No-ETL processes have gained popularity in recent years, especially in the context of big data and cloud computing.
What is Zero-ETL?
The idea behind Zero-ETL is to eliminate the need for traditional ETL processes by processing data in place, where it already resides, without the need for separate ETL tools, systems, or processes.
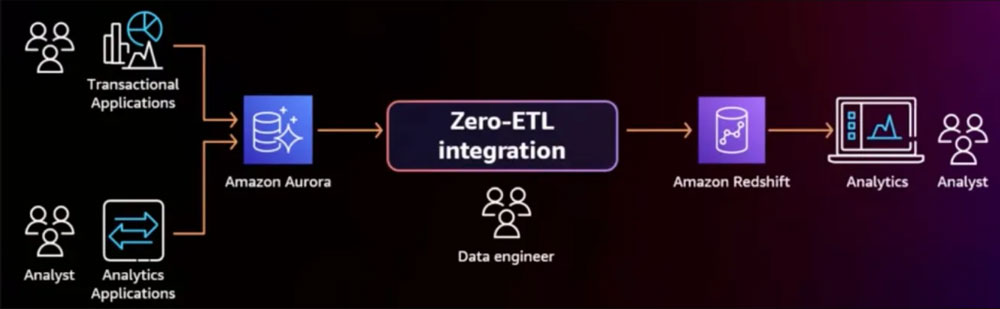
Without any intermediate procedures to alter or clean the data, data flows directly from one system to another in a zero-ETL arrangement. This method can be helpful when it’s necessary to move data between systems fast and effectively without the need for sophisticated data transformation or modification.
A zero-ETL tool is another name for a data replication tool. A replication tool will transport data almost instantly without the need for any processing or manipulation in between.
Wait before you drop out your ETL process
While the concept of Zero-ETL may sound appealing, there are several reasons why it may not always work effectively. Here are some of the key reasons:
1. Lack of standardization
Data is often stored in different formats across various source systems, which makes it difficult to implement a standardized Zero-ETL solution that can handle all data sources.
If you have a large number of disparate data sources, the cost of integrating them into a Zero-ETL solution may be higher than with an ETL approach.
2. Inability to handle complex transformations
Zero-ETL solutions often rely on in-place processing, which can be limiting when it comes to complex data transformations or combining data from different sources. Traditional ETL processes are more flexible in handling complex transformations, such as aggregating data, cleansing data, or merging data from different sources.
The complexity of the data integration process can also impact the cost of a Zero-ETL solution. If the data sources are highly complex or have different data structures, it may require more development and maintenance resources to build and maintain a Zero-ETL solution.
3. Performance and scalability issue
Zero-ETL solutions can suffer from performance issues when processing large volumes of data, especially if the data resides in disparate systems or sources. Traditional ETL processes can optimize performance by using data integration tools that can partition data, run transformations in parallel, and use caching techniques.
A Zero-ETL solution must be able to scale to handle increasing data volumes and user demands. This may require additional investment in hardware, software, and infrastructure.
4. Lack of data quality control
Without ETL processes, it can be challenging to ensure data quality and integrity. Traditional ETL processes can perform data quality checks, such as validating data types, enforcing referential integrity, and identifying missing values.
5. Security concerns
Zero-ETL solutions can pose security risks by exposing sensitive data across different systems or networks. Traditional ETL processes can help ensure data security by encrypting data during transit and at rest, controlling access to data sources, and implementing audit trails.
6. Skillset to build and maintain the Zero-ETL solution
Zero-ETL solutions often require specialized skills and expertise in areas such as data streaming, real-time analytics, and distributed systems. The cost of hiring or training staff with these skills can also impact the total cost of a Zero-ETL solution.
Is Zero-ETL Really The Right Solution For Your Organization?
While the Zero-ETL approach may appeal in certain scenarios, it may not always be the best solution. Traditional ETL processes provide a more standardized, reliable, and scalable way of processing and transforming data, and are more suitable for complex data transformations, data quality control, and security concerns.
Overall, while a Zero-ETL solution may save costs in terms of data storage and processing, it may require higher upfront investment in terms of development, infrastructure, and skilled resources.

