In Part 1 of this Blog series, we gave a brief description of Sentiment Analysis and described the challenges associated with it. If you are reading this then you are determined to continue on this adventure – good for you!
Before proceeding, please be aware that this blog is a lot more technical than Part 1, as we will guide you on how to set up a data connection to Azure Cognitive Services to process data and return to us opinions and structured sentiment.
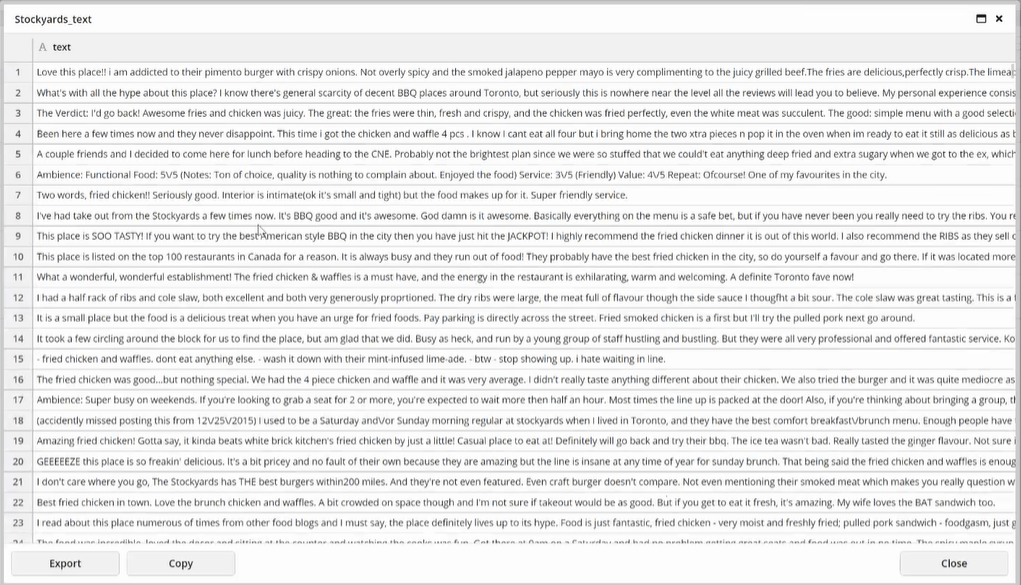
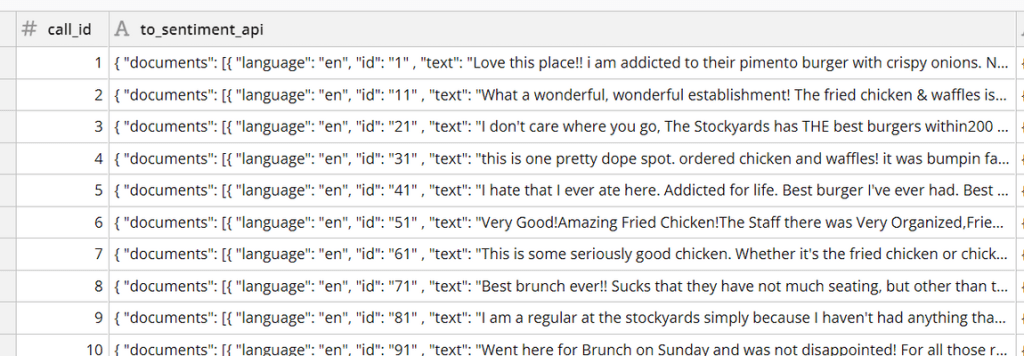
As stated in Part I, we are analyzing the overall sentiment as well as opinions of specific aspects such as the food and atmosphere of a particular restaurant from over 600 Yelp reviews. Below is a sample of the raw data:
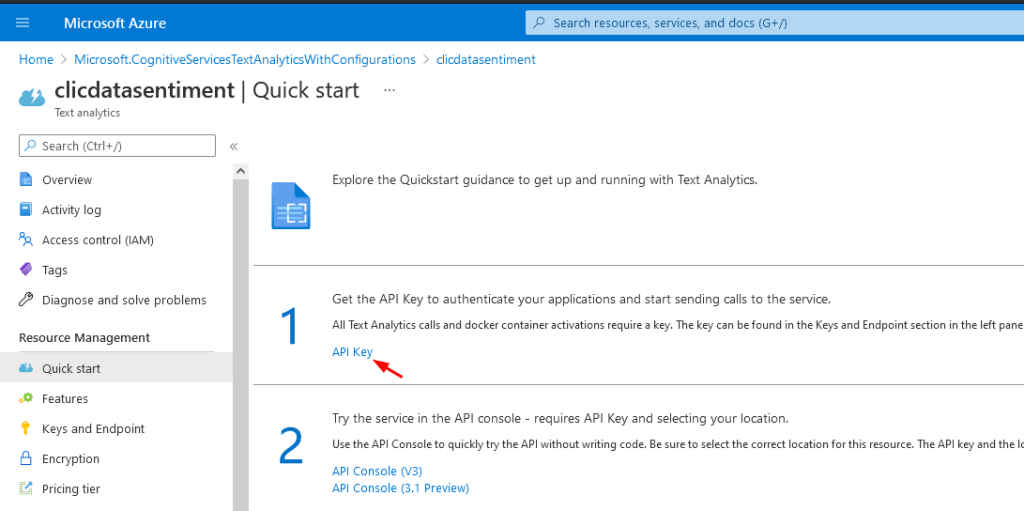
Configuring Azure Text Analytics
Please refer to the following guide to set up an Azure account and enable Text Analytics API on the Azure account. The ‘free’ tier will allow you to make 5000 API calls.
