A study from Statista estimated that 328.77 million terabytes of data were created each day in 2023. Not only we’re expecting this number to grow every year, but the complexity of the data generated will also grow.
Handling such volume and complexity of data is not only a challenge for enterprise organizations. Small and mid-marketing businesses face the same challenges, but with more resources constraints.
Enters ETL pipelines. This process helps you structure the way you handle and leverage data from all sources to make decisions, without requiring a million budget.
In this article, we explain everything you need to know about ETL pipelines: what they are, what’s the difference with data pipelines, how to implement them and use cases.
What is an ETL pipeline?
Definition of ETL Pipelines
ETL stands for Extract, Transform, Load – three sequential steps used to migrate data from its source to a destination like a data warehouse or database. Essentially, an ETL pipeline refers to the set of processes executing these steps on your data.
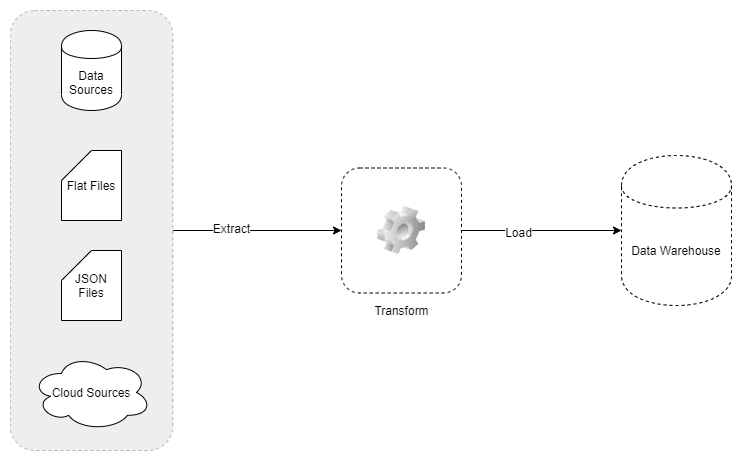
“Extract” involves gathering raw data from various sources which may include websites, servers or databases.
“Transform” is the step where the raw data then undergoes cleansing and restructuring so that it’s ready for analysis.
During the “Load” phase, we store the transformed and enriched data in secure data warehouses for later analytical use.
While it might seem simple when broken down into these components, implementing an effective ETL pipeline requires careful planning around factors such as scalability and flexibility.
Importance and Function of ETL Pipelines in Data Management
Just as highways connect smaller towns with big cities, ETL pipelines bridge critical gaps between different areas of your business by facilitating efficient flow of valuable information.
They play a crucial part in modern-day data management by enabling organizations to keep track, interpret and leverage large volumes of disparate information.
Beyond just routing lines for your data though – they help maintain accuracy and integrity while ensuring cohesive structure.
For example imagine receiving thousands of huge boxes filled with mixed items all arriving at once at your warehouse- wouldn’t it be easier if you had a system to categorize, tag and neatly arrange everything?
That’s what ETL pipelines essentially do for your data.
Organizations often opt for ETL pipelines in order to reliably feed information into their BI (Business Intelligence) tools leading to more informed decision-making. Without a well-structured ETL pipeline, the use of such data is like navigating a ship without a compass: directionless and likely to lead off course.
Understanding ETL vs. Data Pipeline
Decoding the essence of data management often centers on distinguishing between different procedures that help organize, analyze, and deliver useful insights from a plethora of information available today.
A pivotal facet of this investigation is understanding the distinction between the terms ‘ETL’ and ‘Data pipeline.’
To simply describe:
- An ETL (Extract, Transform, Load) pipeline refers to a technique for collecting data from various sources, transforming it into a format useful for analysis, then loading it into an end destination like a database or a data warehouse.
- Conversely, a data pipeline could be touted as an all-encompassing term covering any set of processes undertaken to migrate and process data from one system to another.
Key Differences Between ETL Pipelines and Data Pipelines
Initially developed to handle batch processing tasks in the ’70s and ’80s when computing resources were limited and costly, ETL has become a vital part of modern data architecture. However, as contemporary computing needs demand real-time responsiveness and scalability, it’s important to distinguish ETL from other approaches like data pipelines.
- Scope: ETL pipelines are tailored to specific business analytical needs, moving data from distinct sources to predefined destinations. For example, migrating Excel data to a relational database after cleaning it. In contrast, data pipelines are broader frameworks encompassing various pipelines (including ETL), each performing specific tasks across different device ecosystems.
