Working with APIs is a core skill for many Data Analysts. But there’s a big difference between pulling data manually and building a fully automated API pipeline. The latter means creating processes that run without supervision, handle complex responses, and deliver accurate data every time.
Often, this involves moving API data into a Data Warehouse for reporting, analytics, or machine learning. To achieve that, you need to think about pipeline design, error handling, data transformations, and workflow orchestration.
In this article, we’ll look at practical ways to take your API pipelines from basic to production-grade — from handling tricky JSON structures to scheduling automated runs — and see how these steps can be simplified using ClicData.
Architecting Scalable API Pipelines
A scalable API pipeline should be able to handle increased volumes of data from a variety of endpoints and at a higher frequency of requests without breaking. Key considerations for architecting such pipelines include modular design and maintainability
Modular Design
Rather than one monolithic script that covers the pipeline end to end, it should be separated into modular components typically based on function. One module can handle calling the API request, another for cleaning and shaping the data and a final one for loading into storage such as a database or file. This decoupling makes the pipeline easier to maintain and scale since each module can be modified without affecting the other. If one module fails, Eg. due to an outage on the API, it won’t necessarily crash the entire pipeline; it can be re-tried or handled in isolation. Modular pipelines also allow scaling specific segments. If external API servers are experiencing low performance & slow to respond, multiple extractors can be run in parallel or if transformations require additional processing, computing resources can be scaled for independently.
Maintainability
APIs can go through version updates. A v1 endpoint today might be replaced by v2 very soon involving a changing format in the response. Pipelines should be adaptable to these changes. This could mean externalizing configuration like base URLs, endpoints or API versions so they can be updated without changing any of the base code. Logic that is dependent on specific schema will be prone to newer fields added or removed from future versions so then adjustments only need to be applied to that module of the code instead of refactoring everything. Version control for code should be used (e.g. via Git) and treated as living code that will undergo improvements. Good documentation is part of maintainability. Comments in code such as API details, endpoints used, parameters, expected schema should be clear. An API pipeline not be treated as a one-off script, but as a long-running system. A bit of planning in architecture such as modularizing components and accounting for future changes will ensure API-driven data pipelines stand the test of time.
Handling Complex API Responses
Data retrieved from more advanced APIs may not be as simple as other inputs such as a table or flat file. Responses can be complex due to having deeply nested JSON, varying schemas and paginated results. To handle each efficiently:
Nested JSON from Hierarchical Data
Complex APIs return JSON responses with multiple levels of nesting. As a Data Engineer, these structures will need to be parsed properly to extract the relevant fields needed. In Python, nested JSON structures can be navigated via dictionary keys or using other utilities to help ‘flatten’ the data. The key is to identify the portion of the JSON that contains the records of interest. Eg, if an API returns daily time series data nested under date keys, then this would require iterating over those keys to pull out each day’s data point.
Pagination and Large Datasets
APIs often limit the amount of data returned from a single call & often requires additional fetching. Eg, an e-commerce API might return 100 products per request but will split the responses into separate pages. Handling pagination could mean writing pipelines to detect if more data is available and iteratively fetching it. This could be via the use of a page number parameter (Eg, page = 2) or tokens to access the next page (Eg, nextPageToken = XYZ). The pattern usually looks like: make a request, process the results, then prepare the next request if a next page is indicated.
Rate limits need to be considered here. Some APIs have strict quotas, where a delay might be needed in between page requests to avoid limits. Pagination should always be handled depending on the logic from the API. Proper pagination handling ensures minimal data loss and unnecessary calls to the API.
Non-Standard or Evolving Schemas
Not all APIs return consistent data. Some APIs can return different fields for different types of requests or have optional sections & fields depending on the response. Eg, a social media API might include an “image_url” field that is only available for posts that have images. These variations will need to be accounted for when parsing API responses.
If the schema changes over time (e.g., a new field is added by the API provider), a well-designed pipeline can log unknown fields and either ignore them or capture them for review.
It’s also helpful to validate responses (Eg, to ensure that numeric fields are stored as numbers, dates are in a specific format) or clean them as needed. In cases of significant schema changes (say the API fundamentally restructures its response), parsing logic may need to be updated. This circles back to the importance of monitoring and modular design.
In summary, expect the unexpected in API responses; write parsing logic that can handle missing fields, extra fields, or slight format differences without crashing. Thoroughly testing pipelines with a variety of response examples (including extreme cases) will make it more robust.
Orchestration
Orchestration and scheduling is what automates API pipelines so they run on a schedule & handle dependencies. Frameworks that enable this include open source options such as Apache Airflow as well as built into Analytics tools such as ClicData. No matter which tool is used, some general best practices apply when it comes to scheduling data pipelines.
