Le machine learning est devenu un pilier clé de la transformation digitale, dans de nombreux secteurs. Des recommandations personnalisées sur les plateformes de streaming aux diagnostics médicaux assistés par intelligence artificielle, le machine learning est partout. Cependant, derrière chaque application se cache un modèle de machine learning spécifique, conçu pour résoudre un problème particulier.
Par exemple, les modèles supervisés génèrent des prédictions, tandis que les modèles de renforcement par apprentissage créent une séquence d’actions. Mais alors, quels sont ces différents modèles ? Comment fonctionnent-ils et dans quelles situations les utiliser ? C’est ce que nous allons découvrir dans cet article
Le Machine Learning, c’est quoi ?
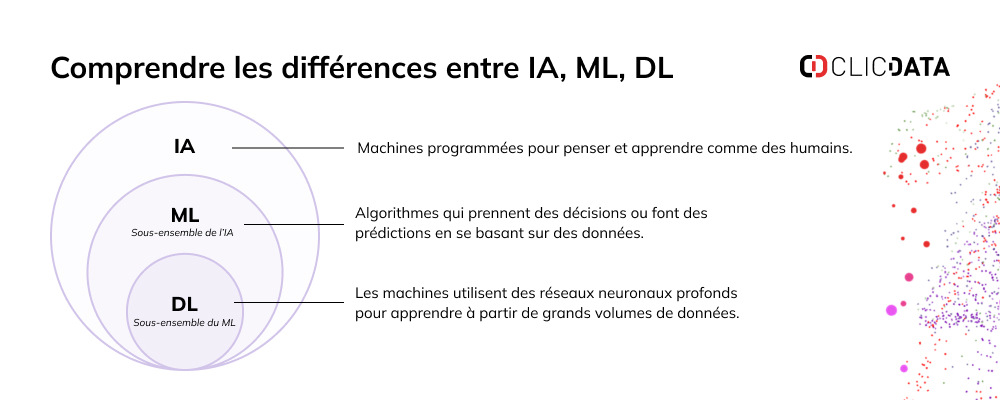
Le machine learning est une sous-catégorie de l’intelligence artificielle (IA) qui consiste à enseigner aux systèmes à effectuer des tâches spécifiques sans programmation explicite. Ces systèmes apprennent des expériences passées ou des données pour améliorer automatiquement leur performance au fil du temps.
De nombreux secteurs utilisent le machine learning. Par exemple, Netflix recommande des films et séries pertinents à ses utilisateurs en fonction de leur historique de visionnage. Le système de machine learning de Netflix apprend les préférences des utilisateurs en observant leur historique de visionnage, avis, clics sur les images de couvertures puis propose des recommandations.
Le marché mondial du machine learning devrait croître de 36,08 % (2024-2030), atteignant un volume de marché de 503,40 milliards de dollars américains en 2030, selon Statista. Cependant, chaque entreprise développe des algorithmes de machine learning adaptés à ses besoins, c’est pourquoi il est indispensable de les connaître les spécificités de chaque modèle.
Les différents modèles de machine learning
Les quatre principaux types de modèles d’apprentissage automatique sont les modèles supervisés, non supervisés, semi-supervisés et par renforcement. Voyons comment chaque type de modèle traite les données pour générer des résultats précis.

Le modèle supervisé
Les modèles d’apprentissage supervisé utilisent des données étiquetées (ou annotées) pour comprendre les patterns cachés. Les données étiquetées comprennent à la fois des variables d’entrée et des classes de sortie.
Le modèle d’apprentissage automatique associe chaque entrée à la sortie correspondante pour comprendre quelles valeurs des caractéristiques conduisent à des outputs spécifiques.
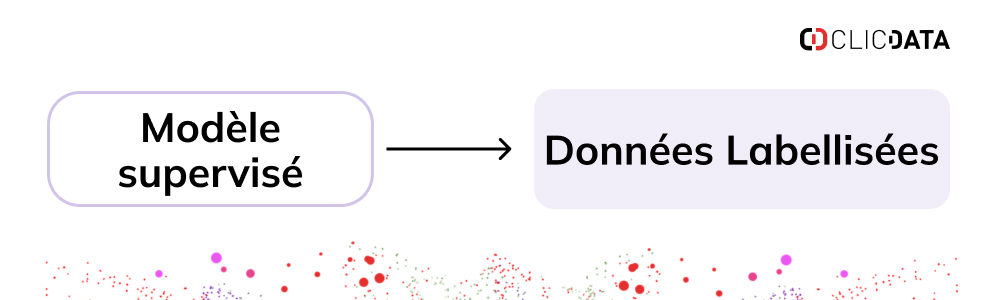
Par exemple, dans un système de filtrage de spam pour les emails, l’entrée serait un ensemble d’emails, et la sortie serait chaque email marqué comme “spam” ou “non spam”.
