As data analysts, we use SQL functions day in, day out. And we tend to use the same functions over and over again but we’re sometimes struggling to get to the expected output with those functions.
This article will give you four underused SQL functions with practical examples on how to use them.
Let’s dive in!
Using SOUNDEX() Function to Cleanse Data Based On Word Phonetic
Probably one of the least known SQL function but also the coolest!
The SOUNDEX() function in SQL is used to convert a string into a phonetic representation, which is particularly useful for searching and matching strings that may have different spellings but similar sounds.
The SOUNDEX() function works by assigning a four-character code to each string based on its pronunciation. Strings that have similar sounds will have the same or similar SOUNDEX values.
Here’s the basic syntax of the SOUNDEX() function:
SOUNDEX(string)By the way, the result of the soundex on ‘string’ is S365.
Here how does the SOUNDEX() function convert letter into number :
| Number | Letter |
| 1 | b, f, p, v |
| 2 | c, g, j, k, q, s, x, z |
| 3 | d, t |
| 4 | l |
| 5 | m, n |
| 6 | r |
The following letters are ignored: a, e, I, o, u, h, w and y.
Now, let’s write some code and go through a step-by-step example:
Using SOUNDEX() to clean city names
Suppose that you have a table with a city name field, and that this data is manually filled. This risk is to have different spelling for a same town, for example:
| City name |
| Springfield |
| Springfeld |
| Sprintfield |
| Smithtown |
| Smythton |
Instead of having 3 differents version of ‘Springfield’, we should only have one and we should only have ‘Smithtown’.
Now, let’s use the SOUNDEX() function to find similar-sounding names:
| City | Soundex results |
| Springfield | S165 |
| Springfeld | S165 |
| Sprintfield | S165 |
| Smithtown | S530 |
| Smythton | S530 |
Here it is !
The SOUNDEX() function allows us to detect town’s name that are actually spelled differently but shouldn’t.
That’s a simple example of how you can use the SOUNDEX() function in SQL to find approximate matches based on the phonetic similarity of strings.
Side note: To detect the true city name, a city database can be used, or if not available, you can count the number of iteration of each value. Then, you can assume that the right one is the one with the highest value.
Also, SOUNDEX has some limitations! The number of character to be encoded for instance. Here’s an example of a longer location name:
SOUNDEX('Riverdale Town')
SOUNDEX('Riverdale Park')Will both return R163 has the following letters will return those results:
R>R
V>1
R>6
D>3
Only the first four consonant letters are encoded (R, V, R, D) and everything coming after will not impact the SOUNDEX results. This is why long word with the same first letters will have the same SOUNDEX() results.
Using LAG Function for Analyzing Data Over Time
In SQL, the LAG function is pretty handy when you’re looking to find the previous or next value of a row. For example, we’ve used when we wanted to to compare a delta between two periods.
In most cases, you’re dealing with the data in line like this:
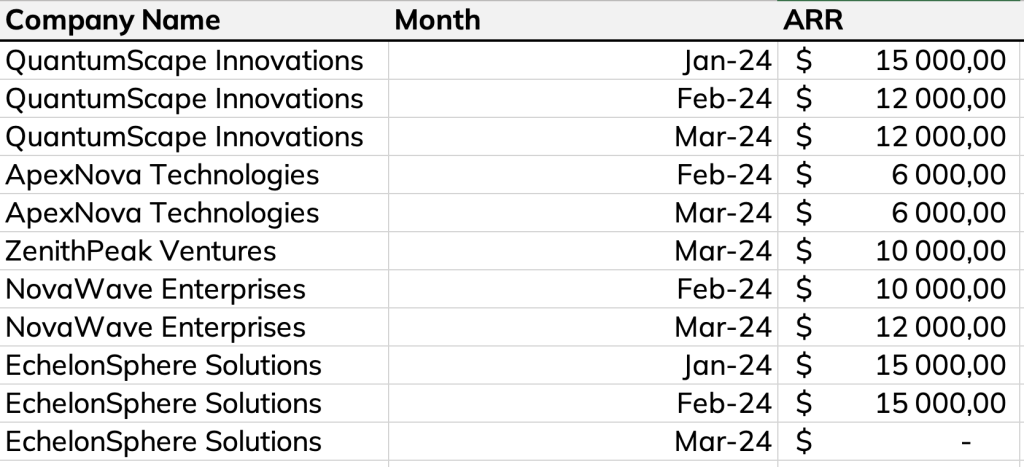
In this example, we’re looking at a subscription table with a line per customer and the amount of their subscription for each month.
