Dashboards don’t break because of bad charts. They break because nobody agreed on what revenue means, and the pipeline feeding it changed two weeks ago without telling anyone.
That’s the unglamorous truth behind most BI failures. The visualization layer takes the blame, but the real problem sits upstream: Unvalidated data, undocumented transformations, and teams working without any shared agreement on what the data should look like by the time it arrives.
Most pipeline errors are discovered not by monitoring tools, but by business users, after the damage is already visible in a report.
That’s a governance gap, not a tooling gap.
This guide covers what data contracts and data lineage actually mean for BI teams in practice, why skipping them creates compounding problems at scale, and what a realistic implementation looks like.
Why Governance Becomes Urgent at Scale
The typical trajectory of most data-centric organizations is characterized by a period of initial growth, during which a small team of analysts possesses in-depth familiarity with every table, including its idiosyncrasies, potential pitfalls, and edge cases. The system holds together because knowledge lives in peoples’ heads.

And at some point, someone implements a schema change that nobody communicated, and three dashboards start producing different numbers for the same metric.
That’s the governance debt moment. It arrives for almost every team that scales past a handful of sources.
The instinctive response is more tooling: another monitoring layer, another Slack channel for data incidents, another quality check bolted on somewhere.
None of that addresses the problem: no formal agreement between producers and consumers of data and the people who consume it; no mechanism to trace what happened when a number goes sideways; no way to catch problems before they reach stakeholders.
Data contracts and data lineage address this at the structural level. They are not niche concepts for large engineering organizations. They are the operational backbone that any BI team needs when managing more than a handful of sources and a few dozen reports.
What is a Data Contract?
In essence, a data contract is a binding contract between the person who generates data and the individual or entity who uses it. It specifies the expected qualities and actions of the data, as well as the requirements that must be met before it can be used for any subsequent purpose.
The closest analogy is an API contract. When a software team publishes an API, they commit to a schema: field types, expected responses and error behaviour. Downstream teams build against that specification, knowing it won’t change arbitrarily. Data contracts apply the same principle to pipelines, but instead of an endpoint, the focus is on a table or a stream of data.
IIn practice, a contract covers:
- Schema: Expected columns, data types, nullability
- Freshness: How recently the data must have been updated
- Completeness: Minimum thresholds for populated fields or row counts
- Validity: Business logic rules (revenue >= 0, status must be in an approved set)
- Ownership: Who is accountable for producing and maintaining this dataset
It lives as a versioned YAML or JSON file, enforced automatically at pipeline ingestion. When incoming data violates it, the pipeline stops (loudly) rather than letting bad data flow through to the analytics layer.
Below is a simplified example:
data-contract: orders_daily.yaml
dataset: orders_daily
owner: data-engineering@company.com
version: 2.1.0
schema:
- name: order_id
type: string
nullable: false
unique: true
- name: order_date
type: date
nullable: false
- name: revenue
type: decimal(10,2)
nullable: false
checks:
- revenue >= 0 # no negative revenue values permitted
sla:
freshness_hours: 6 # reject data older than 6 hours
completeness_pct: 99.5 # 99.5% of key fields must be non-null
row_count_min: 500 # alert if load drops below 500 rows
notify:
on_breach: [bi-team@company.com, data-eng@company.com]This file isn’t something that sits in confluence waiting to go stale. It runs on every pipeline execution, versioned alongside the code that produces the data. A breach doesn’t send an email for later; it immediately halts the pipeline so that corrupt data doesn’t move anywhere.
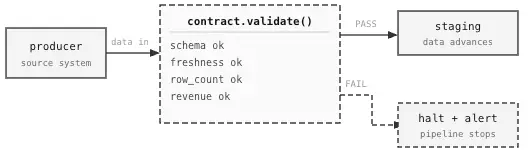
One practical note on scope: resist the urge to contract everything at once.
Start with the dataset feeding the most business-critical dashboard. Write one contract, enforce it in staging, and confirm the pattern works. Coverage can expand from there.
What Is Data Lineage?
The short version: data lineage is the map of where data came from and everything that happened to it on the way.
That matters more than it sounds. When a finance team asks why Tuesday’s revenue figure is $47,000 below Monday’s, the answer isn’t in the dashboard. It’s somewhere upstream, in a transformation that ran differently, or a source record that arrived late, or a join that dropped rows it shouldn’t have.
Lineage lets you trace the number back through each layer until the discrepancy shows up, which means no manual dig through query logs, and no hunting down whoever last touched that pipeline.