- Function: ETL pipelines prioritize producing high-quality, standardized datasets with built-in validation checks to detect anomalies. Data pipelines, on the other hand, prioritize flexibility, allowing manipulation and exploration of raw, unstructured data formats without rigid constraints.
- Flexibility: When considering adaptability, ETL pipelines excel in stable environments with uniform datasets, while data pipelines thrive in dynamic settings, handling diverse Big Data workloads to enhance analytical capabilities.
Use Cases for ETL Pipelines vs. Data Pipelines
Understanding the practical applications of these differing concepts may help identify which approach is most suited to your specific requirements.
- An ETL Pipeline is a better option for data warehousing projects where transformation logic complexity escalates quickly. Various operations like joining multiple sources, handling hierarchical information and versioning records provide samples of instances where preference over ‘transform before load’ justifies its innate necessity strongly against real-time performance hits.
- A basic data pipeline example involves merely moving log data from a server into a cloud storage system for future use without undergoing any transformation during transit order – focus here primarily lies upon building robust & highly resilient systems capable of handling varying inputs effortlessly.

Exploring Different Types of ETL Pipelines
It’s essential to note that there are distinct types of ETL pipelines, predominantly, batch processing and stream processing.
1. Batch Processing in ETL Pipelines
Batch Processing involves bundling several datasets together and moving them through an ETL pipeline all at once. Often used when dealing with large volumes of historical data or instances when real-time analytics isn’t a top priority, this approach can be more cost-effective and efficient for bulky loads.
For example, if you need to transfer a customer information accumulated over the past year from one database to another, instead of moving each customer’s record individually, batch processing allows you to package them together and move all at once.
2. Stream Processing for Real-Time Data Integration
On the other hand, stream processing moves data continuously as it’s created in real-time. This form of etl/elt pipeline processing is ideal for applications that require up-to-the-minute analysis such as fraud detection or dynamic price adjustments.
Take for instance streaming video platforms like Netflix. As users interact with the service – watching movies, browsing genres – relevant data is immediately collected and analysed in real-time to make personalized movie recommendations.
Pros and Cons of Each Approach
Like most other technology approaches, both batch and stream processing come with their upsides and downsides:
Batch processing
| PROS | CONS |
| Efficiency: Optimized for handling significant volumes of data | Latency: Does not support instant access to results due to delayed processing |
| Cost-effectiveness: Uses lower computing resources compared to streaming |
Stream processing
| PROS | CONS |
| Timeliness: Supports instant decision-making due to near real-time analytics | Resource Intensive: Requires significant computing resources to run concurrent jobs |
| Accessibility: Delivers continuous insights, supporting dynamic functionalities |
At the end of the day, the right choice between batch or real-time stream processing will depend largely on your organization’s specific data requirements and goals. It’s never a one-size-fits-all solution in data management; every scenario requires its tailored data strategy.
Building Blocks of ETL Pipelines
An ETL (Extract, Transform, Load) Pipeline involves three fundamental tasks that dictate its successful implementation:
1. extraction of data from different sources,
2. transformation of this collected data for analysis and insights,
3. and loading the processed information into a target database or data warehouse.
Extracting Data from Various Sources
Extraction stands as the opening gambit in ETL Pipeline construction—it involves pulling raw data from disparate and often incompatible sources such as databases, APIs, CSV files, or web applications. Working with more than two data sources – heck, even with two spreadsheets – is challenging to ensure consistency while concurrently dealing with varying formats.
During this stage, it’s important to set precise schedules for extracting refreshes to maintain up-to-date datasets— whether they be incremental updates or full-scale data dumps.
The complexity hinges on understanding the optimal frequency to avoid overloading source systems yet still provide timely intelligence.
For instance, you may need food inventory data to be updated every day to reorder quickly, but you’ll need your restaurant sales numbers updated on a weekly basis. If you’re selling an enterprise software company, you’d probably need sales numbers refreshed every month.
Transforming Data for Analysis and Insights
Extraction’s done. Now, transformation. This is where your raw data undergoes several modifications to be analytics-ready: cleaning messy inputs, handling missing values and anomalies, integrating multiple resources into a single dataset, filtering unnecessary elements, reformatting data types among others.

But above all lies standardization—a key objective during this phase which can substantially enhance compatibility across diverse datasets enabling efficient consolidation.
Loading Process in ETL Pipelines
Finally comes the ‘Load’ element—where cleansed and transformed datasets find their resting place within targeted databases streamlined for facilitating immediate usage by end-users.