With this table, you can analyze the ARR per customer or total ARR over time. But you can’t get the new ARR at a given time.
With the LAG function, you can quickly get that analysis. Here’s how the function looks like:
LAG(ARR, 0) over (partition by [Month],[Customer] order by [Month] desc)How to read the function:
- 0 corresponds to the default value
- LAG will be performed for each customer, per month (partition by)
- desc because we are looking for the value of the previous month
In order to measure New ARR for each month, we recommend following this method:
- adding a column “ARR Previous Month”
- adding a column “Delta” which is not mandatory but will simplify the conditions
- adding a column “Type” to identify New, Expansion, Contraction or Churned customers.
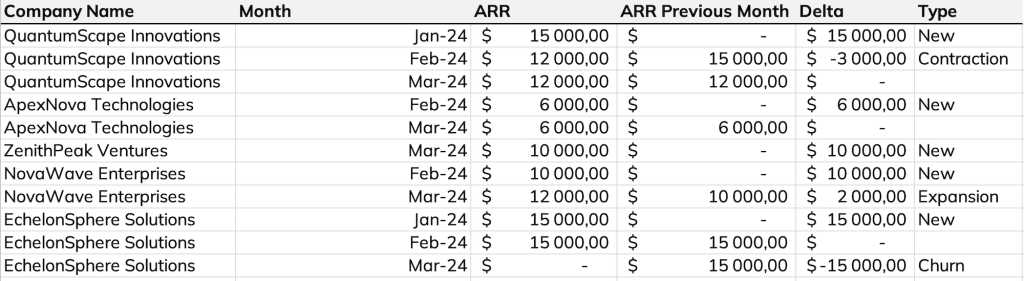
To create the last column, we can use the CASE WHEN statement with the following logic:
CASE
WHEN LAG([ARR], 0) over (partition by [Month],[Customer] order by [Month] desc) IS NULL THEN 'NEW'
WHEN[ARR]> LAG([ARR], 0) over (partition by [Month],[Customer] order by [Month] desc) THEN 'EXPANSION'
WHEN [ARR] = 0 THEN 'CHURN'
WHEN [ARR] < LAG([ARR], 0) over (partition by [Month],[Customer] order by [Month] desc)
THEN 'CONTRACTION'
ELSE 'NO CHANGE'
END With the Delta column which is the difference of ARR and ARR of last month you can simply do:
CASE
WHEN DELTA > 0 AND [Delta]=[ARR] THEN 'NEW'
WHEN [Delta]> 0 THEN 'EXPANSION'
WHEN [ARR] = 0 THEN 'CHURN'
WHEN [Delta]< 0 THEN 'CONTRACTION'
ELSE 'NO CHANGE'
END The Delta column is often a better option because it can be used in dashboards: for example, it reveals that in February we had + $13k of ARR and no loss, and that in January the ARR grew by +$30k and no loss – and that your sales team is killing it! ️
Using PARTITION BY with BETWEEN Functions to Calculate Values Over Rolling Periods
The SQL function PARTITION BY is very common, but it’s rarely coupled with the BETWEEN function. It can be very handy!
For example if you want to calculate monthly sales for each sales rep and their sales over the past 12 rolling months.
