How can you turn raw feedback into actionable insights?
In a world flooded with tweets, reviews, and comments, understanding how people feel about your brand, product, or service is no longer optional.
Your audience expects to be heard and understood. Sentiment analysis helps you meet this expectation by decoding emotions, identifying trends, and enabling data-backed decisions. Python’s rich ecosystem of tools and libraries makes this process seamless.
Let’s discuss how Python can empower you to transform unstructured data into meaningful intelligence. We’ll also discuss the key libraries and models and a step-by-step guide to help you implement sentiment analysis yourself.
So Which Python Libraries to you use for Sentiment Analysis?
Python offers a wide range of libraries for sentiment analysis, each designed to address specific needs. Whether you’re working on simple text evaluation or complex, context-aware analysis, these tools provide the flexibility and power required for various applications.
NLTK and VADER
NLTK is a versatile library for Natural Language Processing (NLP). Its VADER (Valence Aware Dictionary and sentiment Reasoner) model is particularly effective for analyzing short texts, like tweets, comments, or product reviews.
VADER generates compound polarity scores ranging from -1 (negative) to +1 (positive) and handles intensifiers, capitalization, and punctuation well. Moreover, it can also handle informal language like slang and emojis. This makes it a top choice for social media sentiment analysis and other real-time applications. The output of VADER’s SentimentIntensityAnalyzer() has the following four attributes:
| Output Attribute | What It Means | Range |
| neg | Proportion of text conveying negative sentiment. Higher value = stronger negative sentiment. | 0 to 1 |
| neu | Proportion of text with neutral or no emotional tone. Higher value = more neutral content. | 0 to 1 |
| pos | Proportion of text conveying positive sentiment. Higher value = stronger positive sentiment. | 0 to 1 |
| compound | Aggregated score combining all sentiment dimensions. Positive = positive sentiment; negative = negative sentiment; close to 0 = neutral. | -1 to 1 |
Transformer-Based Models (BERT and LSTM)
Transformer-based models like BERT and LSTM bring advanced capabilities to sentiment analysis. These models capture word relationships and context, which makes them ideal for large-scale, nuanced tasks. While they require significant computational power and extensive datasets, their accuracy makes them the best choice for applications such as analyzing detailed feedback or domain-specific texts.
TextBlob
TextBlob is an easy-to-use library, perfect for beginners or quick sentiment evaluations. Its .sentiment method provides polarity scores with minimal setup. TextBlob is ideal for smaller projects and straightforward tasks where ease of implementation is key.
Which Library Should You Choose?
| Framework | NLTK + VADER | Transformer-Based Models (e.g., BERT, RoBERTa) | TextBlob |
| Technology | Rule-based, uses a pre-defined lexicon and rules. | Deep learning, uses contextual embeddings and transformers. | Rule-based, relies on basic lexicon for polarity. |
| Output | Provides neg, neu, pos, and compound scores. | Predicts labels (e.g., positive/negative) or regression scores. | Provides polarity (-1 to 1) and subjectivity. |
| Context Handling | Limited, relies on predefined rules. | High, understands word relationships and sentence structure. | Limited, lacks contextual understanding. |
| Accuracy | Moderate, best for short informal text. | High, especially for nuanced and domain-specific text. | Low to moderate, suitable for simple tasks. |
| Speed | Very fast, suitable for real-time analysis. | Slower, computationally intensive. | Fast for small datasets, but slower than VADER. |
| Ease of Use | Requires basic setup and straightforward to use. | Requires substantial setup, including model fine-tuning or APIs. | Beginner-friendly, easy to integrate. |
| Customization | Limited customization of rules or lexicons. | Fully customizable; can fine-tune models for specific tasks/domains. | Minimal, no fine-tuning capabilities. |
| Resource Requirements | Low, runs efficiently on basic hardware. | High, requires GPUs or TPUs for training and often for inference. | Low, can run on basic hardware. |
| Preprocessing Needs | Minimal, handles emojis, capitalization, and slang. | Significant, requires tokenization and often preprocessing pipelines. | Minimal, but not optimized for informal language. |
| Informal Text Handling | Excellent, designed for tweets, reviews, and comments. | Moderate, depends on training data but less effective with slang. | Poor, not optimized for emojis, slang, or capitalization. |
| Scalability | Scales easily for large datasets due to speed. | Scales with distributed systems, but slower and resource-heavy. | Limited scalability, best for smaller datasets. |
| Use Cases | Real-time sentiment analysis for social media, product reviews, comments. | Domain-specific sentiment analysis for long or complex texts (e.g., legal, medical, financial documents). | Prototyping, small-scale sentiment evaluation. |
If you’re just starting, VADER is a great first step. It’s fast, interpretable, and effective for short, informal texts. For more complex needs, consider upgrading to a machine-learning model like BERT or integrating SpaCy for advanced customization. The suitable library depends on your project’s scale, complexity, and accuracy requirements.