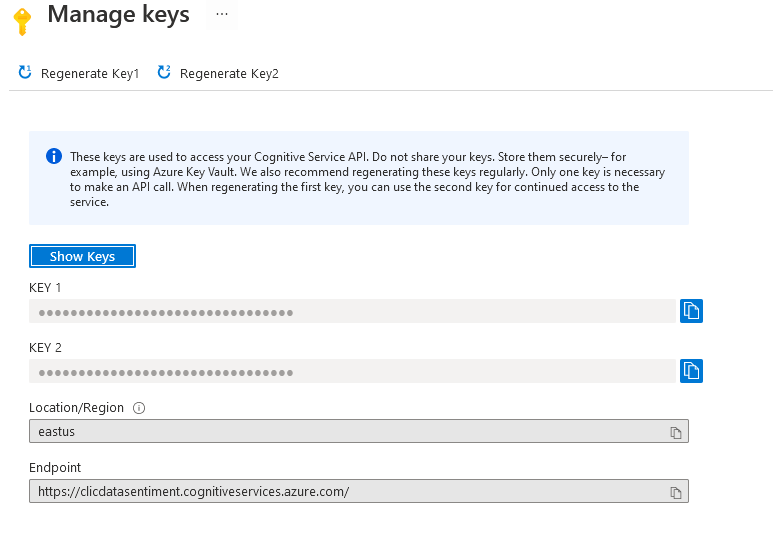
After this step, you need to obtain the endpoint domain and the secret key here:
Setting up the Connector
In ClicData, add a Webservice connector and provide the endpoint domain and secret key as shown below.
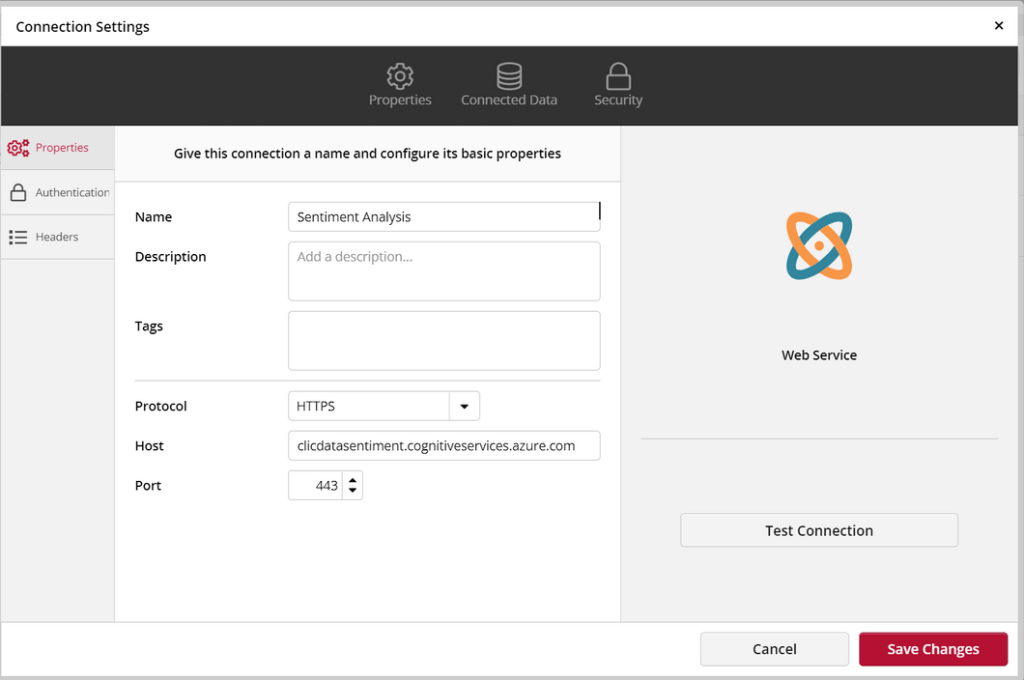
Also include the headers as indicated.