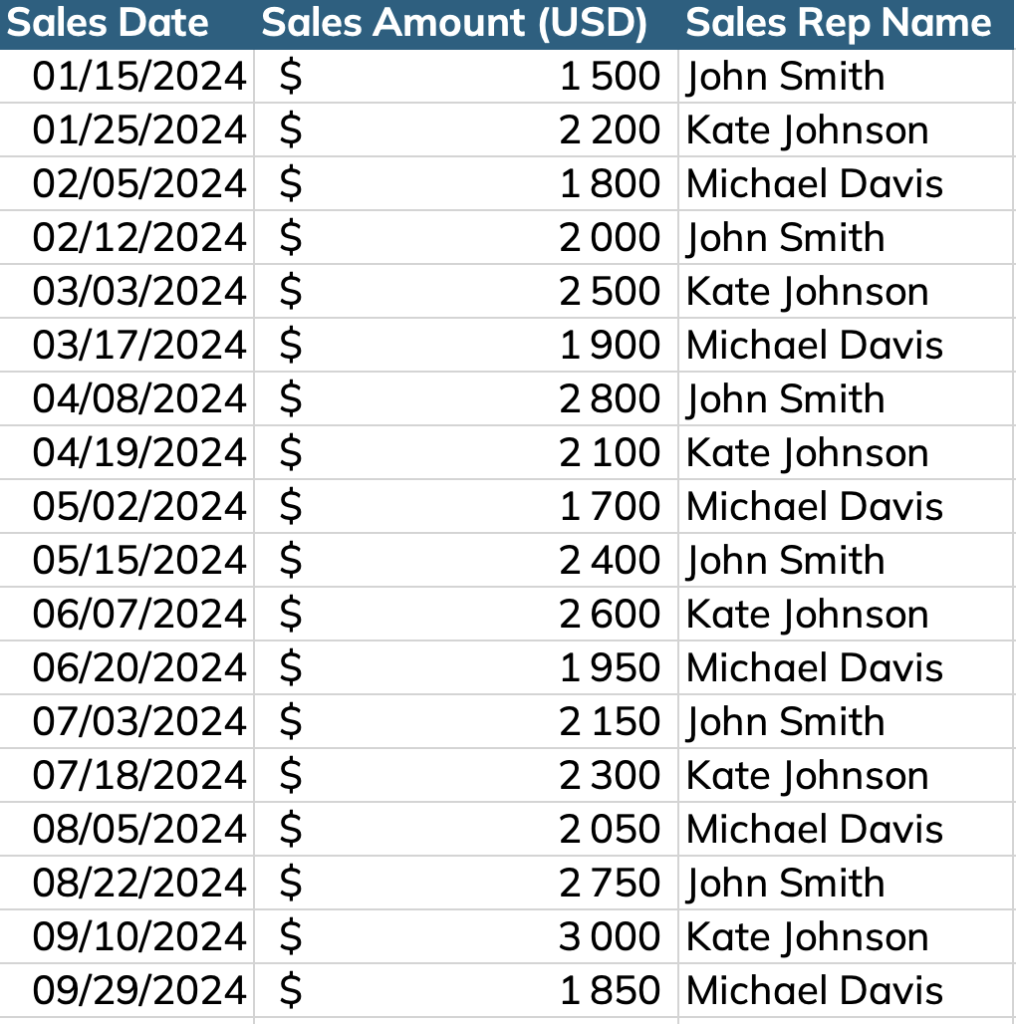
That’s easy on Excel as you just have to select the cells to get those numbers.
But in SQL it’s actually not that simple especially when the rows of the dataset are not ordered or aggregated at the right level and when you’re looking to analyzing the data over 2 different types of periods in parallel – in our example, sales by month and sales over 12 rolling months.
In our example, we want to analyse sales on 3 rolling months to keep the dataset simple. Here are the steps to follow:
Step 1 – Convert the sales date to a date format
Assuming the sales date is already in a standard format like YYYY-MM-DD.