Setting up the right environment for Sentiment Analysis
Starting a sentiment analysis project requires proper preparation and the right tools. Thanks to its simplicity and wide range of libraries, Python is the best choice for this task. Before starting, make sure you understand Python basics, including how to use lists, dictionaries, and control structures. These skills will help you handle data efficiently.
Let’s break down what you need to get started.
1. Data Handling and Preparation
- pandas: A must-have for loading and organizing text data. It helps you clean and transform large datasets with ease.
- numpy: Useful for handling numbers and arrays, especially when processing and converting text into data.
import pandas as pd
import numpy as np2. Natural Language Processing
- nltk: A popular library for working with text. It helps with tasks like breaking text into words (tokenization) and simplifying text for analysis.
import nltk
# Downloads the Maximum Entropy Named Entity Chunker model, useful for identifying entities like names or locations. nltk.download('maxent_ne_chunker_tab')
# Downloads the required lexicon data used by SentimentIntensityAnalyzer. nltk.download('vader_lexicon')
# Downloads the Punkt tokenizer, used to split text into sentences or words for preprocessing.nltk.download('punkt_tab') Pro tip: Instead of downloading nltk components one at a time, you can download all nltk modules using the command in the command line: python -m nltk.downloader all downloads all relevant all at once. However, nltk is a huge library and downloading all components at once will be very time-consuming.
Once downloaded, you must install the nltk library from your Window’s Command Prompt. Run the Command Prompt as an administrator and install nltk using the following command:
pip install nltkUsing ClicData’s Built-in Python Scripting Module
ClicData makes sentiment analysis simple with its built-in Python scripting module. This cloud-based tool is easy to set up and ready to use. Unlike traditional CPU-native setups, which often lack the configurations to handle advanced models like BERT, RoBERTa, or GPT, ClicData’s cloud-based environment is ready to use without extensive setup.
Getting started is straightforward. Create a script, use pre-installed libraries like pandas and SQLAlchemy, or add your own. This approach saves time and effort, letting you focus on writing your code. You can also automate scripts to run regularly and refresh your data to process large datasets faster.
Building a Sentiment Analysis Model with Python from Scratch
Data Collection
Collecting the right data is the first step in building a sentiment analysis model. Centralizing your data in a warehouse simplifies access and ensures version control so your dataset remains consistent and reliable over time. Here are three common ways to source data for sentiment analysis:
- API connection with Python: Use APIs to gather data directly from platforms like social media or customer review sites. If you’re new to this, check out our guide on connecting to APIs in Python.
- ClicData’s native and API connectors: With ClicData, you can quickly connect to applications or databases using 90+ native connectors or its Web Service connector. The built-in data warehouse stores and versions your data, making it easier to manage and access.
Pro Tip: Test both API and static datasets on a small scale to understand which captures sentiment more accurately.