Dans ce cas, le modèle supervisé permet d’identifier les composants des emails marqués comme “spam”, tels que les expéditeurs illégitimes et les fautes d’orthographe. Voici quelques algorithmes d’apprentissage supervisé les plus communs :
- Arbres de décision
- K-Nearest Neighbors (KNN)
- Support Vector Machines (SVM)
- Réseaux de neurones
Le modèle non-supervisé
Les algorithmes d’apprentissage non supervisé utilisent des données d’entrée non étiquetées pour comprendre des patterns cachés. Ces algorithmes sont utiles pour catégoriser de grands ensembles de données en clusters.
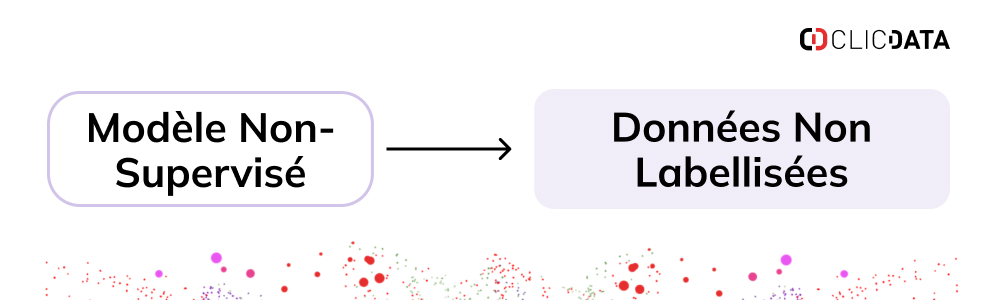
Par exemple, si un modèle d’apprentissage non supervisé ne dispose que d’une liste d’emails sans étiquettes de sortie, il les regroupera en clusters ‘spam’ et ‘non spam’. Parmi les algorithmes d’apprentissage non supervisé courants, on trouve :
- Analyse en Composantes Principales (ACP)
- Clustering K-means
- Clustering hiérarchique
Apprentissage semi-supervisé : Combler le fossé entre l’apprentissage supervisé et non supervisé
Les algorithmes semi-supervisés utilisent à la fois des données labellisées et non labellisées pour entrainer les modèles d’apprentissage.
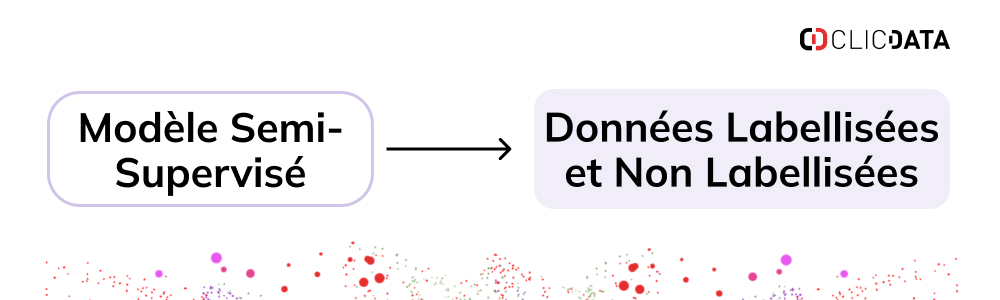
Souvent, ils combinent une petite quantité de données labellisées avec une plus grande quantité de données non labellisées pour améliorer l’apprentisage. Cette approche permet de réduire les coûts (surtout lorsque l’acquisition des données labellisées est élevé) et le temps associé à l’étiquetage manuel des données.
Par exemple, supposons que vous ayez étiqueté quelques centaines d’e-mails comme étant « spam » ou « non spam », mais que vous disposiez de milliers d’autres e-mails non étiquetés. Un modèle semi-supervisé peut utiliser les e-mails étiquetés pour apprendre à distinguer le spam, puis appliquer ces connaissances pour classer les e-mails non étiquetés.
L’apprentissage semi-supervisé commence souvent par la création d’un modèle initial en utilisant uniquement les données étiquetées via des algorithmes comme les Machines à Vecteurs de Support (SVM). Ensuite, d’autres algorithmes tels que le clustering K-means identifient des patterns ou des groupements à partir des données non étiquetées.