Step 2 – Calculate the average sales amount per month for each sales rep
SELECT
EXTRACT(YEAR FROM sales_date) AS sales_year,
EXTRACT(MONTH FROM sales_date) AS sales_month, sales_rep_name,
SUM(sales_amount) AS sales_amount
FROM
your_sales_table_name
GROUP BY
EXTRACT(YEAR FROM sales_date),
EXTRACT(MONTH FROM sales_date),
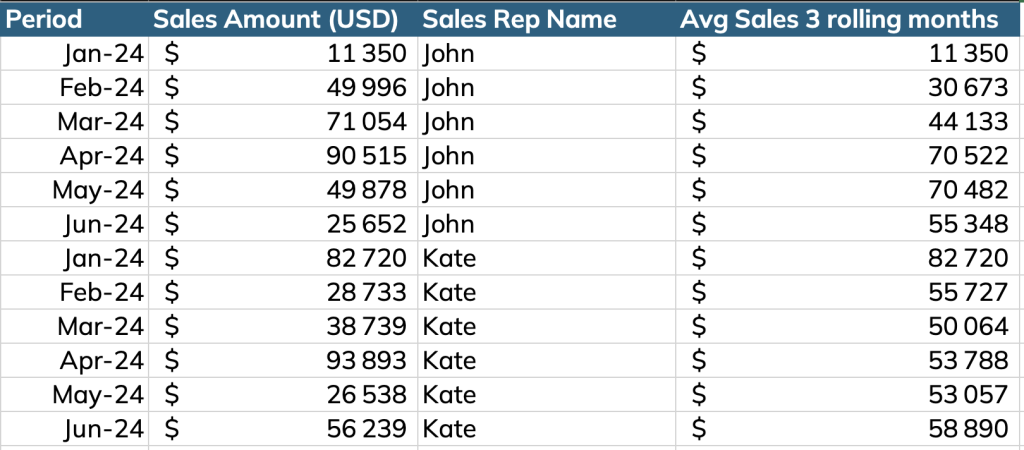
sales_rep_name;Step 3 – Use PARTITION BY and BETWEEN to aggregate the data per month for each salesperson
SELECT
sales_year,
sales_month,
sales_rep_name,
sales_amount As Sales_per_month,
AVG(sales_per_month) OVER (PARTITION BY sales_rep_name ORDER BY
sales_rep_name, sales_year, sales_month
RANGE BETWEEN 2 PRECEDING AND CURRENT ROWS) AS 3months_moving_avg_sales_amount
FROM (
SELECT
EXTRACT(YEAR FROM sales_date) AS sales_year,
EXTRACT(MONTH FROM sales_date) AS sales_month,
sales_rep_name,
SUM(sales_amount) AS sales_amount
FROM
your_sales_table_name
GROUP BY
EXTRACT(YEAR FROM sales_date),
EXTRACT(MONTH FROM sales_date),
sales_rep_name
) AS subquery_alias; Returning the following table:
Using ROW_NUMBER Function to Create Unique Identifiers or Create Top Rankings
The ROW_NUMBER function can be used for many cases, but we used it for two main scenarios: creating a unique identier and creating tops and flops ranking while handling equal values. Let’s take a look at both cases with examples.
Case 1: Using ROW_NUMBER to create a unique identifier
In this simple table, we have list of 5 social media posts with the number of likes and comments for each of them.
ROW_NUMBER() over(partition by [post title] order by [likes] desc)will give:

The value equal to 1 returns the post with the most likes due to the order by DESC.
Case 2: Using ROW_NUMBER instead of RANK to create a top when values are equal
We wanted to show you the difference between ROW_NUMBER and RANK functions in a concrete example. You could choose between one or another when you’re looking to create a top posts ranking based on number of likes. In this case, we have two posts which generated the same number of likes, 312.
ROW_NUMBER does not allow to have two identical values, they will be differentiated based on the ORDER BY.
RANK function will give you the same ID.

In the case, using the ROW_NUMBER function, the posts “Unlock Business Insights: 5 Analytical Strategies for Success” is ranked 1st because the post title starts with a U, and we used ORDER BY DESC.
Get More Efficient With Your SQL Queries With Advanced Functions
Data transformation takes up a bing chunk of our time, so whenever we learn new tricks to make it more efficient, we test them!
We use SOUNDEX, LAG, PARTITION BY BETWEEN and ROW_NUMBER quite a bit for our internal and client projects and the data team absolutely loves them!
If you know more underused SQL functions, share them with us!
Learn how to couple your SQL functions with ClicData formulas for more efficient data management and analytics: