Who hasn’t juggled with incomplete, poorly formatted, or error-laden data? Faced with a massive volume of data to process within tight deadlines? Or encountered a lack of data consolidation to ensure an overview and precise analysis?
Cleaning, transforming, and enriching data from various heterogeneous sources is not always simple, even for a data analyst.
This is where one of ClicData’s key features comes in, the Data Flow module. Not familiar with it yet? It allows you to manipulate any type of data as you wish. Merge, join, clean, enrich, and group your data so that it’s ready to be visualized in reports or dashboards. All this, without any required coding. Want to know how?
How Data Flows Work: A Visual and Clear Overview of Your Transformations
Yes, its name is a clue: you visually construct your flows from A to Z with Data Flow. This means that all data cleaning operations, calculations… take place in a single visual interface where each step can be easily documented and understood by all users.
Quite interesting, isn’t it?
From the input table to the output tables, create a continuous sequence of interconnected nodes that transform your data, step by step, with simple drag-and-drop. Want to see how it works with examples?
Speed Up and Optimize Your Data Processing with Data Flow
As you understand, this module can be used for various use cases. Let’s discover two examples for more efficient data processing:
1. Fill in gaps in the customer journey with unified data
Let’s put ourselves in Ravi’s shoes, a Marketing Manager wanting a better understanding of his entire customer journey across different stores.
The brand he works for has 10 physical stores and an e-commerce website.
Ravi wants to list every touchpoint for each customer to understand activities such as:
- how customers interact with the brand on social media,
- the products they search for on the website,
- those they add to their cart but don’t purchase,
- if they interact with store staff, or online via chat,
- what they purchase, etc…
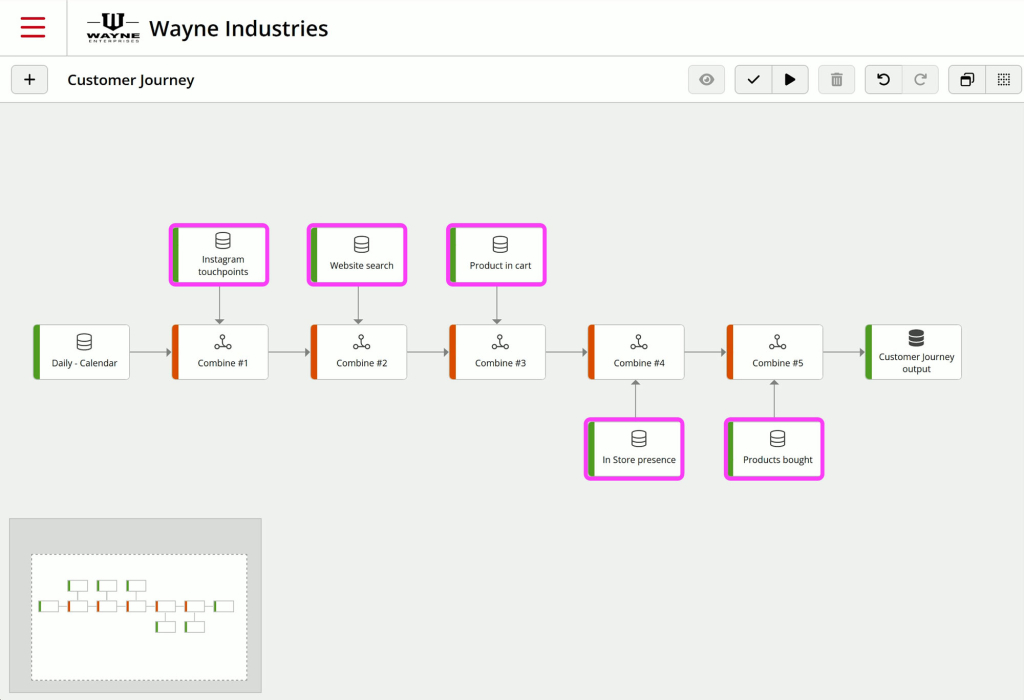
With a Data Flow aggregating data from different sources into a single output table, you now have a complete overview of every prospect and customer touchpoint of Ravi across all brand stores.
You can now use this unified data to create a dashboard so that Ravi can perform a precise analysis of the customer journey. He can also, if he wishes, add them to his CRM to deliver more relevant advertisements to his customers and prospects.
You’ve addressed Ravi’s business problem, allowing him to analyze his entire customer journey.
2. Track call center performance with enriched data
For this example, let’s step into Hanako’s shoes, a Call Center Manager wanting to track the performance of multiple call centers globally and by employee as well as compared to different targets.
To address her problem, Data Flow allows you to create a merge to link the data from the 4 tables of her ERP together, including:
- calls,
- employees,
- clients,
- and companies.