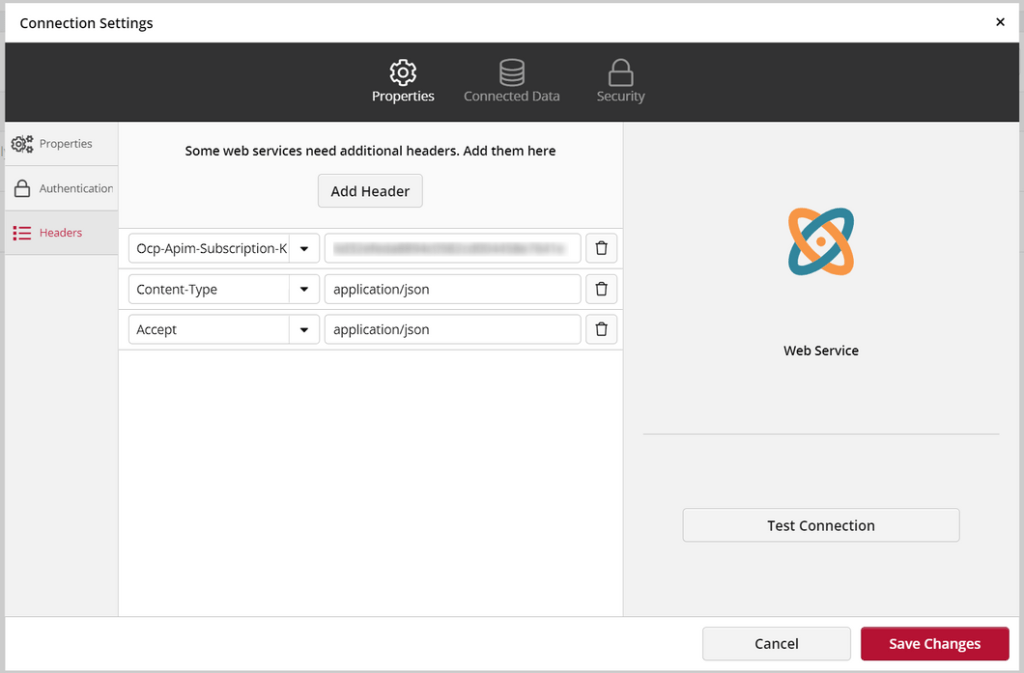
Here are the headers to use:

Transforming the Raw Text
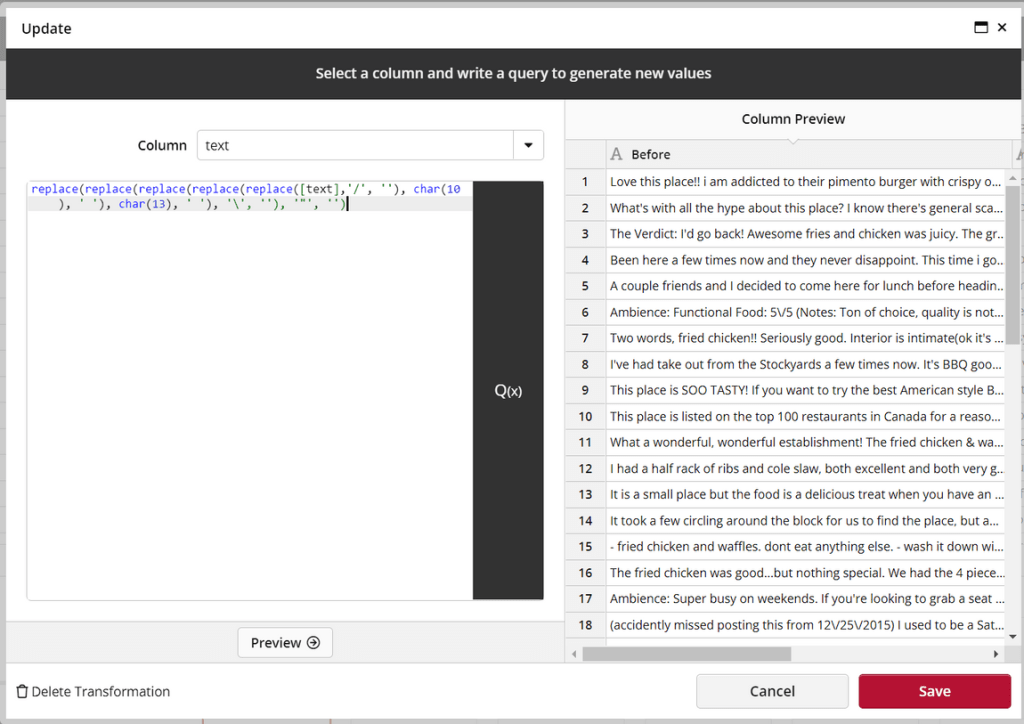
Now we need to transform the raw data to a JSON structure as discussed on Part 1. It will be helpful if we add an id to the texts before uploading the data file to ClicData.
Then we will remove artifacts in the text that may interfere with the JSON formatting such as single quotes (‘), double quote (“), back and forward slashes (/) and carriage returns.