Loading the CSV into Pandas Dataframe
Before analyzing your data, it’s important to load it into a format that allows you to easily work with large datasets. A Pandas DataFrame is ideal for this task because it organizes your data into a structured, table-like format. With Pandas, you can easily filter, group, and summarize any insights from large datasets. We will use the Product Review Data dataset from Kaggle for this example.
Use the following code to load your data:
df = pd.read_csv('D:/Product_Review_Large_Data.csv')This command reads the CSV file located at D:/Product_Review_Large_Data.csv and saves its content into a DataFrame called df. You can replace this with the file path of the CSV file on your machine. Once the data is loaded, you can apply Pandas operations to clean and process it for sentiment analysis or any other task.
Removing Null Values
Missing data, if left unchecked, can cause errors or bias in your analysis and negatively impact the performance of machine learning models. Detecting and removing null values early ensures your dataset is clean and reliable for further processing.
The following code will help you drop missing values from your DataFrame’s reviews.text column:
df = df.dropna(subset=['reviews.text'])This command removes all records that don’t have a user reviewing the reviews.text column. Or you can use our built-in ETL tools to clean up all your datasets before starting the project.
Pro Tip: Generally, removing stop words from textual data is considered a best practice as it allows you to minimize noise. However, if you’re using VADER for sentiment analysis, it’s best to keep stop words in the original text. VADER’s rule-based model allows it to extract meaningful context from stop words.
Adding Unique Identifiers to Your Dataset
The original Product Review Data dataset doesn’t have a unique identifier for each record. Working with such datasets is tricky if you have to merge datasets, filter rows, or reference specific entries down the line. To fix this, you can add a new column called reviews.id.
The new column will assign a unique number to each row that starts from 1 and increases by 1 for every record. Uniquely identifying each row will make it easy to track and manage the dataset. Once added, place the reviews.id column as the first column in your dataset.
# Generate a sequence of integers starting from 1 to the length of the DataFrame
df['reviews.id'] = range(1, len(df) + 1)
# Reorder columns to place "reviews.id" as the first column
df = df[['reviews.id'] + [col for col in df.columns if col != 'reviews.id']]Performing Exploratory Data Analysis (EDA) on Star Ratings
Reviewing the frequency of each star rating in your dataset is an essential part of Exploratory Data Analysis (EDA). This step helps you understand the distribution of sentiments represented by the star ratings.
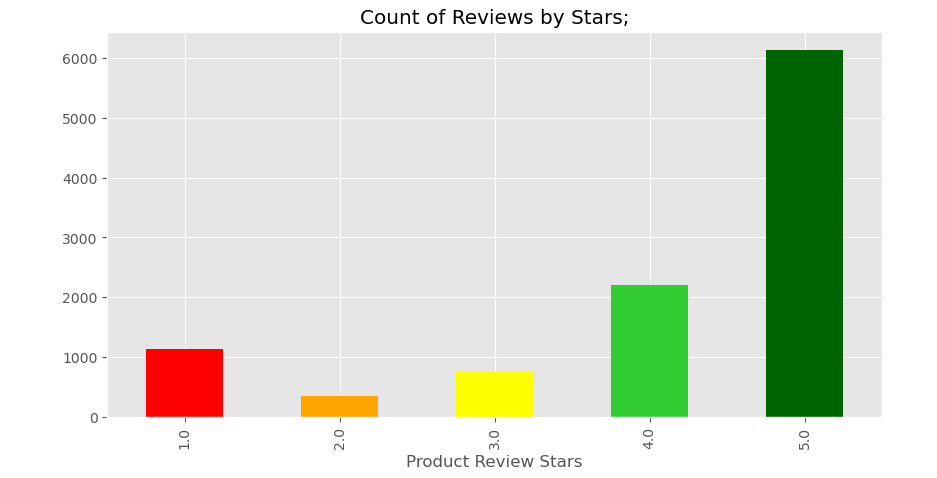
Visualizing the rating distribution makes it easier to detect underlying biases. A bar chart is especially useful for this purpose, providing a clear and intuitive view of the data. It allows you to assess ratings corresponding to every review. You can use the following code to visualize this data yourself:
colors = ['red', 'orange', 'yellow', 'limegreen', 'darkgreen' ]
ax=df['reviews.rating'].value_counts().sort_index().plot(kind='bar', title='Count of Reviews by Stars;', figsize=(10,5), color=colors)
ax.set_xlabel('Product Review Stars')
plt.show()Importing the Model (SentimentIntensityAnalyzer)
Before performing sentiment analysis, you must import SentimentIntensityAnalyzer from the NLTK library. The SentimentIntensityAnalyzer has VADER embedded by default. At the same time, libraries like tqdm can help you monitor the processing of large datasets by displaying a progress bar.