In executing efficient loading processes – attention zeroes onto methods pivoting around either appending new records (incremental loads), replacing existing entries (full-refresh loads), or updating modified datasets only (delta-detection). The choice between these hinges on specific project requirements and considerations about space, data availability, and timeliness of information.
Remember that the loading process has an enduring effect – a well-engineered loading phase can optimize query performance leading towards faster access to insights. The ETL pipeline’s culmination in loading forms its lasting legacy—setting the stage for your stride into effective data-driven decisions!
Benefits of Implementing ETL Pipelines
Data ETL, or Extract, Transform, Load process is a core component of an organization’s data strategy. It facilitates the movement of data from various sources into a single repository where it can be analyzed and utilized for decision-making.
Here we explore three main advantages: improved data quality and consistency, faster decision-making through timely insights, and enhanced adaptability in data management.
Improved Data Quality and Consistency
The first step in the ETL pipeline- extraction involves collating data from multiple varied sources. This raw unstructured data often contains inconsistencies which leads to skewed analysis if left unchecked. This is where the transform phase of data ETL comes to rescue.
During this phase, standardization rules are applied to ensure that all collected data follows similar formats – for instance changing date formats to match across different sources, removing unrelated information or duplicates etc.
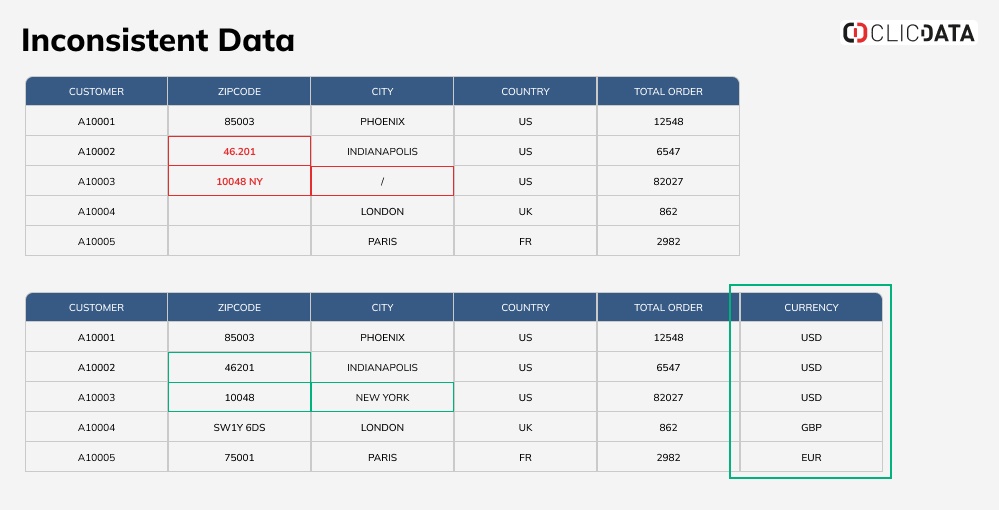
Moreover, the transformation stage allows you to refine your dataset making sure only high-quality relevant records proceed towards the final stage.
Such cleaning and streamlining exercises significantly improve overall data quality while maintaining consistency throughout your datasets. This way, you know that key trends causative factors are not obscured by outliers or errors, providing greater authenticity when drawing conclusions.
Faster Decision-Making Processes with Timely Insights
The ability to make quick, informed decisions is highly coveted in any organization. Traditional manual processes simply cannot keep up with the volume and speed required.
This is where benefit number two of implementing data ETL kicks in – efficient decision making driven by immediate access to clean coherent curated data.
Data stored within a centralized database following the completion of a full-blown pipeline implementation becomes a robust source of crucial analytical inputs. These inputs can involve identifying emerging customer trends, detecting financial anomalies, predicting sales, and more.
Enhanced Scalability and Flexibility in Data Management
Lastly, an adequately implemented ETL pipeline contributes significantly toward robust scalability flexible data management operations within organization.
As needs change evolve, businesses often grapple with increased volume complexity datasets they handle. With a hard-coded, manual approach towards handling such expansions can become labor-intensive time-consuming.
ETL pipelines provide a practical solution to this concern by offering adaptable frameworks that can efficiently manage both increased volumes of data complex processing requirements without significant drain on existing resources. Often using a cloud-based data warehouse as part of the ‘load’ stage in the ETL process allows for convenient space expansion whenever necessary.