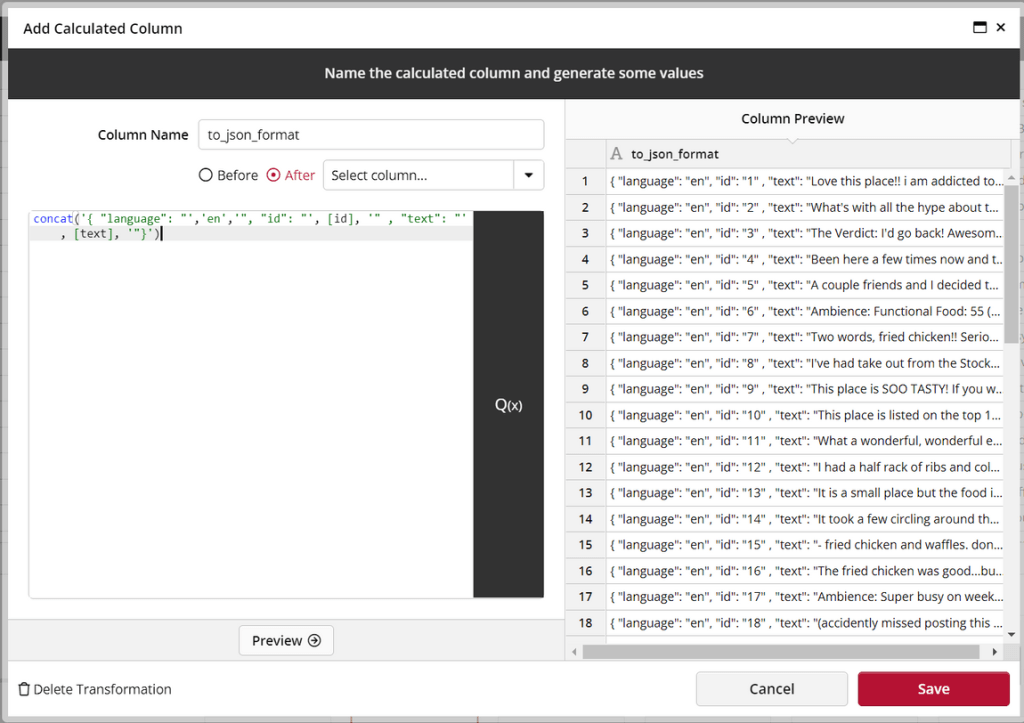
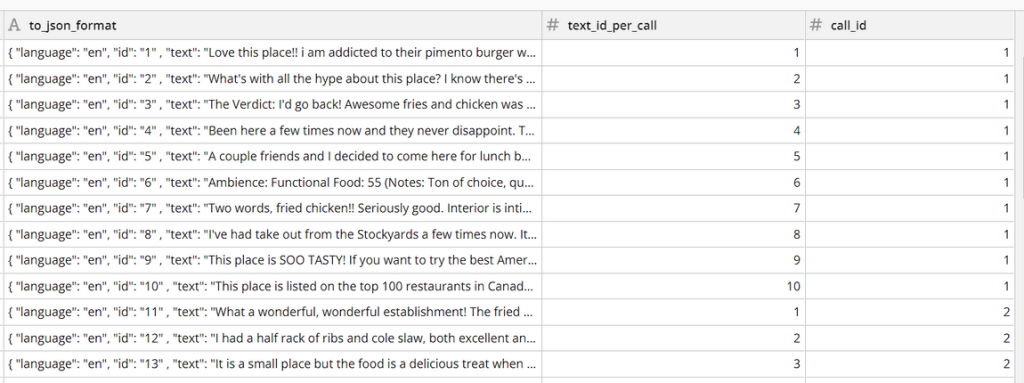
Now we create a calculated column in JSON format ready to send to the Azure Cognitive Services API. Please note that we are hardcoding the language English (en) since we know that all our text to be analyzed is in English. However you could expand on our example and use another cognitive services to detect the language before sending it.

However, as mentioned in Part I, due to the limitations of the Azure API, this data needs to be structured so that each row represents a call to the API that must contain up to 10 texts each. To do this, we are going to add two IDs, one that will have a repeating sequence of 1-10 (text_id_per_call) and another that will increment after every 10 rows (call_id).
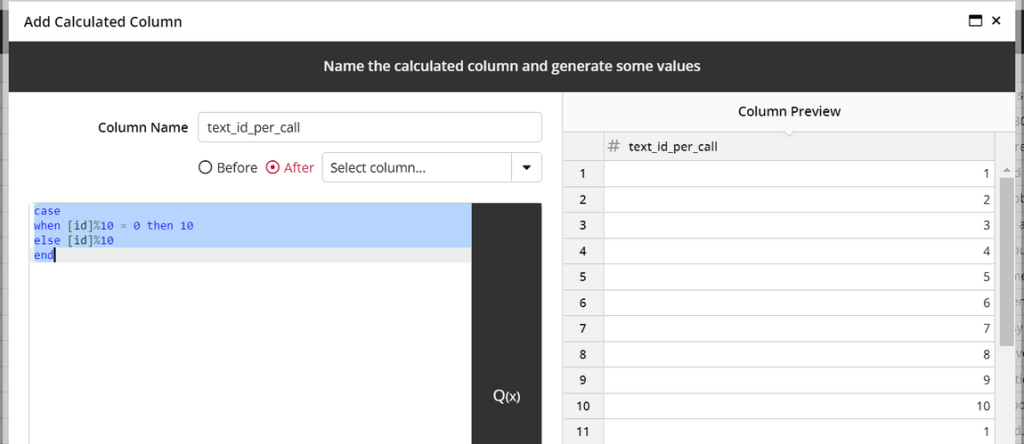

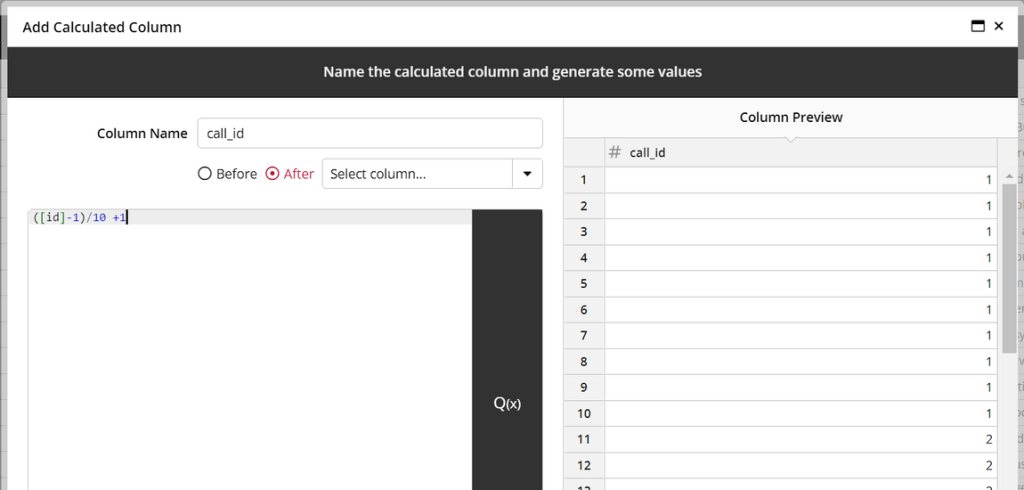

Now we will pivot the text_id_per_call column with the JSON formatted text as the pivoted value and the distinct IDs on the call_id column as the rows.