Schedules should be aligned with the data availability – if an API updates once a day at midnight, scheduling the pipeline for 1:00 AM daily makes sense. Running it any more frequently would be pointless due to no new data being available.
Business needs must also be considered. If stakeholders need the fresh data by 8 AM each morning, ensure the pipeline finishes before then. Buffers should be added for unexpected situations.
Dependencies need to be managed so that tasks run in the correct sequence. Multiple API calls that are independent can be run in parallel to speed up the pipeline. However, if one piece of data is a prerequisite for another task, then the sequencing will be important.
Always configure alerts or notifications. As a Data Engineer, it needs to be known ASAP if a pipeline run fails so it can be addressed before any downstream impacts.
Finally, periodically review schedules. As data volume grows, a 5-minute job could become 30 minutes, so adjustments may need to be made to the run time or resourcing.
Orchestration doesn’t mean “set and forget” forever. It’s a part of the pipeline that may need tuning and constant review. With good orchestration, API pipelines will run like clockwork, reliably delivering data without manual effort. This is what uplevels API pipelines from a one-off project into a robust data engineering process.
Leveling up APIs with ClicData
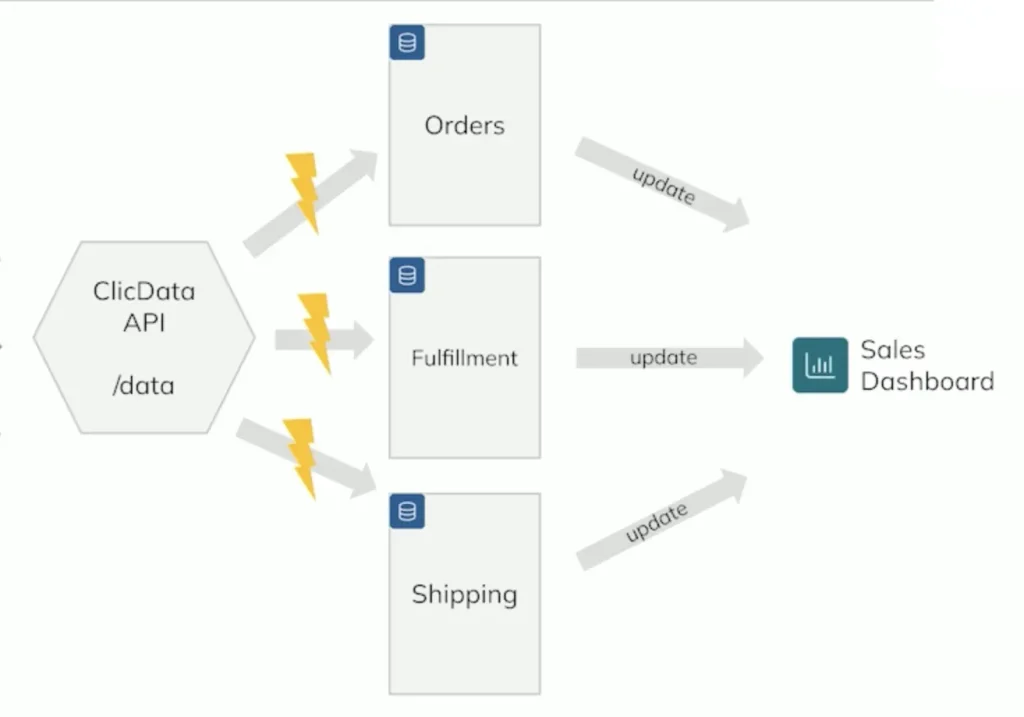
Modularized Design
ClicData helps modularize flows via seperate steps for API calls and downstream processing.
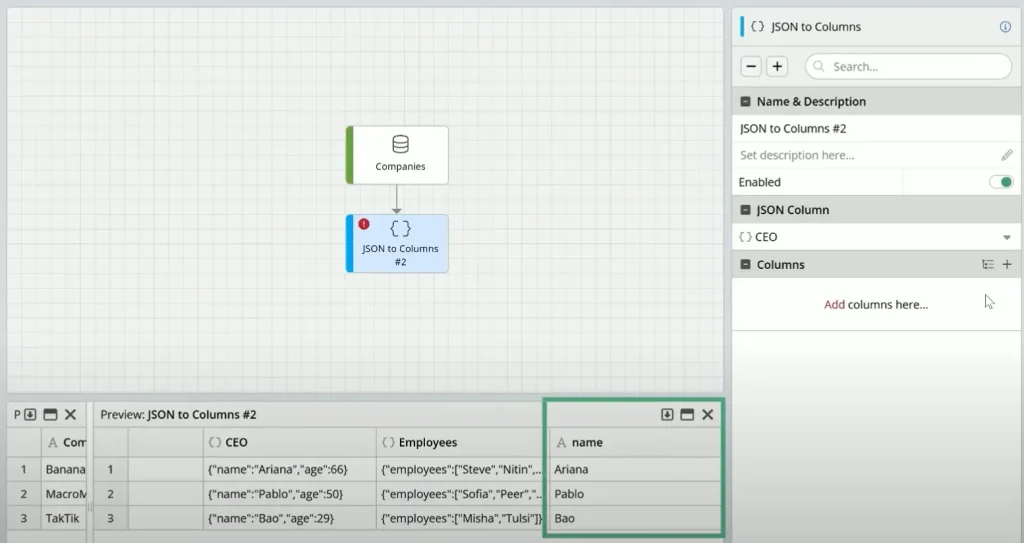
Nested JSON
ClicData can handle the processing of values from nested json objects.