To set this up, use the following code:
from nltk.sentiment import SentimentIntensityAnalyzer
from tqdm.notebook import tqdm Analyzing Sentiment of a Sample Text
To understand how the SentimentIntensityAnalyzer from NLTK works, start by running it on a sample text. First, initialize the analyzer so it’s ready to use. Then, test it with this example: “It makes me sad that climate change is destroying the environment.” This will show you how the tool evaluates sentiment in a simple, real-world statement.
sia = SentimentIntensityAnalyzer()
sample = "It makes me sad that climate change is destroying the environment."
sia.polarity_scores(sample)The analyzer processes the text and assigns scores based on the language used. Running this analysis verifies the tool’s functionality and prepares you to confidently apply it to larger datasets. This is what the output looks like:

The results of the sentiment analysis highlight the emotional tone of the text. You’ll notice that the negative sentiment score is 0.427, meaning 42.7% of the text expresses negative emotions. On the other hand, the positive sentiment score is 0.0, which tells you that no positive sentiment is present. Finally, the compound score is -0.7717. This confirms that the overall sentiment of the text is strongly negative.
Run Polarity Score on the Entire Dataset
To analyze sentiment across your dataset; this code systematically calculates sentiment scores for each review. First, an empty dictionary called results is created to store the sentiment analysis results. The code iterates through each row in the DataFrame df using a for loop. The tqdm library allows you to see the progress of your model.
For each review, the loop extracts a unique review ID from the ‘reviews.id‘ column and saves it in the variable myID. The loop then retrieves the review text from the ‘reviews.text‘ column and assigns it to the variable text.
The SentimentIntensityAnalyzer then evaluates the review’s sentiment by calculating four scores: negative (neg), neutral (neu), positive (pos), and a compound score (compound) that summarizes the overall sentiment.
Each review’s scores are stored in the results dictionary, with the review ID as the key. This structure keeps the sentiment analysis organized, making it easy to reference specific reviews later. After completing the analysis, you’ll have a comprehensive view of sentiment trends across the entire dataset.
# Run polarity score on the entire dataset
results = {}
for i, row in tqdm(df.iterrows(), total =len(df)):
myID = row['reviews.id']
text = row['reviews.text']
results[myID] = sia.polarity_scores(text)
resultsIntegrating Sentiment Scores with Customer Ratings
To gain deeper insights, you should link sentiment scores to customer ratings. Start by converting the sentiment analysis results into a Pandas DataFrame. Then, merge this DataFrame with your original dataset to combine the sentiment metrics (neg, neu, pos, compound) with the customer ratings and review text.
vaders = pd.DataFrame(results).T
vaders = vaders.reset_index().rename(columns={'index' :'reviews.id'})
vaders = vaders.merge(df, how='left')Doing so allows you to analyze patterns in your data. For example, check if negative sentiment scores align with lower ratings or if positive scores consistently match 5-star reviews. Identifying these trends can help you better understand how customer sentiment reflects their ratings. Once merged, visualize the combined data to explore the relationship between sentiment and ratings. Merging the results will help you validate your sentiment analysis results.