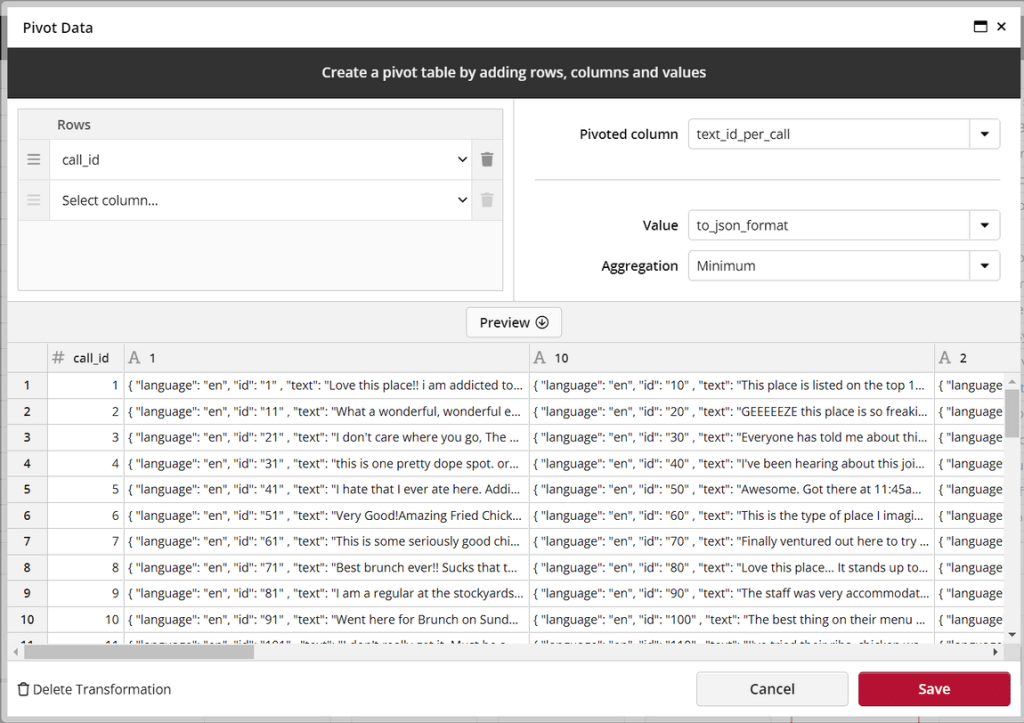
The data should now look like this.

The final step in this view is to concatenate the columns 1 through 10 in a new cell (to_sentiment_api) so that each cell containing the text contains the complete JSON structure for up to 10 texts.