In conjunction with scalability, these pipelines also imbue substantial flexibility into your data handling capabilities.
Challenges and Considerations in ETL Pipeline Implementation
While implementing an Extract, Transform, Load (ETL) pipeline can greatly benefit your data management, it’s not without its share of challenges. Let’s talk about the most common ones and key considerations to ensure a successful implementation.
Transitioning from ETL to ELT Approach
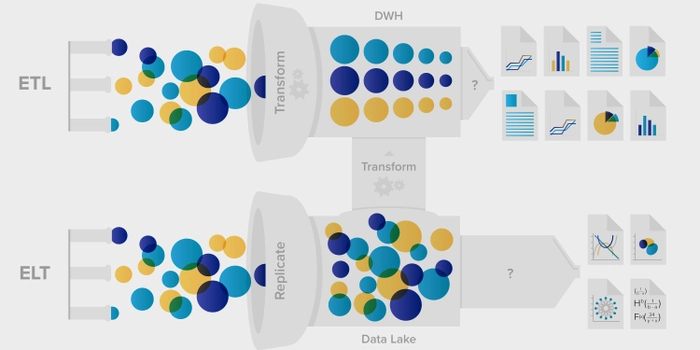
ETL pipelines focus on the extraction, transformation, and loading of data – in that order. But with the rise of big data and advancements in technology, many businesses are now transitioning towards an Extract, Load, Transform (ELT) approach. The processing happens after loading the data into the target system.
The transition can be difficult because it involves reevaluating current processes and possibly abandoning some existing ETL tools. Despite the initial resource requirements, there are benefits to moving to an ELT approach, including faster performance due to reduced data ingestion latency.
Common Pitfalls and Best Practices for Successful ETL Implementation
During the ETL pipeline implementation project, you may face these common challenges that could impact the project efficiency and effectiveness:
- Inadequate Error Handling: Without robust error handling mechanisms in place, organizations risk being blindsided when issues arise during data processing. This can lead to confusion and delays in resolving issues, impacting overall productivity.
- Deferred Maintenance Tasks: Neglecting routine maintenance tasks, such as data integrity validation, can gradually degrade the performance and reliability of ETL pipelines over time. This may result in suboptimal operations and increased risk of errors or data inconsistencies.
- Lack of Understanding Usage Patterns: Failing to comprehend usage patterns and anticipate future data demands can leave organizations ill-prepared to scale their ETL processes efficiently. This can lead to resource shortages, bottlenecks, and inadequate responsiveness to evolving business needs.
To mitigate these risks and ensure successful ETL implementation, you should consider adopting best practices such as:
- Regular Monitoring: Implementing robust monitoring mechanisms to proactively detect and address anomalies in ETL pipelines can help prevent issues from escalating and impacting operations.
- Routine Preventive Maintenance: Conducting regular preventive maintenance tasks, such as validating data integrity and optimizing performance, helps ensure the reliability and effectiveness of ETL pipelines over time.
- Understanding Usage Patterns: Investing time and effort into understanding usage patterns and forecasting future data demands enables organizations to scale their ETL processes effectively and adapt to changing requirements.
Remember: Strategic planning and proactive maintenance are key to optimizing ETL implementation and avoiding unnecessary disruptions. By staying ahead of potential issues, organizations can streamline operations and maximize the value derived from their data pipelines.
Addressing Real-Time Data Processing Needs
An increasing number of businesses need their insights timely if not real-time; therefore traditional batch-oriented ETL pipelines may fall short sometimes.
One way around this challenge is by integrating ‘stream processing’ capabilities into your pipelines for real-time data integration.
A word of caution though: Shifting from the batch processing mode you’re accustomed to, towards stream processing can be complex and labor-intensive. Especially when dealing with high-velocity streams of inbound data, maintaining accuracy while ensuring timely insights is a critical balancing act.
Nonetheless, the payoff is significant with immediate access to insights enabling quick course-corrections or capitalizing on short-lived market opportunities that otherwise might have been missed out on. Hence, addressing real-time data processing needs become an imperative.
In conclusion, implementing ETL pipelines can no doubt boost your data management capabilities immensely. However, navigating through these challenges requires strategic planning coupled with systematic execution. Remember it’s all about understanding your context – what works best for you won’t necessarily work best for others!
Real-World Use Cases of ETL Pipelines
Concrete examples illustrate the transformative impact of ETL processes and highlight their importance and practicality in real-world situations. Let me highlight a few notable cases of successful ETL pipelines implementation.
