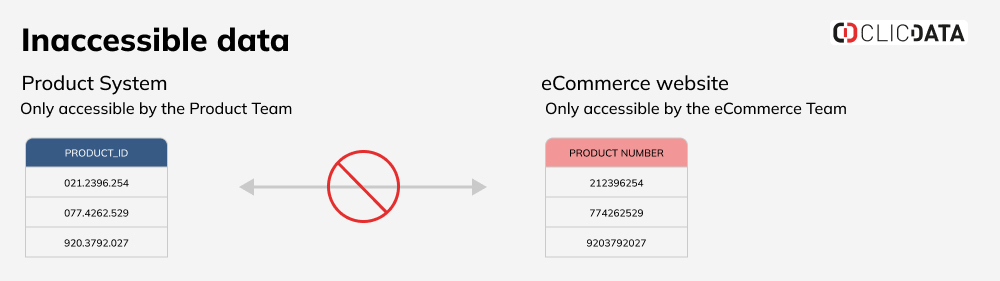
In this example, we have a very common situation. You have product IDs in two different systems, your product database and your eCommerce website. The first one is managed by the Product team, whereas the website where the order details (product, price, quantity sold, etc.) sits is managed by the eCommerce team.
In this scenario, the data is siloed which means that none of our teams will be able to combine data to monitor sales by product for example. The only way to proceed is to get someone who has access to both systems and run the analysis.
But you’re now facing another challenge: the data is not formatted the same way in each system. A layer of data standardization is required here on one of the datasets to match the other format and allow analysis.
In this case, the easiest and quickest data cleaning option is to get rid of the “.” character from the product system dataset and transform the data to a number format to delete 0 if on the left. Now you’re all set to deliver clean data to your teams!
Your Data Is Clean As a Whistle!
Evaluating data for accuracy, completeness, consistency, timeliness, and accessibility is like embarking on a treasure hunt. It’s the crucial first step that helps you uncover and root out any incorrect data before diving into the exciting data-cleaning process.
But that’s not all! As you assess your data, you’ll start to notice intriguing patterns that can be your secret weapon against future inconsistencies. Imagine having the power to streamline your data collection process and reduce those pesky issues – it’s a game-changer.
And here’s the grand finale: by diligently following these steps, you’re not just cleaning data; you’re elevating its quality to new heights. With high-quality data in your arsenal, you can confidently wield it to obtain precise and meaningful results, setting the stage for data-driven success.