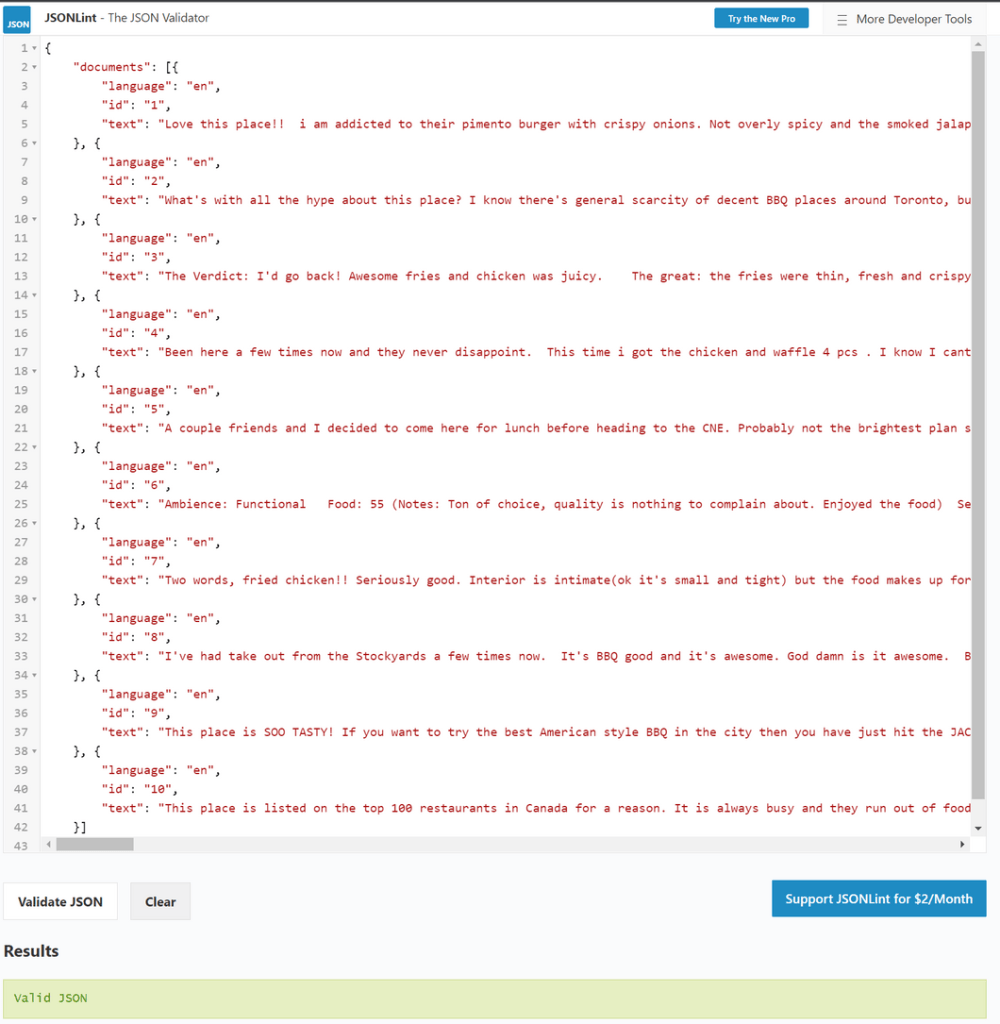
If you copy the content of one of the cells under the to_sentiment_api column and paste it on an online JSON formatter, it should show a list of 10 texts in a clean JSON structure.
Creating Data Source using the Sentiment API Web Service Connector
Creating Data Source using the Sentiment API Web Service Connector

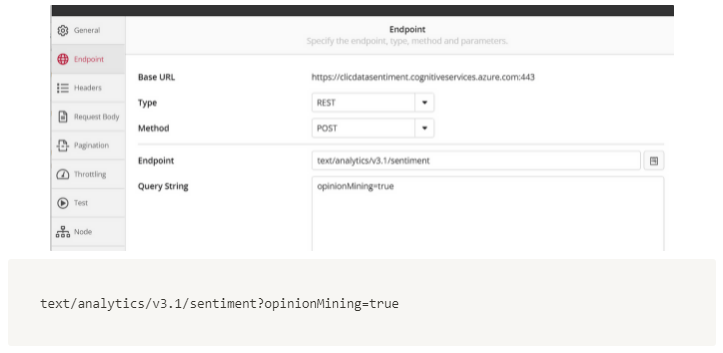
Under the Endpoint tab, enter the endpoint and query as shown below with a POST request. We are adding the query ‘opinionMining=true’ so that we get a response containing the sentiment scores of items within the text as well.
For a POST request, you will need to add a request body. This will be the request containing the list of text we converted to a JSON structure. To put this request together, we need to use macros to reference the view (input_for_API) containing the input data as shown below.
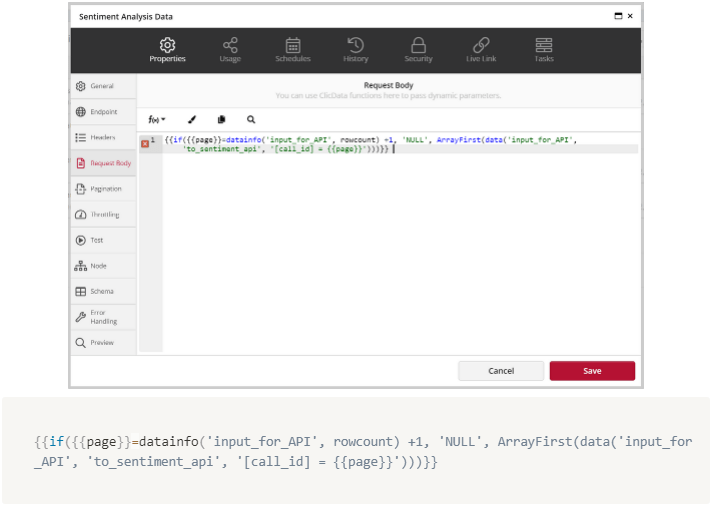
The call_id in the formula above represents each call being made via the API. This call_id will increment until it exceeds the maximum value of the call_id in the view input_for_API. This increment using the paging functionality where we are using a variable {{page}} to run through all call_id values starting from 1 to a value where the API response will result in an error with 400 status code.