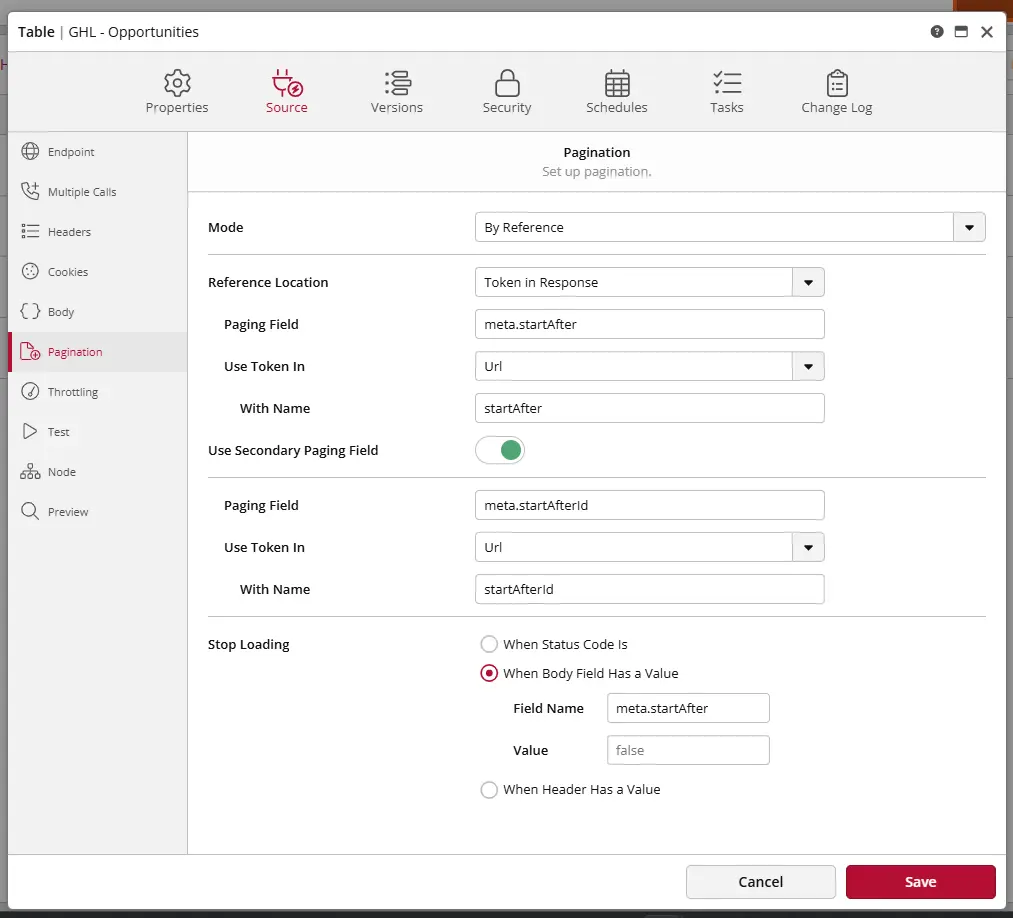
Pagination
Pagination configurations are built into ClicData to run seamlessly.
Wrapping up
Mastering advanced API techniques is the key to a production-grade data pipeline. By modularising code, externalising configurations and planning for retries and version control enables better architecture that scales with both data volume and API changes.
Parsing nested JSON, juggling pagination and defending against schema drift ensures that endpoints are manageable. Robust orchestration keeps the pipeline running on time, with alerts triggered when required. When combined, these practices deliver fresh, trustworthy data from API to Data Warehouse (and eventually business stakeholders).
Leveling up API pipelines is the core of modern, robust pipelines. Start refactoring from the basics, and watch it evolve into an autonomous, scalable pipeline that drives real business value.