Here at ClicData we help our customers get up and running with their data projects and for those that have already dabbled into building their own Data Warehouse or staging areas (a database that holds data that needs to be further processed prior to being sent to the Data Warehouse) is what type of database they should be using.
Despite the fact that ClicData comes with its own Data Warehouse and staging areas all built-in, for some customers they still want to have their own database as a central point prior to synching data to their ClicData dashboards so we get to work with them and help them structure the best way to accomplish what they need.
Cost and maintenance is top of mind for many of them and as such low-cost or free database licenses such as MS SQL Express, MariaDB, MySQL, PostgreSQL and MongoDB among many others.
For those that do not want the maintenance hassle of installing and configuring the above tools, they sometimes opt to go to a Cloud provider where the choices, still at a reasonable cost, can vary but can include more powerful databases such as Cassandra, DynamoDB, Document DB, and others.
Then we have the high volume, high power customers that prefer to work with RedShift, Google BigQuery, SAP HANA, and Hive, again to name just a few.
Too many choices!
Although the list is quite large, the decision tree to identify the right database hinges on a few items making the list of available choices quite small in the end.
- Required Data Volume/Performance
- Cloud or On-Premise
- Security and Reliability
- Cost
Using the above selection list you can get your choices down to most likely 3 or so database vendors. You can start with the top or bottom, it is irrelevant however if you are not willing to spend more than $200 per month on a database then I would start with the cost because there are paid database vendors that cost less than that for any serious database work, cloud or on-premise.
If your data volume and/or performance requirements are high (more than 20GB of data), don’t expect a free solution even if you already have some available server and hardware or cloud subscription available. It requires more intense planning on disk and memory for optimization. The volume and performance are very tightly related to each other and to the hardware.
By going on-premise you are then undertaking the purchase and configuration of the hardware. Do not expect to run a large database from a laptop, it requires server sizing to determine the type of disks (HDD rpm speed or which types of SSD, RAID configuration, external or internal), all the way to the power supply and cooling of the server. This is also related to Security and Reliability. What happens if the server fails? Disks failures? Configuration and security patches? Network configuration and many other items that you must deal with to keep your data secure.
Going cloud may help some of the above items, firstly by having ready set “images” of database servers ready for use. These servers are virtual servers configured correctly to run the database of choice and at times they already have all the security settings in place, however, because they are the cloud you will certainly need access to it remotely and hence you may be opening up the doors for others to access it as well. A solid understanding of your cloud provider’s security settings is a must.
In the cloud world, there are more choices than simply picking an “image” with the database pre-installed. Some cloud providers also offer Database as a Service. This means that it is fully maintained by them, including redundancy, security, backup, and high availability. Some are capable of handling billions of rows and still perform very well albeit at a high cost.
So what is a project manager or business manager to do? Well, here is what we have seen so far…
Cost Selection
So, even though we can start with the volume and performance required, many customers look primarily at the cost to start with and unfortunately, this leads to some very bad choices.
Selecting a database on cost alone will lead to the selecting for the most part free databases. Now Free cost databases are not “Open Source” although most people tend to think of it as such. For example, Microsoft SQL Express is not “Open Source” but it is free.
Selecting a database solely on cost is not really a selection process. The same way that you do not go out buying a car to use or a house to live in at the lowest cost possible. There are minimum standards and requirements but unfortunately, this has led to the selection of databases totally inappropriate, filled with performance and security flaws or in best-case scenarios, the use of Microsoft Access for years to come (been there, done that).
Application Developer Selections
Asking the developer of the interfaces or the database administrator will lend itself to 3 possible scenarios:
- Developer/DBA will select a database vendor that she is most comfortable with, has used in the past.
- Developer/DBA will select a database vendor that he is eager to use because it is the next hot thing.
- Developer/DBA will select a database vendor that she knows the manager will accept based on cost, resources, and preference of cloud versus on-premise
In any of the above 3 cases, there is a chance to select the wrong database.
Of course, I am generalizing as there are some DBAs and Developers that will actually do the right thing, which is…
Perform a Data Requirements Analysis
Understand the current and future requirements for the business, evaluate the data growth rate, map out the type of data and storage requirements, is it transactional or analytical? Is the data sensitive in nature or public? Does the company have the necessary resources to maintain an on-premise type of database performing optimally and securely or is cloud a better choice?
The checklist of items goes on but you can start with some simple discussion points to determine where you are headed using a simple list such as:
Schema
Is the schema of each table known in advance or is it flexible in nature? Is it tied to any programming language (SQL, .NET, Node.js, etc.) and Data Modeling Languages (LINQ, etc.)
Use
Is the database going to be used for transactional (per row insert/update/delete), batch (ETL, cleansing) or Analytical (aggregate)?
Data Volume
If the data volume is substantial then larger cloud-based database as service must be selected as there are no equivalent on-premise unless you have a very large technical infrastructure and team.
Tools
Is there an ETL tool already selected and is it limited to certain types of databases?