Retail & eCommerce Analytics
Consider the sector of retail and eCommerce, an industry driven by data for large scale operations. Incorporating an ETL pipeline becomes a cornerstone for gaining insights about customer behavior, shopping trends, buying patterns among other metrics.
- Individualized Customer Experiences: Ecommerce platforms extract huge volumes of structured and semi-structured data from different sources – user interactions, product views, cart logs etc. This raw data is transformed via an ETL process into actionable insights that help in curating personalized advertising strategies or tailored loyalty programs.
- Inventory Management: Retailers apply ETL pipelines to their sales data for precise inventory control. Understanding which products are trending allows them to optimize their supply chain and procurement to avoid out of stocks or overstocking.
- Fraud Detection: By extracting transactional records and applying Machine Learning algorithms during transformation phase, retailers can flag suspicious activities providing a robust security framework.
Online Review Analysis
In another spectacular implementation of ETL pipelines, consider online review platforms like Yelp or TripAdvisor; these entities processed over 1 billion of textual-based reviews in 2023.
- Sentiment Analysis: Data extraction entails pulling copious user-generated content from various digital touchpoints associated with businesses — feedbacks, reviews and comments. Following extraction, this corpus undergoes transformation involving natural language processing routines yielding sentiment scores presenting a gauge of public opinion.
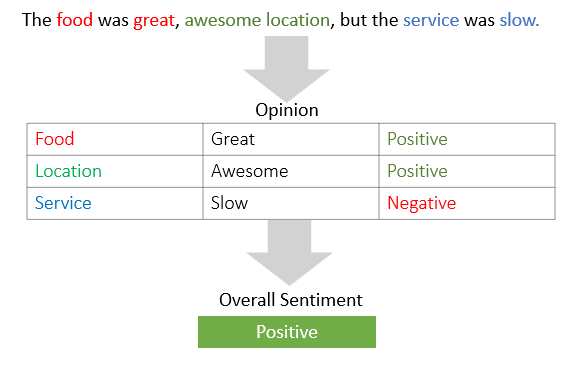
- Review Summaries: Extracted reviews are transformed using summarization algorithms into concise snapshots that encapsulate the original narrative’s primary points, aiding quick perusal.
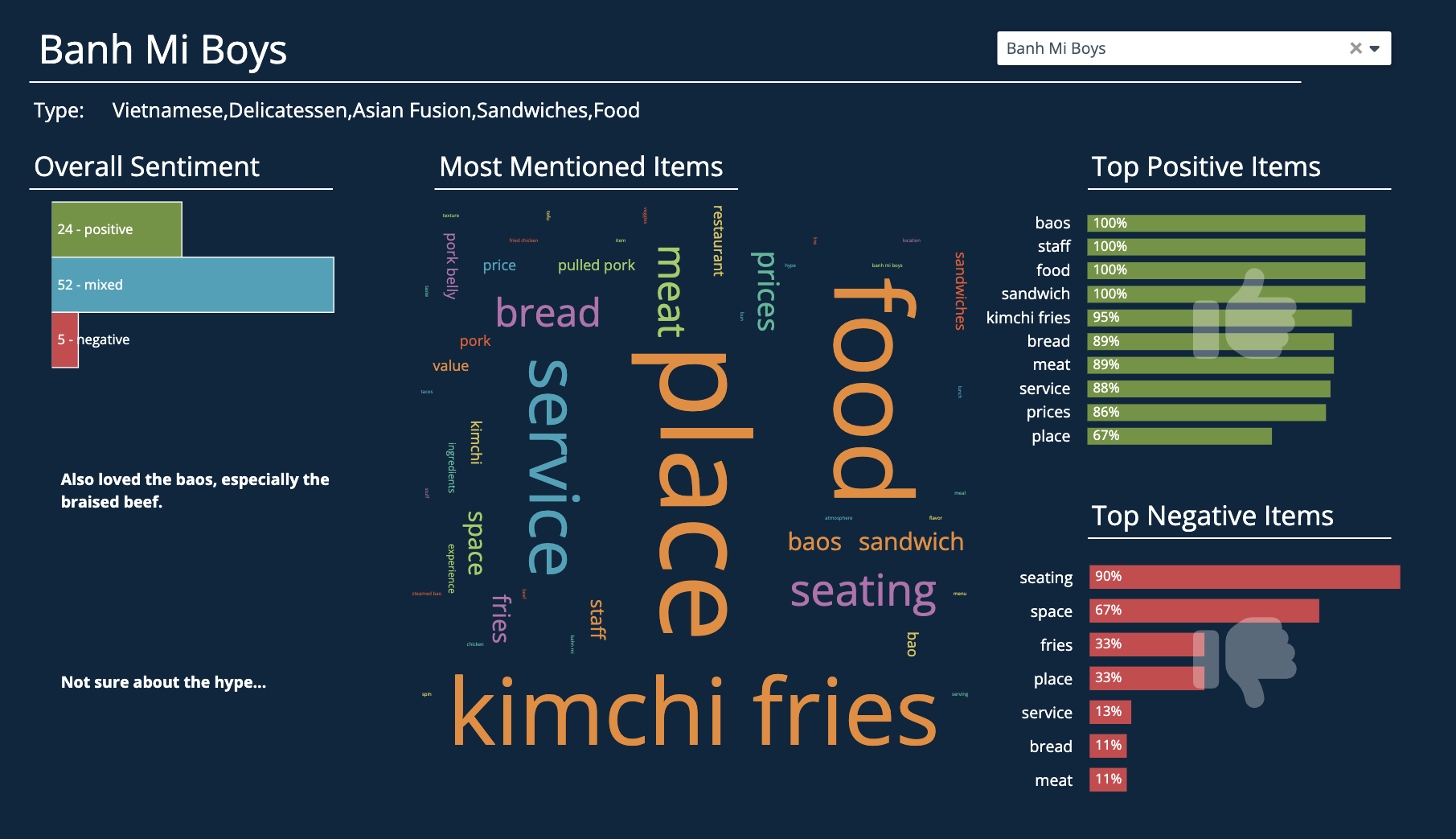
These examples demonstrate the potent advantages of utilizing ETL pipelines in harnessing the chaotic stream of raw internet chatter into valuable insights and summaries. The applications range from improving business reputations to helping consumers make informed decisions whilst browsing multiple consumer-generated reviews online.
Improve Your Data Management With An ETL Pipeline
As we wrap up our journey exploring ETL pipelines, let’s grab some key takeaways.
ETL processes play a critical role in organizing scattered data into a meaningful structure, much like sifting gold dust and turning it into pure bars – shaping our understanding of “data is the new gold”.
Now you understand the difference between traditional ETL pipelines and broader data pipelines, as well as different types of ETL operations and their strengths and weaknesses.
