So what does “building trust” in data mean?
It can mean different things depending on who you ask.
For internal teams, building trust means having access to accurate, consistent data they can confidently use for analysis and decision-making. For customers, it means knowing their personal data is secure, handled responsibly, and protected from leaks or misuse.
Here’s the thing: data doesn’t stay still. It moves through pipelines, gets stored, transformed, and shared across systems. Along the way, mistakes can happen, sometimes without anyone noticing. A simple misconfiguration or unnoticed format change can quietly cause errors that affect dashboards, reports, or models.
In 2017, Equifax experienced a massive hack that compromised the information of 147 million American consumers (FTC). Hackers used an unpatched vulnerability in Apache Struts and remained unnoticed for months.
With a rise in such cases, establishing trust in your data has become a functional and regulatory requirement.
This article explores how to build trust in your data through layered validation, detailed audit trails, and strong role-based access control. We’ll also look at how ClicData helps make this easier with built-in tools for validation, security, and monitoring.
So how do to begin?
How to Spot Silent Data Errors and Stay Compliant
Not all data errors are loud and obvious. Some slip by quietly and don’t trigger alerts—these are called silent errors. They can sneak in from things like:
- A network issue that only transfers part of a file
- A data update that fails (like in our example)
- A schema change that drops or shifts columns
- A join operation that misses key records
The problem? These errors can mess with critical metrics and reports without anyone noticing.
Let’s say your system pulls exchange rate data from an external source. If the currency format changes or stops updating and no one catches it, your entire revenue report could be off and no one would know until it’s too late.
For example, if your dashboard is still using an outdated exchange rate of 1.10 EUR/USD instead of the correct 1.00, your reported revenue in euros could be inflated by 10%. That might look like you’re hitting your targets—until auditors or finance teams catch the discrepancy during month-end close. Now you’re not just fixing reports, you’re explaining the mistake to leadership or regulators.
These kinds of errors aren’t just operational headaches—they can put you at risk of violating data regulations.
- SOX (Sarbanes-Oxley Act) requires companies to prove their financial data is accurate and complete. You need controls that catch errors and provide evidence that checks are happening. If you can’t demonstrate this (especially for SOX Section 404), you risk audit failures, reporting delays, or even fines.
- GDPR has its own strict rules. Under Article 5, personal data must stay accurate and reliable. And Article 30 says you must keep records of who accessed or modified the data, and when.
So whether it’s financial or personal data, the bottom line is the same: you need systems that validate data continuously and log everything clearly.
But how do you actually do that?
What Are Validation Layers, and Why Do You Need Them?
Once data enters your system, you need ways to make sure it’s complete, correct, and hasn’t changed in ways you didn’t expect.
That’s where validation layers come in.
Think of them like safety nets at different points in your data pipeline. Each layer checks for different types of issues. Together, they give you a defense-in-depth strategy—which means even if one check misses a problem, another might catch it.
Let’s walk through the most common ones.
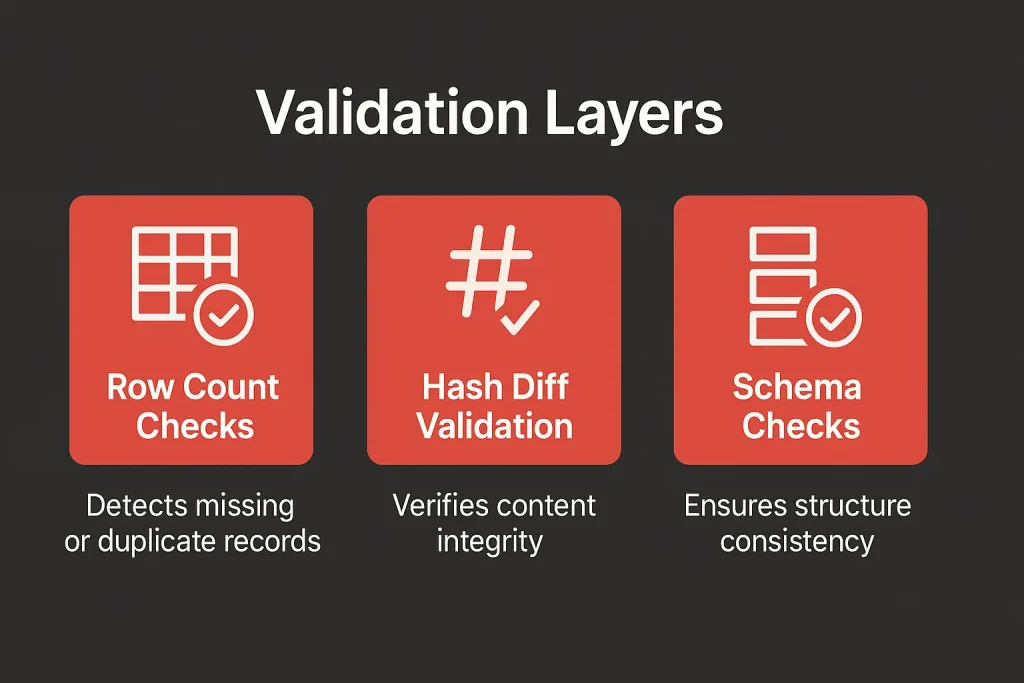
Row Count – Is any data missing or duplicated?