People
Who is responsible to maintain it, secure it, configure it, develop with it. What are there skills, etc.?
Security
Does data contain sensitive data as per HIPAA or GPDR and others? What level of security is needed, encryption at rest, etc.
Safety
What backup mechanisms, frequency, and type are required (on-site, off-site), etc.
So… Do we choose SQL or NoSQL?
Irrespective of the above, one of the top questions we get is if they should be using a NoSQL type of database or a modern SQL database. Now, the question is not the right one because there is no such thing as a “SQL” database or “NoSQL” as SQL is a language that can be used on many different types of databases. But the power of “research and advisory” companies and media always simplifies complex topics to basic fad words such as “Web 2.0”, “Big Data”, “Artificial Intelligence” and of course “NoSQL”. It is then up to vendors, experts, and power users to explain to their non-technical counterparts the actual differences.
Document-based databases (referred to as NoSQL) are basically variable schema databases capable of having a table with several rows of data in which not all rows are identical in structure.
An example of this could be a table (or document) such as this:
[
{ name: "Thomas", age: 34, hobbies: [ "Guitar", "Video Games" ], place:"Lisbon" },
{ name: "Axel", age: 24, hobbies: [ "Tennis", "Soccer" ], place:"New York" },
{ name: "Max", age: 25, place: "Lille", accesscount: 13 }
]Its fixed schema counterpart looks like this:
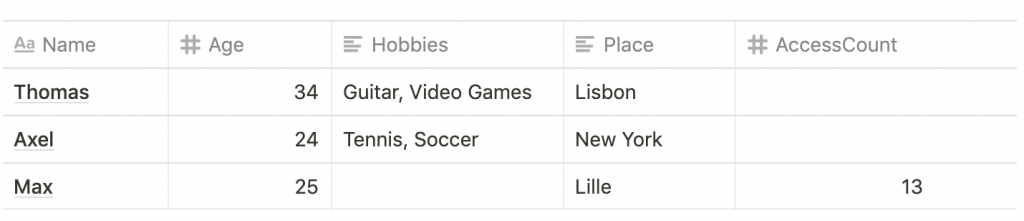
One of the key advantages of document-based databases is that I can add any column at any point in time. With this advantage comes responsibility because your database may easily become bloated with misspellings and unnecessary data just because it is possible to do this.
However, the biggest advantage to me is the concept of fields of type array that can contain multiple elements such as the “hobbies” field shown above. Notice that on its fixed schema counterpart, the multiple values Tennis and Soccer are separated by a comma but are essentially in one field. To do this properly in a fixed schema database we would need to actually create 2 tables, one containing the master data (name, age, place, access count) and the other containing the hobbies and then create a join between them.
This seems like a lot of work but depending on the case it may be better or worse and that depends on the end-use of a document database. Is it for analytics, does it change over time that frequently that a document database is needed and if it does, how often are the applications or scripts accessing those tables modified over time? Will they take advantage of the new data immediately or they need also to be re-written.
The performance of document-based databases when it comes to analysis is also not as high as fixed schema which makes sense since the use of fixed aggregated indexes or “columnar indexes” to optimize the aggregations is not really possible. So other more complex tools need to be used to tackle document databases in order to produce metrics in an optimal amount of time.
Is OLAP still around?
Yes. OLAP is still alive and well in larger organizations that can afford to have database analysis sit with users and the technical group to define dimensions, metrics, and KPIs that need to be defined ahead of time for inclusion in cubes and subsequently in reports.
The rapidity of OLAP is its biggest advantage but it needs to be defined prior to actual execution. In more recent years the use of (get ready for some more fad words) “Vertical” and ‘In Memory” databases which in essence are fixed schema databases but organized by columns instead of by rows, provide big advantages. These databases use columnar storage instead of row storage (on disk or in memory) to store the data.
The biggest advantage of using a columnar store is the fact that you do not need to define it prior to the cube model definition. However, it still will not be able to do things that OLAP does very well such as dimension and metric hierarchy, auto filtering and extreme pivoting. So there are still some clear performance advantages.
The issue of OLAP is that there are fewer OLAP databases in the market and the high cost not only of licensing but also the entire work in preparing it and delivering it.
So, what is the right database for me?
Well hopefully you figured out by now that you are not going to get an answer here but let me give you some quick examples:
You have a reasonable amount of data, no staff to maintain servers and database, and want a reasonable amount of security, your data is mostly static, well defined then go for a Cloud service hosting MySQL, SQL Server or PostgreSQL or offering them as a Database as a Service. If your data is not in a fixed schema then go for MongoDB also hosted by many cloud providers.
You have a low amount of data, have the internal experience, the data is used mostly in internal processes then go for MariaDB, SQL Server Express if it is fixed or MongoDB locally if a flexible, uncertain schema.
If you are handling millions of rows in several tables, containing sensitive data and performance and security are of concern, you should look at Azure Database if more geared towards analytics then Google BigQuery and Amazon Redshift. If of flexible schema then look at Amazon DocumentDB or Azure CosmosDB.