By efficiently implementing ETL pipelines, you can improve data quality and make faster decisions with more timely information. These systems provide the scalability and flexibility to adapt to evolving market trends. While the transition may seem daunting, understanding common pitfalls and best practices strengthens these robust infrastructures.
Reliable ETL implementations are evident in industries such as retail analytics or online review analysis, enabling smart strategies from deep data insights. So, keep the essence of this guide in mind as you pursue data success through effective ETL pipeline implementation.
FAQ
What is the difference between ETL process and ETL pipeline?
The terms ‘ETL process’ and ‘ETL pipeline’ might seem interchangeable at first, but there exists a subtle distinction between them. ‘ETL process’ refers to the three-step methodology used by businesses to blend data from multiple sources. Extraction, Transformation, and Loading (ETL) are steps within this workflow.
‘ETL pipeline’ encompasses not just the individual steps, but also how they’re organized and managed in practice. These pipelines could be simple linear constructs or rather complex systems with intricate workflows depending on your specific business requirements.
Who builds ETL pipelines?
Creating robust and efficient ETL pipelines often necessitates professionals who understand both technological complexities and business implications involved in handling data.
By default, Data Engineers tend to shoulder responsibility for constructing these processes. Their role entails designing hardware and software architectures capable of managing vast amounts of information. Data Architects share similar functions as well, crafting blueprints for databases based on organizational needs.
Nowadays, Data Analysts increasingly engage in building lighter variants of these pipelines as part of smaller projects or prototyping efforts. Preferring user-friendly tools like SQL or Python allows them to create simplistic ETL systems for quick insights without exhaustive infrastructure setup during initial stages of data exploration.
How do I document ETL/ELT pipelines?
Clear guidelines facilitate knowledge transfer and provide quick solutions during unexpected issues.
Whether using simple text files or sophisticated project management tools, your methodology matters most. Start by detailing each step, its input, and output. Define the flow of the ETL pipeline, including data progression and any transformations or filters used. Incorporate exception handling processes, explaining actions taken when conditions aren’t met.
Regularly update documentation to reflect changes and reduce confusion during future updates. Remember, robust ETL systems begin with thorough documentation!