Visualizing Sentiment Scores Against Customer Ratings
Part 1: Compound Score vs. Star Ratings
To start, evaluate the compound score, which provides an aggregated measure of overall sentiment on a scale from -1 (most negative) to 1 (most positive). This step helps determine whether your sentiment analysis model aligns with customer-provided star ratings. If the model is accurate, higher star ratings should correspond to more positive compound scores, and lower ratings should align with more negative scores.
To visualize this relationship, use a bar chart where the x-axis represents star ratings (1 to 5 stars), and the y-axis displays the average compound score for each rating. Here’s the code to create the visualization:
# Assessing if the sentiment analysis was correct by matching compound score vs 5 stars ratings given by customers
assess = sns.barplot(data=vaders, x= 'reviews.rating', y='compound')
assess.set_title('Compound Score by Customer 5 Star Reviews')
plt.show()Or use ClicData’s dashboard designer with over 70 drag and drop data visualizations, including the candlestick visualization as shown below if you want to spare yourself some code.
This chart highlights trends in how customer sentiment, as measured by the compound score, correlates with their numerical ratings. It provides a clear, high-level view of whether the sentiment analysis is effectively capturing overall customer sentiment.
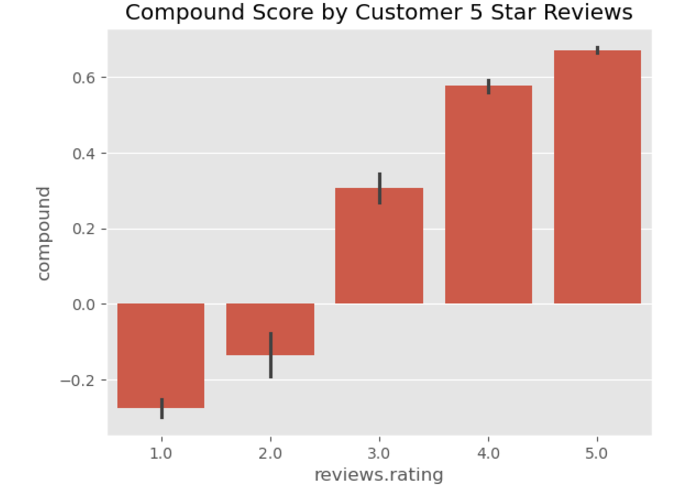
Note: Notice the black lines extending above and below each bar. These are called error bars or error lines. They visually represent the variability in sentiment scores within each star rating group.
Error bars show the range within which the true mean sentiment score will likely fall. Smaller error bars suggest that sentiment scores for a particular star rating are tightly clustered around the average. Larger error bars, on the other hand, show greater variability, and sentiment scores are more spread out. Error bars are calculated using statistical measures such as the standard deviation or standard error.
Look closely and note how the black error bars differ in size across star ratings. For 5-star ratings, the error bars are much smaller, indicating highly consistent sentiment scores that align with strongly positive reviews. For 1-star ratings, the error bars are larger. This shows that while reviews are strongly negative overall, they contain some positive or neutral terms.
VADER assesses sentiment by combining contextual rules and calculating the frequency of positive and negative terms. Therefore, if users are being sarcastic (use ‘positive’ terms to express disappointment), it might show a higher degree of variability or errors. In worst cases, sarcastic language can lead VADER to misidentify negative reviews.
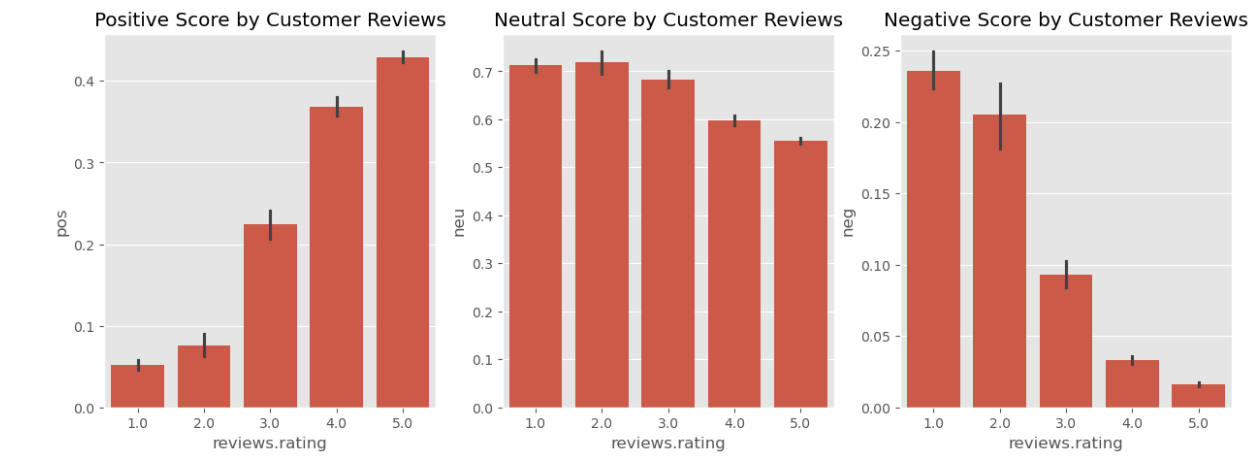
Part 2: Positive, Neutral, and Negative Scores vs. Star Ratings
Once you’ve evaluated the compound score, take a closer look at the individual sentiment dimensions: positive, neutral, and negative scores. This detailed breakdown helps you understand how specific aspects of sentiment contribute to the overall tone of reviews.
For instance, positive sentiment scores should generally increase with higher star ratings, while negative scores should rise as star ratings decrease. Neutral scores might show interesting patterns, such as peaking with middle-range ratings (e.g., 3 stars), indicating mixed feedback.
To visualize these relationships, create three side-by-side barplots. Each plot focuses on one sentiment dimension (positive, neutral, or negative) and how it varies with customer star ratings. Use the following code to generate the visualizations:
fig, assess = plt.subplots(1,3, figsize=(15,5))
sns.barplot(data=vaders, x= 'reviews.rating', y='pos', ax=assess[0])
sns.barplot(data=vaders, x= 'reviews.rating', y='neu', ax=assess[1])
sns.barplot(data=vaders, x= 'reviews.rating', y='neg', ax=assess[2])
assess[0].set_title('Positive Score by Customer Reviews')
assess[1].set_title('Neutral Score by Customer Reviews')
assess[2].set_title('Negative Score by Customer Reviews')
plt.show()Each bar plot highlights a specific sentiment dimension. The positive sentiment plot shows how positivity varies across ratings, while the neutral sentiment plot indicates how balanced or neutral feedback aligns with specific ratings. The negative sentiment plot reveals the extent of dissatisfaction expressed in lower ratings.
Get Your Customers’ Sentiment Analysis Faster with ClicData
Analyzing customer sentiment doesn’t have to be time-consuming or complex. With ClicData’s built-in Python scripting module, you can streamline the entire sentiment analysis process. This fully cloud-based platform eliminates the need for extensive setup or advanced configurations, making it a plug-and-play solution for analyzing customer feedback.
ClicData empowers you to centralize and clean your data and develop your machine learning models for sentiment analysis where your data sits. From there, transform your output into interactive charts that reveal trends over time, allowing you to focus on valuable insights instead of managing infrastructure.
Whether you’re running simple text analysis or advanced models like BERT and RoBERTa, ClicData’s environment is optimized for speed and scalability. Built-in libraries like pandas and SQLAlchemy, combined with automation tools, allow you to process large datasets efficiently. Want to see how it all works? Schedule some time with our data experts today.