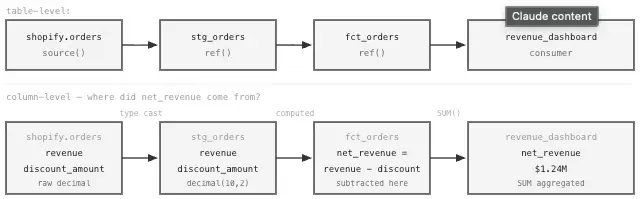
Image by Author. Data Lineage. Every number on screen has a traceable source back to its origin.
The forward-looking case is just as important. Before changing a source table, a data engineer needs a complete picture of every model, KPI, and dashboard that depends on it. Lineage provides exactly that. Teams that skip it tend to find out what was connected the hard way, after something breaks.
How the Two Work Together
Contracts and lineage are often treated as separate concerns, but the gap that appears when one is missing shows why they belong together.
- Contracts alone: Data enters clean and validated, but when something breaks downstream, there’s no map to trace it back.
- Lineage alone: You can see the full data path, but bad data can travel the entire route undetected.
The combination closes that gap.
- Contracts govern what enters the pipeline; bad data fails at the gate and goes nowhere.
- Lineage maps every step the data takes once it’s inside.
The result is an auditable chain from source to report: not a general assumption that numbers are probably correct, but a traceable record of exactly where each figure came from and what happened to it.
Why Dashboards Break Without This Discipline
The failure modes in uncontrolled data environments tend to follow predictable patterns.
The Silent Schema Change
An upstream team renames a field, adds a column, or changes how they encode a status value, without informing the BI team. The pipeline technically keeps running, but the transformation logic that depended on the old structure now produces garbage. The dashboard refreshes normally, the numbers look fine, and two weeks later someone notices customer churn has been miscalculated for an entire reporting cycle.
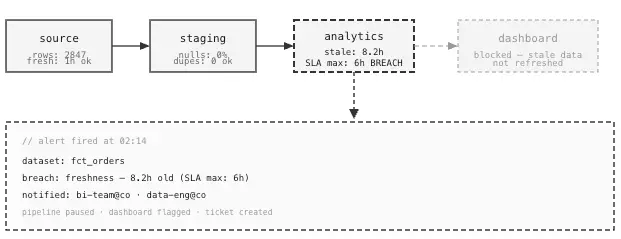
Image by Author. Data Pipeline Monitoring. We can automate the finding of problems before users do.
With contracts that enforce schema stability, the violation surfaces at ingestion, before anything reaches the analytics layer. ClicData’s pipeline layer enforces exactly this: transformations are defined centrally, changes are controlled, and nothing propagates downstream until the data passes its validation rules.
The Diverging KPI Problem
Two analysts define “active customers” for two different dashboards. One counts logins in the last 30 days; the other counts any transaction in the last 90 days. Both numbers appear in executive reporting. At some point, someone asks why they don’t match. Both analysts are correct by their own definitions; there’s just no single agreed-upon one. Trust erodes.
Formalizing metric definitions at the contract level prevents this kind of drift from accumulating silently. Modular SQL: The Secret to Consistent KPIs Across Dashboards covers how to enforce that consistency through query structure.
ClicData addresses this directly: Metric definitions live at the pipeline level, meaning every dashboard drawing from the same dataset works from the same calculation, with no room for individual analysts to quietly redefine terms upstream.
The Untraceable Error
A board-level report shows a number that’s off by 8%. The data engineer checks the pipeline, the analyst checks the SQL, and operations checks the source extract. Nobody can isolate the issue; no record exists of where the data came from, what transformations ran, or what the row count was at each stage. The investigation runs three days. A decision that should have happened Monday gets pushed to Thursday.
Lineage doesn’t eliminate errors. It eliminates the part of the problem where nobody can find where the error was entered.
Implementing Data Contracts: Where to Start
A full governance overhaul on day one rarely takes hold. The more practical entry point is the pipeline that carries the most business risk, get one contract working end-to-end, then expand the pattern.
Step 1: Identify Tier-1 Datasets First
Start with the datasets feeding the dashboards executives actually use to make decisions. Write those contracts first. Everything else can follow once the implementation pattern is proven.
Step 2: Define the Contract Specification
For each dataset, the spec defines the schema, SLA expectations (freshness, completeness, row-count thresholds), and business rules, in a format that lives in version control right next to the pipeline code. In practice, most teams implement this as YAML-style contracts with automated validation that runs as a pipeline step before the data is allowed to move to the next layer.