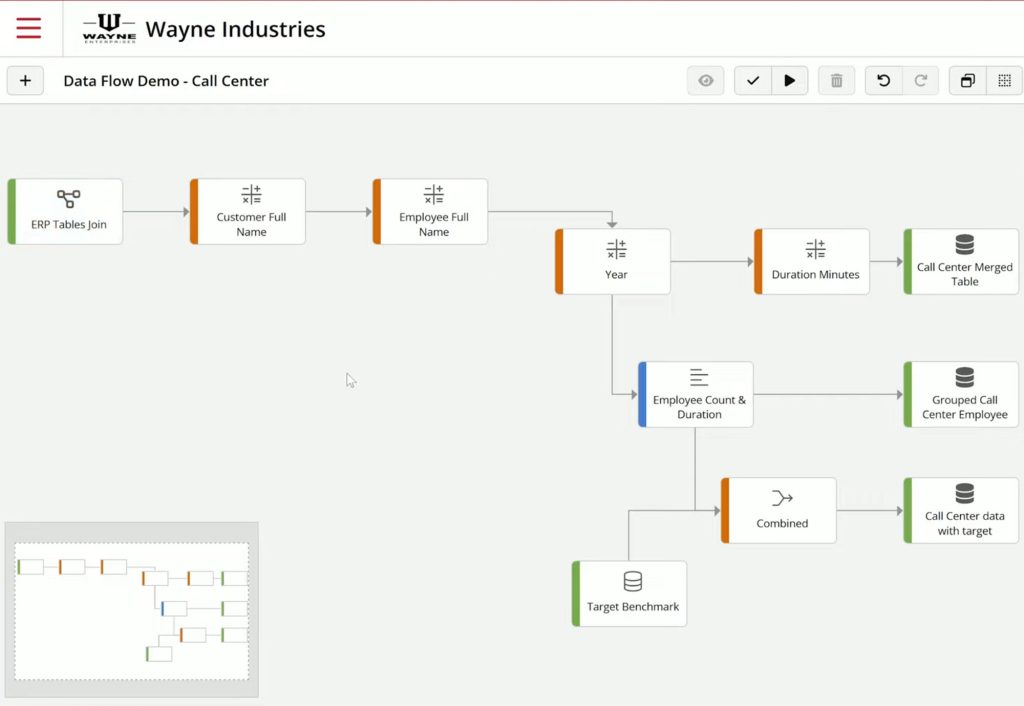
Then after some transformations to clean and add new calculated columns, you’re able to create 3 output tables displaying:
- all calls,
- calls grouped by employee,
- and performances aggregated with corresponding goals
All that’s left is to automate the processing of this Data Flow and feed this data into a dashboard, like this one:
Another business problem solved!
Hanako can now track all her KPIs, hour by hour, to measure the overall performance of her call centers against targets, individual employee performances, etc…
With Data Flow, manipulate any type of data as you wish and optimize your data processing: both simple and complex tasks.
A Complete Panel of Data Processing Tools For Endless Possibilities
Because you can create as many output tables as necessary from different input tables in a flow comprising multiple branches, you have the flexibility to simultaneously execute different transformations.
These can be done concurrently, either in parallel or in sequence, thus ensuring simultaneous updating of your data. Thus, secondary management steps like creating views, merges, or maintaining a clear naming convention are no longer necessary.
Data Flow Execution According to Your Needs
A Data Flow is executed when you want it to be executed; either on a schedule or on demand. Compared to Views/Merges and Fusions which were automatically rebuilt each time the data was refreshed. This means that you can time it to load multiple sets of data and only prepare the new data for analysis or visualization when you are ready. You decide when a table output really needs to be updated.
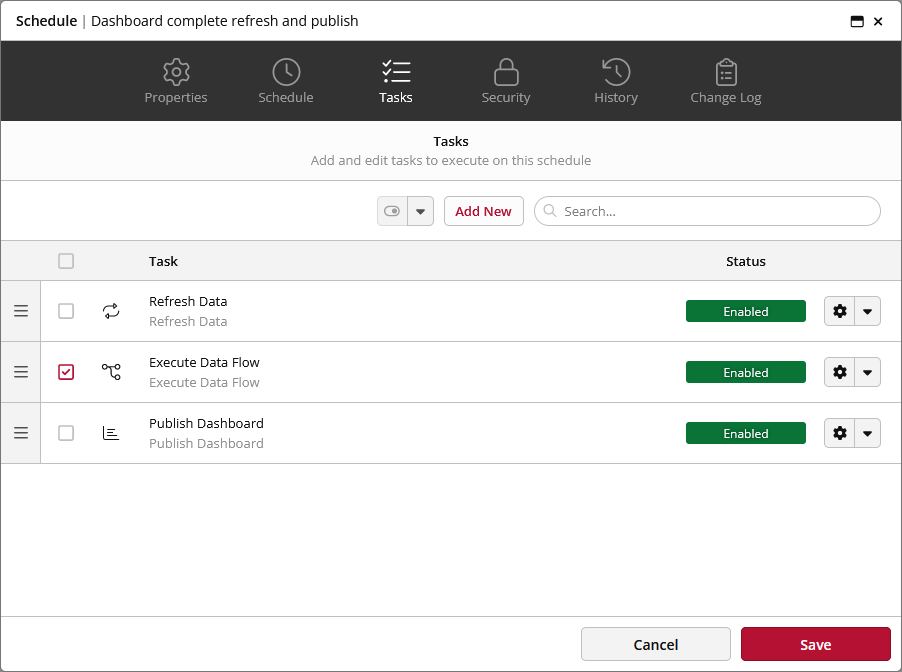
It also allows you to preview the flow prior to actually executing it, ensuring that any kinks are worked out beforehand.
