All modern predictive models involving machine learning rely on statistical algorithms. Statistical techniques capture patterns within data which form the basis of data modeling and predictive analysis. Some of the basic patterns include mean, variance, and standard deviations. These statistical measures capture data distribution and allow machine-learning models to forecast unseen values.
Let’s explore why statistics matters in machine learning with a real-world example of sales forecasting in retail.
Introduction to Statistics for Machine Learning
Statistics provides the basis for data analysis and predictive modeling in machine learning. Let’s understand statistics and its importance in detail.
Defining Statistics and Its Importance in Machine Learning
Statistics acts as a compass, helping us handle and manipulate vast amounts of data. It involves techniques for data summarization and analysis, and inferring meaningful insights. These techniques aid in understanding data well, predicting outcomes, and making informed decisions based on reliable predictions.
Statistics help machine learning models detect patterns from data and learn significant features. They turn any type of data into a numerical representation that’s easy to quantify and holds meaningful insights.
Understanding the Synergy between Statistics and Machine Learning
Like strategic decisions depend on current scenarios in chess, reliable machine learning predictions also depend on its training data. However, in machine learning, statistics forms the foundation of strategic decisions (predictions), defining the rules for predictive outcomes.
Both statistics and machine learning share the common goal of extracting valuable insights from raw data. The foundation of building effective machine learning algorithms depends on your understanding of statistical principles and your ability to analyze trends and hidden patterns in your data. Statistical frameworks provide the foundation for modeling relationships and understanding uncertainty.
The Difference Between Probability and Statistics For Machine Learning
Although these two fields are interrelated and often used interchangeably, they have distinct roles and applications. Below are the differences between the two:
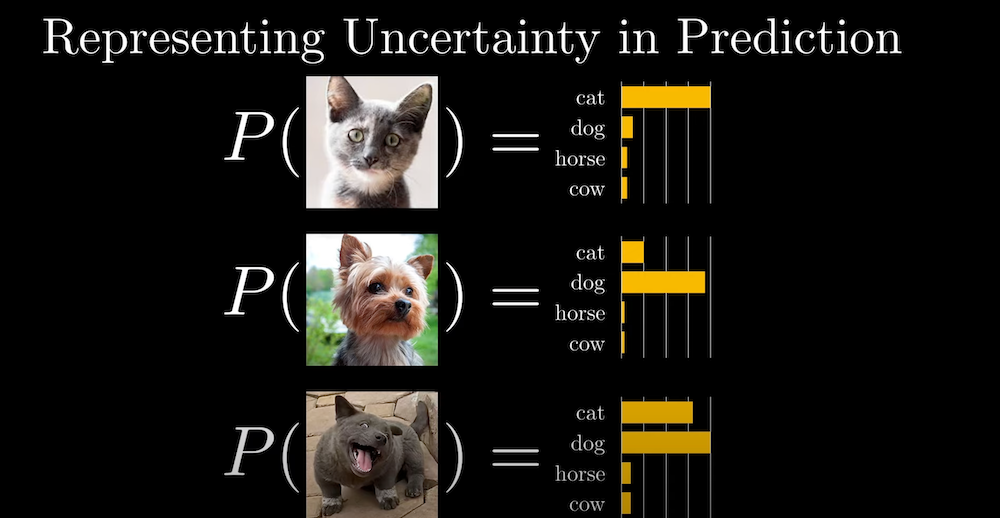
Probability is the branch of mathematics that deals with the likelihood of different outcomes. It provides a theoretical framework for quantifying uncertainty and predicting future events based on known conditions. Machine learning models such as Bayesian networks and probabilistic graphical models use probability to make predictions.
A strong understanding of probability helps understand model uncertainty and the logic behind the model’s decision-making. For instance, in classification tasks, probability helps determine the likelihood that a given input belongs to a particular class.

On the other hand, statistics involves data collection, analysis, interpretation, and presentation. It uses data to infer properties of an underlying distribution, often focusing on estimating population parameters based on sample data.
In machine learning, statistics is essential for understanding data distributions, testing hypotheses, and evaluating model performance.
Statistical methods, such as hypothesis testing, regression analysis, and variance analysis, help data analysts validate models, ensure they are not overfitting, and interpret the significance of the results.
Both probability and statistics are crucial pillars of machine learning. While probability helps understand and implement predictive models, statistics is useful for evaluating and interpreting model predictions and performance. Mastery in both fields enables you to develop robust, reliable machine-learning models that effectively handle uncertainty and provide actionable insights.
The Role of Descriptive and Inferential Statistics in ML
Statistics for machine learning is divided into two broad categories: descriptive statistics and inferential statistics. These categories use a variety of techniques. Let’s explore them in detail below:
What are Descriptive Statistics for Machine Learning
Developing an effective machine learning pipeline requires a thorough data analysis before building machine learning models. Descriptive statistics offers a set of methods to summarize and describe important data characteristics. These characteristics provide a comprehensive summary of distribution, dispersion, and variability. Here’s how descriptive statistics summarizes data:

Distributions: Normal Distribution, Skewness, Kurtosis
Data distribution significantly impacts machine learning performance. Understanding data distribution allows for picking the right statistical tests, identifying outliers, and visualizing data. The concepts of data distribution include:
- Normal distribution: This represents that 68% of data values fall within one standard deviation away from the mean.