Step 3: Enforce at Ingestion, Not at the Dashboard
The most common mistake is validating data inside the BI tool, through calculated fields, conditional formatting, or dashboard filters, which is the wrong layer. By the time data reaches a dashboard filter, it’s already in front of someone.
Data quality enforcement belongs in the pipeline, before anything reaches the analytics tables. A problem caught at the source is one alert and one fix. A problem caught in the dashboard is a corrupted report that’s already been distributed.
This is one of the core advantages of centralizing data preparation in a platform like ClicData rather than relying on ad hoc scripts or shadow spreadsheets scattered across teams. The enforcement layer is built into the pipeline, not retrofitted into the visualization layer.
-- Contract validation as a dbt test
-- Any row returned here fails the test and halts the pipeline
-- tests/assert_orders_valid.sql
SELECT
order_id,
revenue,
order_date
FROM {{ ref('stg_orders') }}
WHERE
revenue < 0 -- revenue must be non-negative
OR order_date IS NULL -- date must always be present
OR order_date > CURRENT_DATE -- no future-dated orders permitted
-- Rows returned = test failure. Data stays put until resolved.Route validation failures to wherever the team actually monitors: Slack, PagerDuty, email. An alert that lands in a log nobody reads is operationally worthless.
Step 4: Make Contract Changes a Formal Process
When a producer needs to modify a dataset, for example, like adding a column, changing a type, or deprecating a field, the contract becomes the coordination mechanism. The producer proposes an update, consuming teams review it, and breaking changes go through a deprecation window rather than landing without notice. That shift in how schema changes are handled is where most of the operational benefit shows up. Teams that implement contracts properly and enforce them at every pipeline run consistently report fewer unplanned pipeline failures and faster resolution when breaches do occur.
Implementing Lineage: What Actually Matters
Full end-to-end lineage is easier to scope when framed around a few concrete questions:
- Which source tables feed this KPI?
- What breaks if this model changes?
- Which dashboards are affected when a source goes down?
- What transformation produced this specific field?
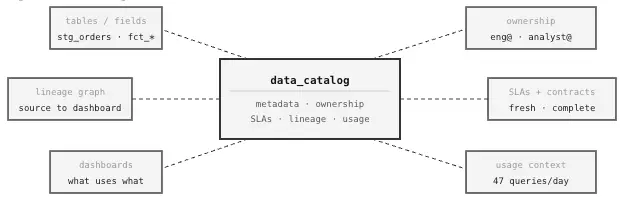
Image by Author. One single place to find if data exists, who owns it, and whether it can be trusted.
Table-Level vs. Column-Level
Table-level lineage records that Table B was derived from Table A. Useful, but limited. Column-level lineage goes further; it records that net_revenue in Table B came from subtracting discount_amount from gross_revenue in Table A, after filtering out cancelled orders. That specificity is what matters when investigating a metric discrepancy, not just knowing which tables were involved.
In dbt, lineage is generated automatically. Models built with ref() and source() macros have their dependencies recorded at every build; no separate lineage tooling required to get started.
-- dbt model with automatic lineage tracking
-- ref() and source() calls are recorded as dependencies on every build
WITH raw_orders AS (
-- source() flags this as a raw source -- recorded in lineage graph
SELECT * FROM {{ source('shopify', 'orders') }}
),
cleaned_orders AS (
SELECT
order_id,
customer_id,
order_date,
-- net revenue strips out discounts
(revenue - COALESCE(discount_amount, 0)) AS net_revenue,
status
FROM raw_orders
WHERE status != 'cancelled'
),
final AS (
-- ref() flags this as a dependency on dim_customers -- also recorded
SELECT
o.order_id,
o.customer_id,
c.customer_segment,
o.order_date,
o.net_revenue
FROM cleaned_orders o
LEFT JOIN {{ ref('dim_customers') }} c
ON o.customer_id = c.customer_id
)
SELECT * FROM final;After this build, dbt records that fct_orders depends on shopify orders and dim_customers. Any connected catalog, dbt Cloud, Atlan, DataHub, can visualize that chain across the whole project.
If full lineage tooling isn’t in place yet, adding description and meta blocks to every dbt model is worth doing anyway, as it shows what the model does, which sources it draws from, and which dashboards consume it. It’s manual, but it’s searchable, and it’s something that can be automated later without starting from scratch.
What Modern BI Infrastructure Looks Like
With contracts and lineage in place, the operational character of a BI team changes, not dramatically on day one, but noticeably over time. Incident investigation time drops. Metric definition work shifts from reactive cleanup toward proactive governance. New analysts can identify which tables are reliable without relying on whoever has been around the longest.