Higher Performance
Data Flow can be viewed as the process of taking data from one or many physical tables, processing the data, and then putting the results in another physical table.
Unlike our views and merges and fusions that needed to be cached, data flows are always building data on tables that do not require to be re-calculated or re-processed each time we use them in dashboards, reports, or other areas of ClicData.
You don’t need to bother anymore about certain constraints and actions that previously were needed, such as cache management and dependency checking.
The nodes themselves are done using a variety of techniques including:
- Common Table Expressions (CTE),
- the automatic building of joins for faster lookups or aggregations based on a number of items,
- the use of Columnar Store Indexes,
- and more.
Logical Flow Sequences
You can organize flows one after the other so that you can build logical processing groups.
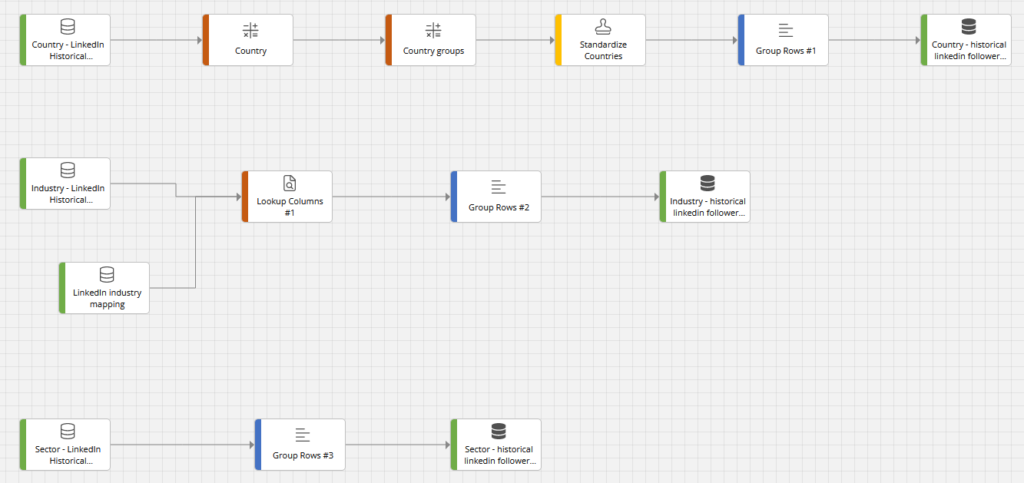
For example, you can have an initial flow that cleans the data and standardizes the output schema.
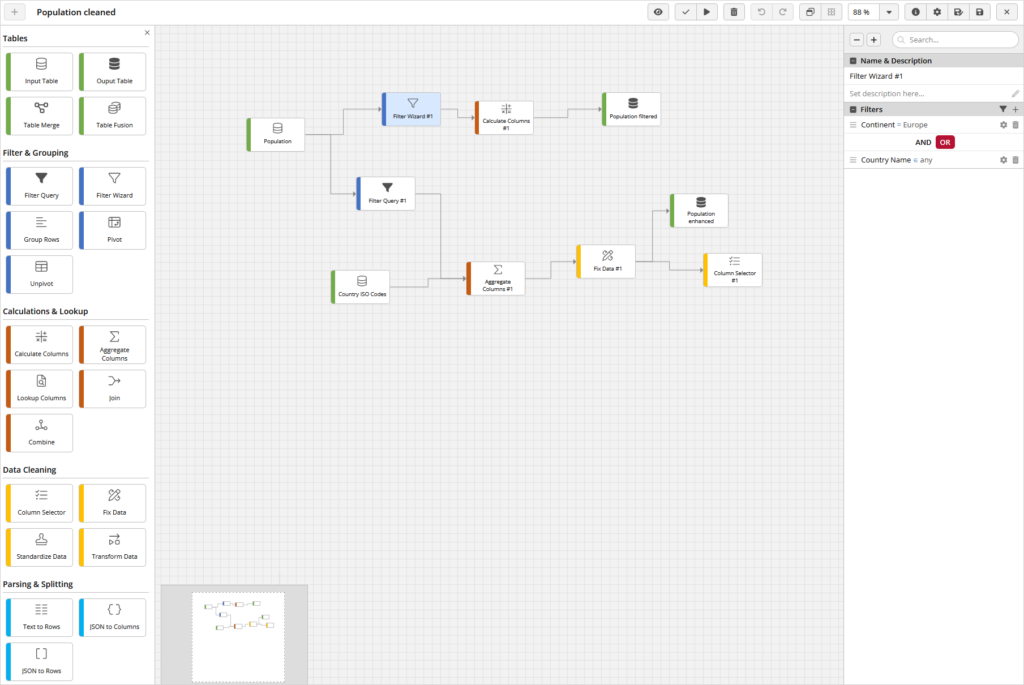
In the screenshot below we can see how historical LinkedIn metrics are prepared for further processing (we work here with monthly followers count by country, industry, and sector). This flow has been run manually only once, as it relates to historical data that won’t change any more.
After that, a second flow can use the output table to then calculate standard metrics for various reports and dashboards.
Continuing with our example, we see how live metrics are processed for the 3 dimensions of LinkedIn followers in the flow below. They are then combined with the historical outputs from the first Data Flow.
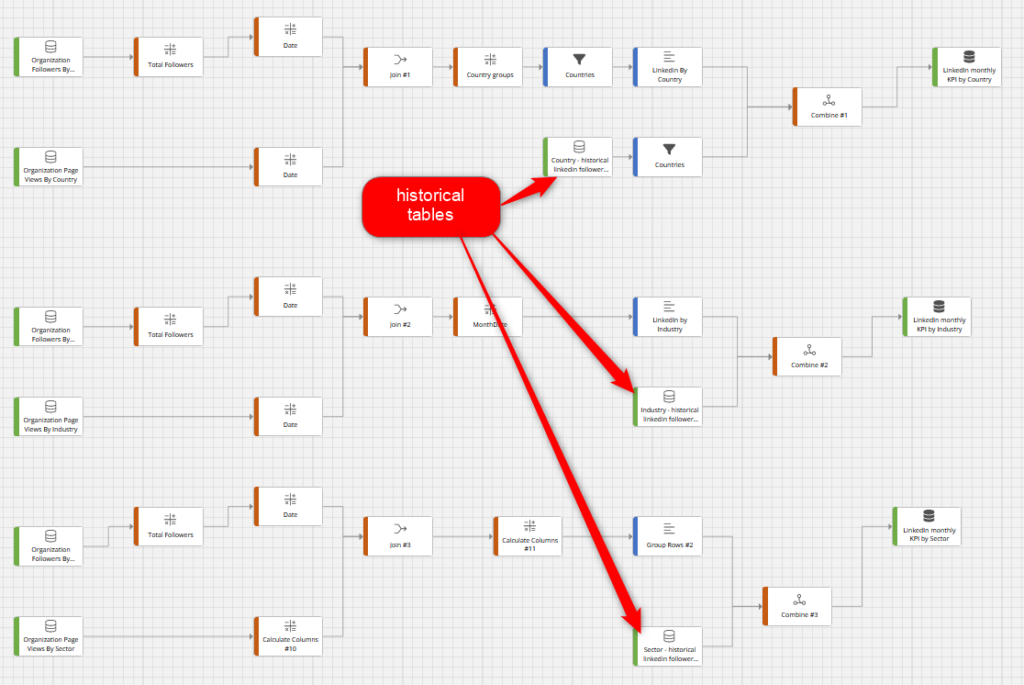
And potentially, a third flow can then select some of the previous flows to pre-group or pre-aggregate some data.
This allows to keep the processing of data clean and modular while at the same time identifying potential areas of performance improvement.
Seamless Collaboration
Because all node operations are contained in one single Data Flow, it makes it very easy to share flows with other users, make copies of entire processes and simply change the input and/or output tables.
Each node can get a specific name and description, making it easy to maintain a good understanding of the data processing, with low documentation efforts.
The same security system as with other objects in the platform applies to Data Flow: users can be editors or viewers or not have access to certain or all data flows.
Time to Embrace the Power of Data Flow
First of all, rest assured that Views, Fusions, and Merges will stay active for customers already using them for a few more years. You will have time to master flows and experience all its benefits for yourself. Eventually, Data Flow is meant to replace the former system.
Data Flow will continue to be enhanced with the next releases to add more features like new nodes, debug help, UI enhancements, and more.
Start today!
Data Flow is available to all users in ClicData. If you don’t see the access in your Main Menu under the Data section, please reach out to your admin who can give you permission. If you need help from us, don’t hesitate to reach out to our Support team.
We hope you enjoy using Data Flow as much as we do!