This is usually the first check teams run after loading data.
You simply compare how many rows you expected with how many you actually loaded. If the numbers don’t match, something went wrong.
Maybe a partition was skipped, maybe a job wrote data only halfway, or maybe a connector dropped records. For example, if your revenue data usually has 2 million rows but suddenly drops to 1.6 million, that’s a red flag, even if the pipeline says “job successful.”
To catch this early, many teams automate row-count checks and set up alerts if the difference exceeds a threshold.
Hash Diffs – Has the content changed?
Row counts alone can’t tell you if the actual values in your data changed silently.
That’s where hash diffs come in. Here’s how it works:
- You take key columns, merge their values into a string, and apply a hash function like
SHA-256. - Then you compare that hash to a previously stored value.
If the hashes match, the data hasn’t changed. If they don’t, something changed, maybe a column was re-encoded or a space was added where it shouldn’t be.
Hash diffs are especially useful in distributed systems, where files might be compressed, split, or rewritten without notice. Even tiny changes will produce a different hash, which makes this method reliable for verifying content integrity.
Schema Checks – Has the structure changed?
Sometimes, it’s not the content but the structure that changes—this is called schema drift.
Maybe a column that was a number is now a string. Maybe a field disappeared. These kinds of changes can quietly break your calculations or reporting if you’re not looking out for them.
Schema validation checks:
- Are all the expected columns present?
- Do data types match?
- Are constraints still enforced?
If something is off, it flags the issue before the data moves forward in your pipeline. Some teams also store schema definitions in Git, which allows you to track changes and roll back if needed.
How does this work in practice?
Modern orchestration tools like Apache Airflow, AWS Glue, and Azure Data Factory can run these validations either one after another or in parallel.
You can:
- Capture logs to make troubleshooting easier.
- Run them as containerized jobs or cloud-native functions.
- Get alerts via email, Slack, or webhooks when something fails.
- Set up auto-retries, rollbacks, or require manual approval based on the issue.
Validation Layers Comparison Table
The table below summarizes how different validation layers address common data quality risks.
| Validation Type | What It Detects | When It’s Used | Example Tool/Technique |
| Row Count | Missing/extra rows | Post-ingestion | Count comparison, thresholds |
| Hash Diff | Data content changes | Post-transformation | SHA-256 checks on key columns |
| Schema Check | Drift in structure | Pre-ingestion or post-ETL | JSON schema diff, Git comparison |
Validation layers help catch data issues as they happen. But to prove that your data was handled correctly—and by the right people—you also need a record of what took place.
That’s where audit logging comes in.
What Does Audit Logging Do for Data Accountability?
When validation checks for accuracy, audit logs create a traceable history of everything that happens in your data pipeline.
A typical audit log records multiple dimensions of every event.

- Who: First, it documents who did it. This could be a human user, an analyst, a data engineer, or a service identity used by an automated pipeline. Accurate attribution creates accountability and aids investigation in the case of anomalies.
- What: The Log explains what action was taken. This may involve the ingestion of data, transformation, schema change, or deletion. Clear descriptions will allow auditors and administrators to know the context of every event.
- When: Audit logs record the time an action occurred, stored in a standardized form such as ISO 8601 or UNIX timestamp. It is important to have the right timing to track event sequences to match activities across systems.
- Where: Logs provide records of the place of occurrence. This consists of a dataset, table, or storage identifiers. Location metadata can define a context that recreates a complete picture in data warehouses and processing systems.
- How: Proper logs capture metadata such as rows processed, computed hash digests, schema versions, processing times, and the identities of users or services performing the actions. Such further information connects the audit records with the evidence of validation, which makes reporting on compliance easier.
Why immutability and retention matter?
To support real accountability, logs should be:
- Immutable: Stored in a tamper-evident way, like write-once storage or using digital signatures
- Retained for the right length of time
Audit logs aren’t helpful if they can be altered later.
For example:
- SOX requires keeping records for at least seven years
- GDPR doesn’t set a fixed duration, but expects companies to justify their retention policy based on data sensitivity and risk
That’s why a clear retention policy is a key part of data governance.
How to make audit logs useful in practice?
It’s not enough to collect logs, you need to monitor them actively.
Many teams plug their audit logs into centralized monitoring or SIEM tools like Splunk or Elastic. These systems help detect suspicious behavior in real time.
For example:
- AWS CloudTrail Insights can flag unusual API activity, like access outside normal hours
- These alerts can be sent through EventBridge, Slack, or other real-time systems
This turns your audit logs into an active part of your security and compliance strategy, not just a dusty archive.
Audit logs tell you what happened and who did it. But the next question is just as important: who should be allowed to do it in the first place?
That’s where role-based security comes in.
Role-Based Security for Precision Access and Trusted Analytics
Trust in analytics depends not only on data accuracy but also on controlling access to sensitive information. Role-based security establishes clear rules regarding who can view or modify specific data.
What are the different roles and why do they matter?
In most cloud analytics environments, users have different responsibilities. So they need different levels of access.
Instead of setting permissions user by user, platforms use roles—each role defines a set of permissions. Common roles include:
- Analysts, who usually need read-only access to certain datasets
- Data engineers, who need to ingest, transform, and validate data but shouldn’t see sensitive fields
- Auditors, who need visibility into logs and validation checks but shouldn’t be able to modify anything
Most platforms integrate with identity providers (like Okta or Azure AD) to assign roles automatically based on a person’s job or department. This improves both security and ease of management.
Column-Level Security: Hide sensitive fields
Even if users share access to the same dataset, not everyone should see everything.
Column-level security lets you restrict access to specific fields—for example, hiding salary data or customer ID numbers from anyone without clearance. You can:
- Replace values with nulls or fake data (masking)
- Allow or deny access at the column level
This supports data minimization requirements in GDPR by exposing only what’s strictly necessary.
Row-Level Security: Filter data by role or region Security
While column-level security controls what fields you see, row-level security controls which records you see.
Let’s say you have sales data across different regions:
- A European sales rep should only see EU records
- A US analyst should only see US data
Row-level security applies these filters automatically—based on the user’s role, department, or region—without needing to create separate datasets.
This simplifies governance and keeps everything centralized.
Keeping roles and access current
Role-based access only works if it reflects your org’s current structure.
That’s why teams should:
- Integrate with identity providers (like Okta, Azure AD, or LDAP) for single sign-on (SSO) and centralized control
- Set up automated provisioning and deprovisioning so that access updates when someone joins, leaves, or changes roles
- Review roles regularly to ensure permissions still align with responsibilities
When done right, role-based security helps ensure that your analytics are not only accurate but also secure and compliant.
How ClicData Helps You Build Trust in Your Data
ClicData brings data validation, audit logging, and role-based security into one unified platform—no external tools, no custom scripts.
You can:
- Run automatic validation checks (like row counts and schema checks) during ingestion
- Block bad data before it hits dashboards
- Log every action with full user, time, and source context
- Apply row- and column-level security based on user roles
- Create audit dashboards that track access, ingestion activity, and validation results
Everything is versioned, exportable, and built to support compliance with SOX, GDPR, and other governance standards.

Ingestion Controls & Validation Logs
ClicData’s Smart Connectors automatically execute validation procedures such as row-counting and schema consistency checks during the data ingestion process. It saves validation results in a dataset, you can review or export as CSV, Excel, or JSON for audit purposes.
Administrators can automate alerts or abort ingestion in the event of validation failure, ensuring that incomplete data will not be passed to the dashboards.
Evidence Sharing & Audit Dashboards
ClicData can produce dashboards that record ingestion activities, validation results, and user access history. The users can create snapshot URLs that maintain a point-in-time view of these dashboards.
When used in conjunction with retention policies and access controls, these snapshots can help organizations demonstrate compliance with regulations.
Row Level & Column Level Access Enforcement
ClicData allows row-level security by folder and parameter. You can organize your work area with Main and Team folders, assign permissions to each folder, and filter to display only the relevant row data for each user.
The column-level restrictions are administered through role-based authorization associated with particular datasets or dashboards. This allows the users to see only authorized fields.
These role assignments help streamline data governance, reduce unnecessary exposure, and maintain consistent, secure access across all analytics assets.
So what’s your next step?
Start a free trial or book a demo to see how ClicData helps you deliver trusted, governed analytics in just a few clicks.