The stack that supports this follows a recognizable shape:
| Layer | Function | Example Tools |
|---|---|---|
| Contracts | Enforce data expectations at ingestion | dbt tests, Great Expectations, Soda |
| Orchestration | Scheduling, retries, dependency management | Airflow, Prefect, dbt Cloud |
| Lineage | Track data movement and transformation | dbt Docs, OpenLineage, DataHub, Atlan |
| Catalog | Surface metadata, ownership, and usage context | dbt Docs, Atlan, DataHub |
| Monitoring | Alert on SLA breaches and anomalies | Monte Carlo, custom dashboard |
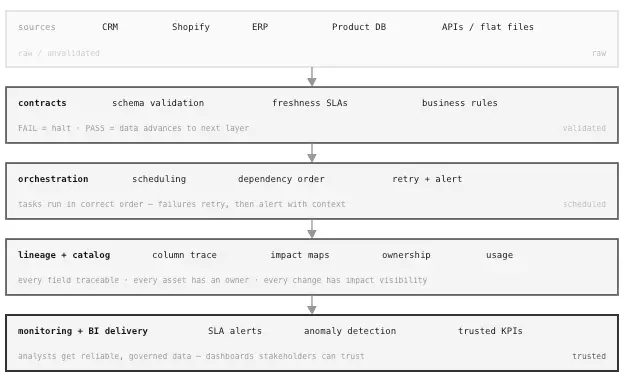
Image by Author. Each layer creates stronger control. Together, they make BI output reliable.
ClicData sits across this stack as the centralized preparation and pipeline layer, where data connections are managed, transformations are defined, and governed outputs are delivered to dashboards without relying on scattered scripts or manual consolidation.
Platforms that centralize and standardize data flows make contracts enforceable in practice. When transformations are visible and documented, rather than scattered across ad hoc scripts and shadow spreadsheets, lineage stops being aspirational and starts being useful.
The connection to AI readiness follows from this directly, and it’s worth being specific about why. Most AI initiatives fail not because the models are wrong, but because the data feeding them is unvalidated, untraced, and inconsistently defined.
A revenue forecast built on a metric that Finance and Sales calculate differently is not a model problem. It’s a governance problem. The same contracts that enforce schema stability for BI dashboards also enforce it for the feature tables that train predictive models. The same lineage that lets an analyst trace a $47,000 discrepancy back to a staging transformation also lets a data scientist verify that a training dataset wasn’t contaminated by a pipeline error. Governed data infrastructure isn’t a BI-specific concern; it’s the foundation that makes any downstream automation, AI, or reporting trustworthy. Why Your BI Strategy Fails Without a Solid Data Foundation goes into those architectural dependencies in detail.
A model trained on unvalidated, untraceable data isn’t “imperfect.” It’s a liability. The same structured environment that makes BI numbers defensible is what makes AI behavior reliable.
Common Mistakes Worth Flagging
- Enforcing quality inside the BI tool. Calculated fields and dashboard filters are presentation logic. Metric definitions belong in the pipeline, in versioned SQL, not in a Looker measure or a platform-level calculated field where each analyst’s definition ends up slightly different across reports.
- Treating a contract file as documentation. A YAML spec with no automated enforcement is just a README. The value of a contract comes from running validations on every pipeline execution and halting when they fail. Skip that step, and the contract is decorative.
- Stopping at table-level lineage. Knowing that Table B depends on Table A is context. Knowing that a specific net_revenue column traces back to a particular transformation applied to a specific source field is what actually helps when a board-level report is showing the wrong number.
- Adding governance tooling before fixing the underlying data. Contracts and lineage built on top of dirty primary keys, inconsistent join logic, or undocumented date fields will amplify the problem. The sequence matters: stabilize core data quality first, then formalize contracts, then layer in lineage tooling.
- No named owner for critical datasets. A contract without an accountable owner creates a false sense of security. When an SLA is breached, someone specific needs to be responsible for investigating and resolving it, not “the data team.”
Conclusion
BI teams that still operate primarily as report builders will keep running into the same class of problems: errors found after distribution, decisions delayed, and reports that quietly lose their audience.
Changing that requires structural work, not more tooling. Contracts define what data must look like before it moves. Lineage maps every step it takes once it does. Neither is a heavy lift to start, and both pay off quickly once the first critical pipeline is under proper control.

Run that pattern on the datasets that drive real decisions, and expand from there.
If the failure modes in this article sound familiar, the underlying fix is structural, not cosmetic. Book a session with ClicData’s team to see how centralized, controlled data flows reduce the firefighting and give your BI outputs the reliability your stakeholders expect.