- Skewness: It represents the symmetry in a dataset. A skewness of 0 represents normal distribution and positive or negative values indicate skewed data.
- Kurtosis: This indicates whether a dataset has extreme (tailed) values.
Central Tendency Measures: Mean, Median, Mode
Central tendency measures provide insights into a dataset’s average, most common, or central value. These measures include Mean, Median, and Mode, which are the building blocks of descriptive statistics in machine learning. Here’s what central tendency measures represent:
- Mean is an average calculated by summing all values in a dataset and dividing by the number of values.
- Median refers to the middlemost value in a sorted list of numbers. It divides the dataset into two equal halves.
- Mode is the most repeated value in a dataset, representing the most common occurrence or the peak of the distribution.
Variability Measures: Variance, Standard Deviation, Range, Interquartile Range
Variability measures define how spread out or how far values are from a central point. The variability measures include:
- Range displays the difference between your smallest and largest observations.
- Variance demonstrates how far the data points are from their mean.
- Standard deviation is the square root of variance. It represents the average distance of data points from the mean.
- Interquartile range reveals the range of the middle half of the dataset. This exposes statistical outliers that negatively impact our dataset.
When to use Descriptive Statistics in a Machine Learning Project
Descriptive statistics uncovers data distribution, variance, and other insights during the early stages of ML projects. These insights guide toward suitable data preprocessing techniques and feature engineering.
What are Inferential Statistics for Machine Learning

Inferential statistics uses data samples to make inferences or conclusions about a larger population. Here’s how inferential statistics is used in machine learning to draw conclusions from datasets:
Statistical Hypothesis Testing for Inferential Statistics
Statistical hypotheses help statisticians assess whether their theories and assumptions about data are correct before they start building machine learning models.
Correlations and Regression Testing for Inferential Statistics
Correlation and regression testing involves measuring relationships between variables. Though correlation doesn’t imply causation, it describes the strength of the relationship between variables.
When to use Inferential Statistics in a Machine Learning Project
Inferential statistics is used throughout the machine learning cycle. It is used to test assumptions in the beginning before building the model, interpret results during model building, and assess model performance during model evaluation.
Example of Descriptive and Inferential Statistics in Exploratory Data Analysis
Suppose you’re a supply chain manager responsible for improving your company’s inventory management and increasing sales by predicting future opportunities. Here’s how statistics helps achieve this:
Goal: Improve inventory management and enhance sales strategies by predicting future sales.
Approach: Predict the next 12 months’ sales.
Statistical series: Historical sales (in dollars or units) per month.
Forecasting sales for the next 12 months leads to better inventory management and refined sales strategies. It involves analyzing historical sales data using both descriptive and inferential statistics to build a reliable prediction model.
Using Descriptive Statistics
Here’s how central tendency, variability, and distribution are measured using descriptive statistics:
Measure of Central Tendency
Mean sales per month serve as a reference point for future expectations. For example, if the mean sales over the past three years is $50000 per month, the business can establish a benchmark around it to track sales performance.
Moreover, the median sales value represents the middle point of the sales data. For example, if median sales are $48,000, the company had sales below $48,000 during the month’s half and more than $48,000 in the other half of the month. This gives a balanced view of typical sales performance.
Additionally, mode or the most repeated sales value indicates a typical sales pattern. For example, the mode of $45,000 represents the most common monthly sales figures.
Assess Variability
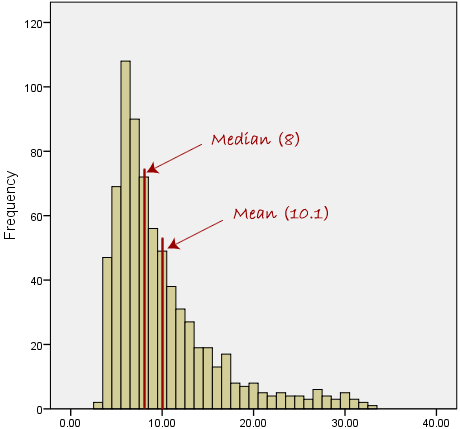
The variability of sales data represents the fluctuations in the sales data around the mean. For example, a standard deviation of $5,000 indicates that monthly sales typically vary within $5,000 of the average, providing a sense of consistency or volatility in sales.
Measuring the range and quartiles of sales data reveals more insights and further enhances data understanding. The range, which is the difference between the highest and lowest sales, along with the interquartile range that captures the central 50% of sales data, helps identify the spread and central tendency of sales figures.
Analyze the Shape of Distribution
Analyzing the shape of the sales distribution through skewness and kurtosis provides additional insights. Positive skewness might indicate occasional very high sales months, while high kurtosis suggests more outliers, possibly due to seasonal peaks or promotions. Conversely, low kurtosis implies more uniform sales without extreme variations.
Using Inferential Statistics
Inferential statistics come into play when making predictions or inferences about future sales based on sample data. In training a machine learning model, historical sales data are divided into training and test samples, where training data is used to train the model and the test sample is used for model evaluation.
Use Estimation and Confidence Intervals
Estimating parameters and calculating confidence intervals help assess the uncertainty around these estimates. For example, removing some data points to test the model’s ability to generalize on unseen data and using the average values to ensure the model accurately reflects original data patterns.
Compare Populations with Hypothesis Testing
Hypothesis testing is useful in model evaluation. Comparison tests, like Analysis of Variance (ANOVA), compare sales data from different seasons to determine whether sales fluctuate across seasons.
For example, if the test shows that summer sales are significantly higher, the model might need seasonal adjustments to account for these variations.
- Correlation tests like the chi-square test can explore relationships between variables like promotional events and average basket size. If a significant correlation is found, it indicates that promotions effectively boost sales.
- Regression analysis helps understand how changes in external factors, such as the impact of temperature or price adjustments on sales, affect sales. For example, a linear regression might reveal that an increase in temperature correlates with higher sales, suggesting that warm weather drives more customer traffic.
These insights help businesses fine-tune their sales strategies and optimize inventory management, ensuring they are prepared for the upcoming months.
You can create robust sales forecasting models by combining descriptive statistics to summarize historical sales data and inferential statistics to make predictions and validate models. This approach enables the business to make informed decisions, enhancing inventory management and sales strategies in a competitive retail environment.
Key Challenges in Applying Statistics to Machine Learning
Incorporating statistics into machine learning improves your ability to make informed decisions. However, it is important to consider potential pitfalls associated with statistical machine learning. The two major pitfalls of integrating statistics and machine learning include overfitting/underfitting models and managing the bias and variance.
Discussing Overfitting and Underfitting
Overfitting usually occurs when a simple dataset trains a complex model. The model learns the data a little too well, so it cannot understand anything beyond the training set. An overfitted model performs well on training data but fails to generalize to unseen data because it learns specific data details instead of data patterns.
On the other hand, underfitting occurs when a model is too simple to capture the underlying structure of the data. An under-fitted model performs poorly on training and unseen data because it lacks the complexity required to understand patterns within the dataset.
Let’s understand these concepts further:
- Overfitting: It’s like teaching a child only about apples – their shape, size, color, etc.- to learn about ‘fruits’. Now, if you present them with an orange or banana, they’ll likely be unable to correctly identify these new fruits because their understanding is limited to apples.
- Underfitting: Conversely, if you were too vague in your fruit lesson – simply saying all fruits are edible items without distinguishing characteristics – your child would struggle to differentiate between an apple, an orange, or even a potato.
Thus, managing overfitting and underfitting remains pivotal in balancing precision and generalizability in ML models.
The Bias-Variance Tradeoff
Bias and variance contribute to a model’s overall prediction error. Bias refers to an error in assumptions made by a model when making predictions. A high-bias model is too simple to capture the underlying patterns in the data, leading to inaccurate predictions. However, a complex model can capture intricate data patterns, reducing bias.
Contrarily, variance indicates how much your model’s predictions would alter if trained on a different dataset. High-variance models tend to fit too closely to their training data, leading to overfitting, which means they perform well on training data but generalize poorly to new data.
Making a model complex reduces bias by increasing variance, which increases the risk of overfitting. On the other hand, simplifying your model to reduce variance can result in high bias and underfitting. Therefore, balancing the bias and variance in a machine learning model is crucial for efficient performance.
The blend of various disciplines in machine learning introduces numerous challenges, but acknowledging them beforehand and taking necessary actions results in effective models.
Wrapping Up
Statistics and machine learning form the core of developing, interpreting, and validating machine learning models. Therefore, concepts like hypothesis testing, time series analysis, linear regression, and correlation are necessary for a solid grasp of machine learning.
For example, building a machine learning model is insufficient to predict the next 12 months’ sales. It requires a strong understanding of statistical methods to ensure accuracy and reliability.
For instance, hypothesis testing helps us verify that predictions are not due to random chance. The ability to interpret results is equally important. For example, p-value and effectively communicating data insights to stakeholders provide clear and understandable explanations for our conclusions.
Time series analysis is another critical tool. It allows for identifying trends and patterns over time, i.e., peak sales periods, which are vital for accurate sales forecasting. Linear regression reveals the relationships between different variables, such as how seasonal changes or promotional events impact sales.
Understanding correlation indicates how different factors depend on each other, potentially uncovering causal relationships.
Therefore, mastering mathematical and statistical foundations is crucial. They uncover hidden insights from data and help us develop reliable machine-learning models.