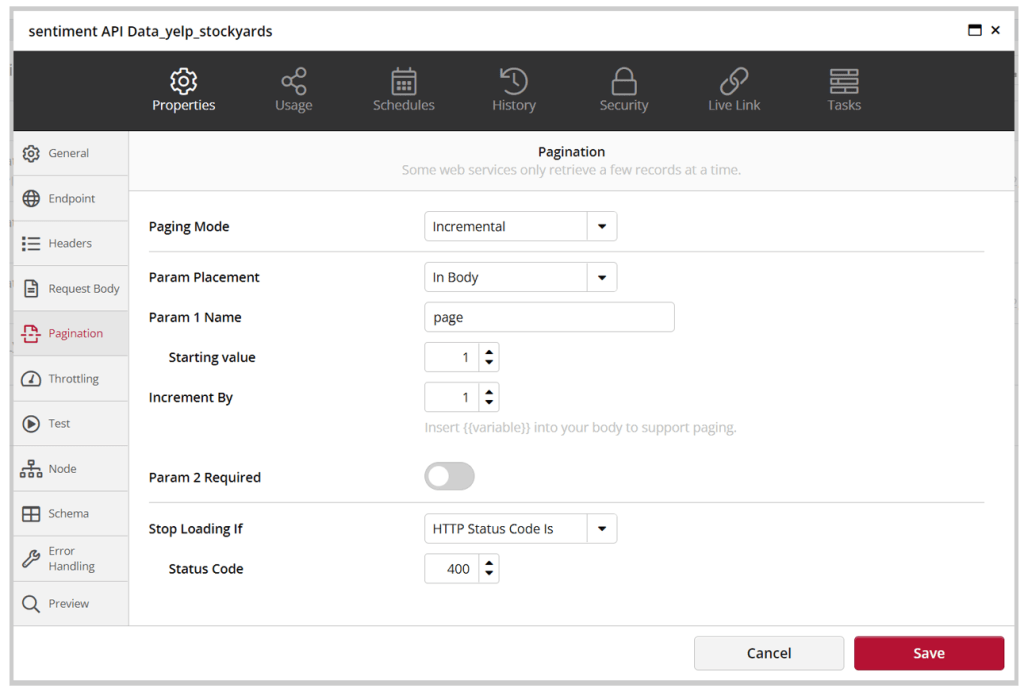
If the above steps are done correctly then we should be able to select a node under the ‘Node’ tab. Select the ‘confidenceScores’ node so that you can view the scores of each item in a flat file.
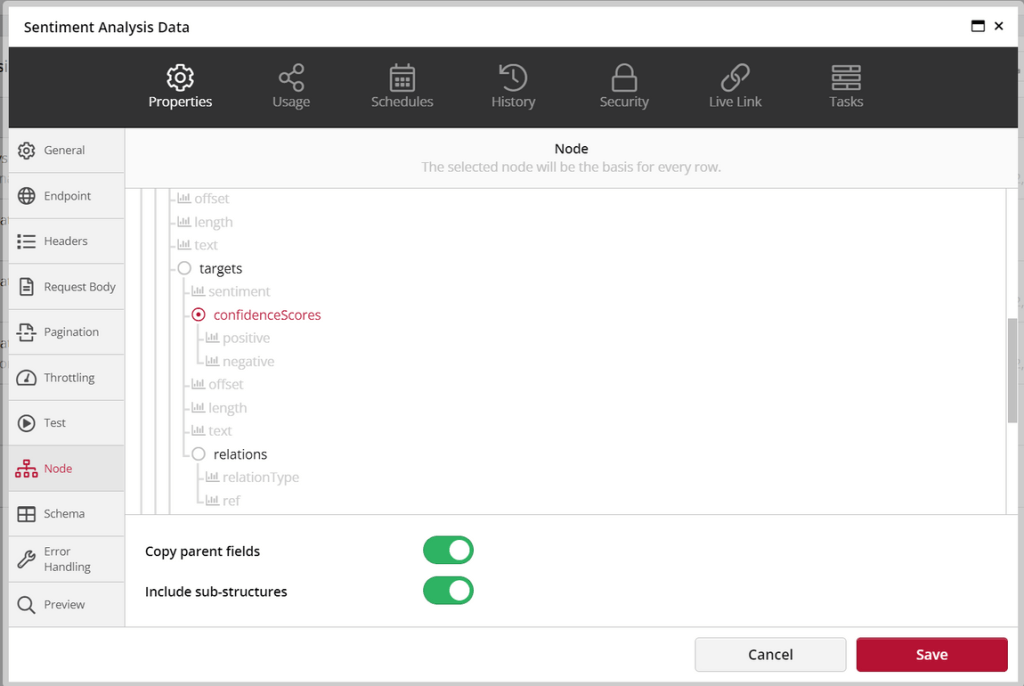
You are ready to send the request. Click Save and refresh the data. The response should have a sentiment value for each text, and each identified item using opinion mining.
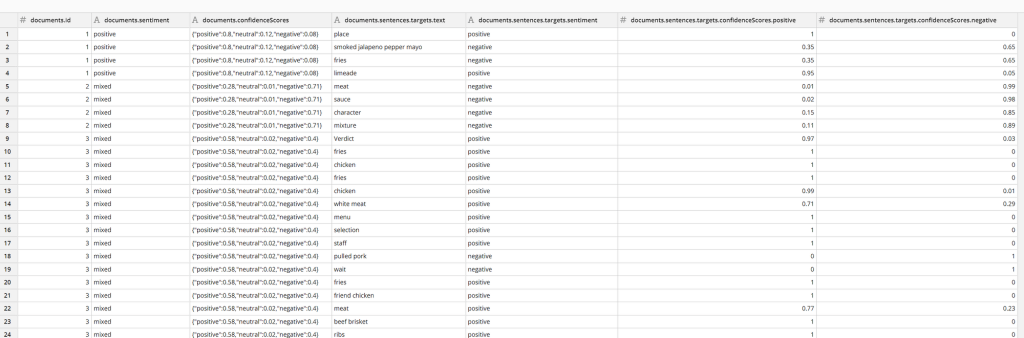
Understanding the data
The response contains sentiment ratings for each review, each sentence within the review and each item with the review as determined by opinion mining.
The following is a brief description on each column we will be using on the dashboard:
documents.id – corresponding to the id of each text (review) on the input text file
documents.sentiment – the sentiment of each review given in these qualitative categories (positive, neutral, negative, mixed)
documents.sentences.targets.text – list of relevant items (atmosphere, food, location, decor etc) as determined by opinion mining on each review that has its own sentiment rating
documents.sentences.targets.sentiment – the sentiment of each item within each review these qualitative categories (positive, negative)
From the above, we can reveal some insights right away such as ratio of positive to negative reviews and most frequently occurring item reviewed about, number of positive/negative sentiments on each items etc.
Post processing for visualization
You can do some further transformations on the response to create data structures that suit the widgets you want to add to the dashboard.
We previously mentioned obtaining ratio of positive to negative sentiments and most frequently occurring item from the response. We can also perform additional transformations for drilling down to more granular insights such as number of positive and negative sentiments of each item from over 600 reviews. On the dashboard we can present this information to determine for example, which item could be advertised for the restaurant or which item needs improvement due to receiving relatively more negative sentiments.

Visualization
You have the option of using a variety of widgets to make the analysis pop out. You can create bar charts to gauge the positive, negative and neutral reactions from the reviews. Using word clouds, you can see items that are most talked about on the restaurant reviews.
Here is a dashboard we have created using Yelp reviews for a restaurant called The Stockyards.
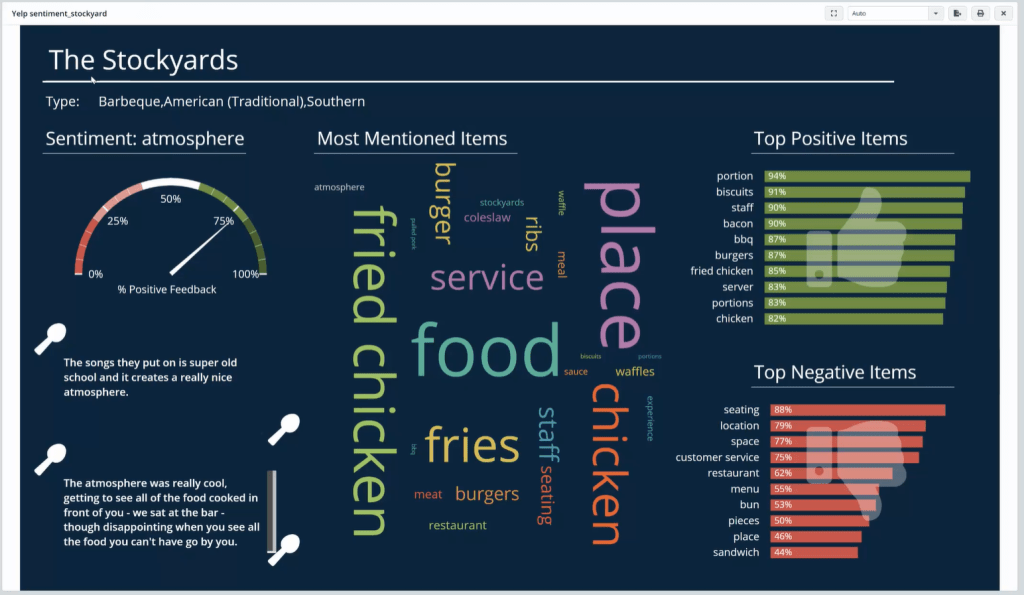
It has a word-cloud widget the shows the relative frequency of items mentioned on the review. Clicking on each of the items on the word-cloud widget will reveal the % positive feedback on the gauge to the top-left. To the right, two column charts are showing top 10 positive and negative items which should give a clear picture on which aspects the restaurant is doing well and which ones it could improve upon based on the reviews it received.
Summary
Sentiment Analysis can offer you a powerful tool to visualize insights at a more granular level from vast quantities of unstructured data that would otherwise be left unused. With the combination of multiple out-of-the-box sentiment analysis options available, you can harness ClicData’s business intelligence and dashboard platform to go beyond reporting conventional metrics to unlock hidden value in a few easy steps for a better customer experience.
Look out as well for our integration with Azure Cognitive Services that will enable you to integrate text mining capabilities in your Data Flow processes. Additionally, don’t hesitate to watch the Opinion Mining and Sentiment Analysis webinar replay, where we will go through this blog’s content step by step.

