IA, machine learning, data science, deep learning… Ces termes envahissent nos discussions autour de la donnée, mais sont souvent confondus ou mal compris. Pourtant, chacun d’eux joue un rôle unique dans l’écosystème des données, avec des objectifs, des méthodologies et des outils bien distincts.
Dans cet article, nous allons clarifier ces notions, explorer leurs interconnexions et vous donner une vision précise des compétences et des technologies nécessaires pour les maîtriser.
Entrons dans le vif du sujet.
IA, Machine Learning, Deep Learning : Définitions
Intelligence artificielle (IA)
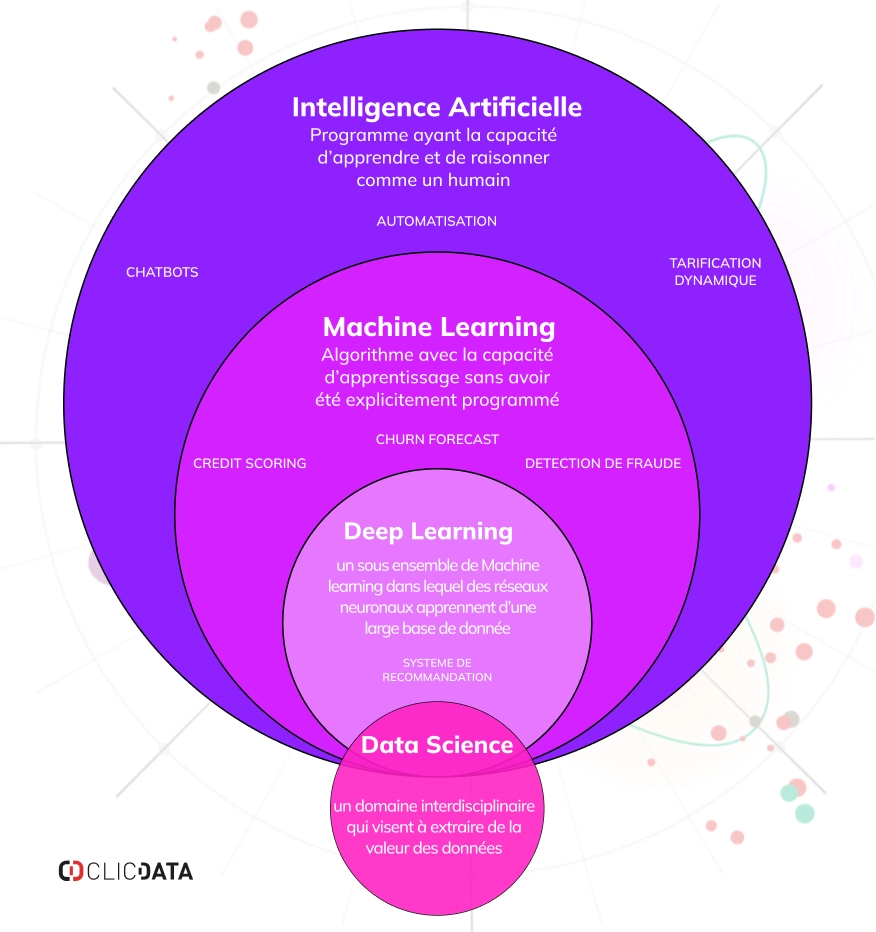
L’intelligence artificielle (IA) est une simulation de l’intelligence humaine par des machines, en particulier des systèmes informatiques. Cela comprend l’apprentissage (l’acquisition d’informations et de règles pour les utiliser), le raisonnement (l’utilisation de règles pour parvenir à des conclusions approximatives ou définitives) et l’autocorrection.
- Outils : Python, Java, C++, MS Azure AI, GPT-4
- Utilisations : Chatbots pour des conseils médicaux, automatisation des campagnes de marketing, tarification dynamique dans les ventes.
- Compétences clés :
- Langages de programmation : Compétences avancées en Python, Java et C++.Algorithmes et structures de données : Connaissances approfondies pour résoudre des problèmes complexes.Machine learning et Deep Learning : Expertise dans diverses techniques, y compris :
- Apprentissage supervisé : Implique la formation d’un modèle sur un ensemble de données labellisées, ce qui signifie que chaque exemple de formation est associé à une étiquette de sortie.Apprentissage non supervisé : Il s’agit de former un modèle sur des données sans réponses labellisées.Apprentissage par renforcement : Un type d’apprentissage automatique dans lequel un agent apprend à prendre des décisions en effectuant des actions et en recevant des récompenses.Deep Learning : Il s’agit de réseaux neuronaux comportant de nombreuses couches (réseaux neuronaux profonds) capables d’apprendre et de prendre des décisions intelligentes par eux-mêmes.Natural Language Processing (NLP) : Techniques de traitement et d’analyse des données linguistiques.
- Résolution de problèmes : Solides compétences analytiques et de résolution de problèmes pour développer des solutions innovantes en matière d’IA.
- Langages de programmation : Compétences avancées en Python, Java et C++.Algorithmes et structures de données : Connaissances approfondies pour résoudre des problèmes complexes.Machine learning et Deep Learning : Expertise dans diverses techniques, y compris :
Machine Learning (ML)
Le machine learning est un sous-ensemble de l’IA qui se concentre sur le développement d’algorithmes permettant aux ordinateurs d’apprendre et de faire des prédictions ou de prendre des décisions à partir d’un ensemble de données.
- Outils : Python, R, MATLAB
- Applications :
- Rapports prédictifs : Utilisation de données historiques pour prédire des événements futurs.
Exemples : prédiction des résultats d’une campagne de marketing, projections des ventes, prédiction du credit scoring d’un client en dans le secteur bancaire ou churn forecast des clients d’un produit SaaS.
- Découverte de modèles : Identification de modèles et de structures dans les données.
Exemples : segmentation des clients ou canaux les plus performants, ventes croisées de produits et découverte des ventes saisonnières, ou détection des transactions frauduleuses.
- Rapports prédictifs : Utilisation de données historiques pour prédire des événements futurs.
- Compétences clés :
- Programmation : Compétences avancées en Python, R et MATLAB.
- Analyse statistique : Solide compréhension des statistiques et des probabilités.
- Algorithmes Machine Learning : Connaissance des différents types d’algorithmes d’apprentissage supervisé, non supervisé et de renforcement.
- Évaluation des modèles : Compétences en matière d’évaluation des performances des modèles à l’aide de mesures telles que l’exactitude et la précision.
- Technologies Big Data : Hadoop, Spark et Kafka.
- Ingénierie logicielle : Compréhension des différents types de modèles de machine learning pour construire et déployer des modèles évolutifs en production, via FastAPI par exemple.
Deep Learning
Le deep learning est un sous-ensemble du machine learning qui implique des réseaux neuronaux à plusieurs couches (réseaux neuronaux profonds). Ces réseaux sont capables d’apprendre à partir de grandes quantités de données et sont particulièrement utiles dans des tâches telles que la reconnaissance d’images et de la parole.
- Outils : Python, Julia
- Applications : Imagerie médicale pour détecter les maladies, systèmes de recommandation de contenu, assistants virtuels.
- Compétences clés :
- Réseaux neuronaux : Compréhension des architectures telles que les CNN, RNN et GAN.
- Programmation : Maîtrise de Python et de frameworks tels que TensorFlow, Keras et PyTorch.
- Mathématiques : Base en calcul, algèbre linéaire et probabilités.
- Prétraitement des données : Préparation de grands ensembles de données pour les modèles.
- Programmation GPU (Graphics Processing Unit) : Expérience de la programmation GPU pour les tâches de Deep Learning.
Résolution de problèmes : Application de techniques à des problèmes complexes tels que la reconnaissance d’images et de la parole.
Data science
La data science englobe tout ce qui a trait aux données lorsqu’elles sont utilisées à des fins d’analyse et de prise de décision. La Data science comprend donc l’analyse des données « classique » et business intelligence, mais si vous cherchez à faire des prédictions et à découvrir des modèles, vous pouvez intégrer des concepts d’IA tels que le Machine Learning et le Deep Learning.
- Outils : Python, R, MATLAB
- Applications : Business intelligence et analyse de données historiques, prédiction de résultats, découverte de modèles, segmentation de la clientèle dans le marketing, prédiction des réadmissions à l’hôpital.
- Compétences clés :
- Programmation : Maîtrise de Python, R et MATLAB.
- Machine Learning : Connaissance des algorithmes et des techniques de modélisation prédictive.
- Analyse statistique et mathématiques : Solides bases en statistiques, probabilités et algèbre linéaire.
- Traitement des données : Manipulation et prétraitement de grands ensembles de données.
- Connaissance du domaine : Connaissances spécifiques à l’industrie pour une application efficace.
- Communication : Traduire des résultats complexes en informations exploitables.
Différences et recoupements
Principales différences
Machine learning et l’IA
L’IA et le Machine Learning sont souvent des termes confondus, car le machine learning est l’une des méthodes les plus importantes et les plus efficaces pour obtenir de l’IA. Lorsque les gens parlent d’IA, ils font fréquemment référence aux applications pratiques de machine learning que nous voyons dans la vie quotidienne, telles que les systèmes de recommandation, les assistants vocaux et la traduction automatique.
Exemples d’utilisation :
- Un filtre anti-spam utilise le machine learning pour identifier et classer les emails comme spams ou non sur la base de données historiques.
- Un chatbot fournissant un service client utilise l’IA, intégrant le machine learning pour comprendre les requêtes des utilisateurs et des systèmes basés sur des règles pour y répondre de manière appropriée.
Deep learning et Machine Learning
Le machine learning et le deep learning sont aussi parfois utilisés de manière interchangeable, car le deep learning est un sous-ensemble du machine learning.
Les deux impliquent l’utilisation de différents modèles pour apprendre à partir de données et faire des prédictions. Cependant, le deep learning utilise spécifiquement des réseaux neuronaux avec de nombreuses couches pour traiter des données et des tâches plus complexes. Étant donné que le deep learning est à l’origine de nombreuses avancées récentes dans le domaine de l’IA, telles que la reconnaissance d’images et de la parole, il est souvent abordé dans le contexte de machine learning, ce qui entraîne une certaine confusion dans la façon dont les termes sont utilisés.
Exemples d’utilisation : Les algorithmes de deep learning alimentent les systèmes de reconnaissance d’images, tels que ceux utilisés dans les voitures autonomes pour identifier les piétons et d’autres objets.
Un modèle de machine learning utilisant un algorithme random forest (ou forêt d’arbres décisionnels) peut être utilisé pour prédire le taux de désabonnement des clients en fonction de diverses caractéristiques telles que les interactions avec le service client et l’historique des achats.
Overlaps
Bien que ces domaines soient distincts, ils se rejoignent à bien des égards. Par exemple, le machine learning et le deep learning sont tous deux des sous-ensembles de l’IA, et la data science intègre souvent des techniques de machine learning.
Data science et machine learning
La data science intègre souvent des techniques de machine learning pour élaborer des modèles prédictifs et tirer des enseignements des données.
Exemple : Un data scientiste pourrait utiliser des algorithmes de machine learning pour développer un système de recommandation pour un site e-commerce, suggérant des produits aux clients en fonction de leur historique de navigation et d’achat.
Machine learning et Deep learning
Rappelez-vous, toutes les méthodes de deep learning sont du machine learning, mais toutes les méthodes de machine learning ne font pas appel au deep learning.
Exemple : Le machine learning et le deep learning peuvent tous deux être utilisés pour des tâches de classification d’images. Une approche plus simple du machine learning peut utiliser la régression logistique sur les caractéristiques extraites, tandis que le deep learning utilise un réseau neuronal convolutif (CNN) pour apprendre et classer automatiquement les caractéristiques à partir d’images brutes.
IA et data science
Les techniques d’IA sont souvent utilisées dans le cadre de projets de data science pour améliorer la modélisation prédictive et automatiser les tâches basées sur les données.
Exemple : Dans le domaine de la santé, l’IA peut analyser les dossiers des patients pour prédire les épidémies, tandis que la data science peut interpréter ces prédictions afin de fournir des informations exploitables pour définir les politiques de santé publique.
Exemple d’utilisation du Machine Learning : Les algo de recommandation de Netflix

Le système de recommandation de Netflix est l’une des applications les plus connues de machine learning. Ce système permet de pousser des films et séries spécifiques sur la base de leur historique de visionnage, améliorant ainsi l’expérience et l’engagement de l’utilisateur. Voici un aperçu détaillé des concepts clés de l’algorithme de recommandation de Netflix :
Concepts clés
Filtrage collaboratif
Le filtrage collaboratif est une technique utilisée pour faire des prédictions automatiques sur les intérêts d’un utilisateur en recueillant les préférences de nombreux utilisateurs. Il repose sur l’hypothèse que si une personne A a la même opinion qu’une personne B sur un sujet, A est plus susceptible de partager l’opinion de B sur un sujet différent que celle d’une personne choisie au hasard.
Filtrage collaboratif utilisateur-utilisateur
Cette approche permet de trouver des utilisateurs aux gouts similaires à l’utilisateur cible sur la base de leur historique d’évaluation et de recommander des productions que le groupe a aimé.
Si les utilisateurs X et Y ont tous deux aimé « Stranger Things » et « Breaking Bad », et que X a également aimé « Narcos », il est probable que Y apprécie également « Narcos ».
Filtrage collaboratif élément-élément
Cette méthode permet de trouver des éléments similaires à ceux que l’utilisateur a aimés dans le passé et de les recommander.
Exemple : Si un utilisateur aime « Helbound » et « Squid Game », le système lui recommande d’autres drames ou films coréens.
Modèles hybrides
Netflix utilise une approche hybride qui combine plusieurs algorithmes de recommandation afin d’améliorer la précision et d’atténuer les limites des méthodes individuelles. Il peut s’agir de combiner le filtrage collaboratif avec le filtrage basé sur le contenu ou d’intégrer les données relatives au comportement de l’utilisateur.
Filtrage basé sur le contenu
Ce modèle recommande des films et séries similaires à ceux que l’utilisateur a aimés par le passé, en se basant sur certaines caractéristiques, comme le réalisateur, les acteurs principaux, ou le genre des films / séries consommées.
Exemple : Si un utilisateur aime un film réalisé par Christopher Nolan, il pourrait se voir recommander d’autres films de Nolan.
Intégration des données comportementales
Ce modèle utilise des données implicites telles que les clics de l’utilisateur, les durées d’affichage et l’historique des recherches pour affiner les recommandations.
Exemple : Si un utilisateur regarde plusieurs épisodes d’une émission culinaire l’un après l’autre, le système peut lui recommander d’autres émissions culinaires ou du contenu connexe.
Techniques de deep learning
Netflix utilise également des modèles de deep learning pour améliorer ses recommandations. Les réseaux neuronaux convolutifs (CNN) et les réseaux neuronaux récurrents (RNN) sont utilisés pour capturer des modèles complexes dans le comportement des utilisateurs et le contenu des films et séries.
Autoencodeurs
Les autoencodeurs apprennent des représentations compactes des préférences des utilisateurs en compressant leurs interactions avec le catalogue. Netflix les utilise pour détecter des patterns latents et proposer des recommandations personnalisées.
Exemple : si un utilisateur apprécie plusieurs animés comme « Death Note » et « Tokyo Ghoul », l’autoencodeur pourrait lui suggérer « Attack on Titan » pour sa tension dramatique similaire.
Réseaux neuronaux récurrents (RNN)
Traitent les données séquentielles pour modéliser la dynamique temporelle des interactions des utilisateurs.
Exemple : Prédire la prochaine émission qu’un utilisateur pourrait regarder en fonction de son historique de visionnage récent.
Si vous souhaitez faire un tour plus complet de la manière dont Netflix utilise le Machine Learning, l’IA et le Deep Learning, nous vous recommandons cet excellent article d’Allen Yu.
Mise en œuvre des algo de recommandation et leurs défis
Collecte de données : Netflix recueille une quantité massive de données, incluant les évaluations des utilisateurs, l’historique de visionnage, les requêtes de recherche et même l’heure à laquelle un utilisateur regarde un contenu, le temps passé, le type d’appareil utilisé, et les interactions sur les notifications.
Évolutivité : le traitement de milliards d’interactions et la formulation de recommandations en temps réel à des millions d’utilisateurs nécessitent une puissance de calculs monstrueuse. Netflix utilise des systèmes informatiques distribués comme Apache Spark pour gérer cela.
Problème de démarrage à froid : les nouveaux utilisateurs et les nouveaux éléments (films/séries) posent un problème car il n’y a pas assez de données d’interaction pour faire des prédictions précises. Les modèles hybrides et le filtrage basé sur le contenu permettent de résoudre ce problème. Netflix étudie donc rapidement les goûts des nouveaux utilisateurs en matière de films et de séries pour entraîner son modèle.
Prêt à faire vos premiers pas dans l’IA, le machine learning et deep learning ?
Nous comprenons l’excitation et l’engouement. Mais avant même de vous lancer dans les gros projets, assurez-vous de la qualité et fiabilité de vos données. Elles sont déterminantes dans la pertinence de vos prédictions ou réponses générées aux clients. Une fois vos données nettoyées, consolidées et standardisées, appliquez des modèles de machine learning pour la modéliser des prédictions et tirez parti du deep learning pour des tâches complexes telles que la reconnaissance d’images.
Pour commencer, vous pouvez :
- Vous familiariser avec des outils clés comme Python, SQL ou TensorFlow.
- Travailler sur des projets réels pour appliquer vos connaissances, comme la construction de systèmes de recommandation ou de modèles prédictifs.
- Vous tenir au courant des dernières avancées en suivant des blogs techniques tels que DataScientest (ressources en français), Towards Data Science, Analytics Vidhya (ressources en anglais), en suivant des cours en ligne et en participant à des communautés d’IA et de data scientists.
Bonne chance pour vos projets, et si vous avez besoin d’aide pour vous lancer, faites appel à nos data scientistes !