Parmi les algorithmes semi-supervisés, on peut retoruver :
- Auto-formation (initialement entraîné sur de petites données étiquetées pour faire des prédictions sur des données non étiquetées)
- Co-formation (entraînement de deux modèles ou plus sur différentes vues des mêmes données)
- Machines à Vecteurs de Support Semi-supervisées (S3VM)
Apprentissage par Renforcement : Comprendre la Prise de Décision et les Récompenses
Dans l’apprentissage par renforcement, un agent apprend à prendre des décisions en interagissant avec un environnement et en recevant un feedback continu sous forme de récompenses et de pénalités. Le feedback constant aide l’agent à comprendre quelles actions mènent à de meilleurs résultats et à affiner sa stratégie en conséquence.
L’apprentissage par renforcement est généralement utilisé dans les applications de jeux vidéo, où il devient progressivement compétent dans les stratégies de jeu grâce aux récompenses et aux pénalités.
Parmi les plus courant, on retoruve :
- Q-learning
- Réseaux de Q-Learning Profond (DQN)
- Méthodes Actor-Critic
Les Modèles de Machine Learning Spécialisés
Les modèles de machine learning spécialisés s’attaquent à des problèmes spécifiques en utilisant des connaissances ou des techniques propres à un domaine spécifique pour optimiser leur performance.
Modèles Hybrides : Combinaison de Plusieurs Types d’Apprentissage
Certains problèmes de machine learning nécessitent la combinaison de plusieurs modèles de machine learning pour améliorer la précision. Combiner divers modèles permet de traiter différents types de données. Par exemple, on peut combiner l’apprentissage profond (DL) avec des méthodes statistiques traditionnelles pour traiter des données structurées et non structurées dans un seul modèle.
Dans des applications spécifiques à un domaine, comme les systèmes de santé, un seul modèle peut ne pas suffire. C’est là qu’un modèle hybride peut intervenir, en combinant le machine learning avec des connaissances spécifiques au domaine, provenant par exemple d’experts médicaux, pour améliorer la précision des diagnostics.
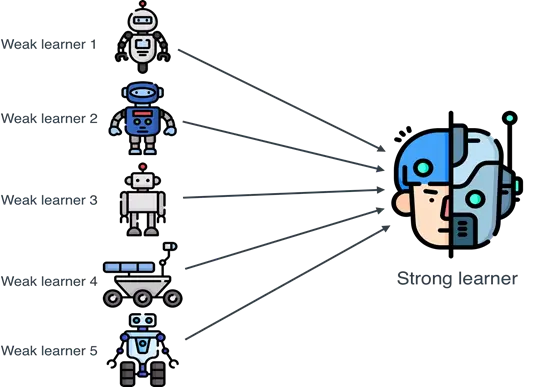
Par exemple, l’Ensemble Learning (ou apprentissage ensembliste) combine et agrège les décisions de plusieurs modèles pour améliorer la précision des prédictions. Voici les techniques les plus courantes :
- Bagging (par exemple, les forêts d’arbres décisionnels)
- Boosting (par exemple, Gradient Boosting Machines)
- Stacking (par exemple, les classificateurs empilés)
Les réseaux de neurones avec modèles de Markov cachés (NN-HMM) sont un autre exemple d’algorithmes hybrides. Ils sont couramment utilisés dans les systèmes de reconnaissance vocale pour combiner les réseaux de neurones pour l’extraction de caractéristiques et la modélisation probabiliste des séquences afin d’améliorer la précision des systèmes de conversion de la parole en texte.
Lorsque les données labellisées sont insuffisantes, les méthodes supervisées traditionnelles peuvent être moins performantes car elles dépendent d’un grand nombre d’exemples labellisées. C’est pourquoi, combiner les techniques d’apprentissage permet d’améliorer les performances des modèles. Voici comment cela fonctionne :
- Entraîner un classificateur initial sur un petit ensemble d’images labellisées
- Utiliser ce classificateur pour prédire la classification des images non labellisées
- Combiner les nouvelles images labellisées avec l’ensemble d’images non-labellisées d’origine pour réentraîner et affiner le classificateur
Les modèles hybrides offrent plus de flexibilité et d’adaptabilité en atténuant les limitations des algorithmes uniques.
Modèles Hybrides : Exemples d’Application
Maintenant que nous comprenons les avantages des modèles hybrides, examinons comment ils sont utilisés dans divers secteurs :
Finance
- Détection de Fraude :
Les modèles sont formés sur de grands volumes de données pour identifier les transactions frauduleuses. Les systèmes de détection d’anomalies (apprentissage non supervisé) repèrent des motifs inhabituels dans les données transactionnelles, tandis que les modèles de classification (apprentissage supervisé) confirment si ces anomalies sont frauduleuses.
- Scoring de Crédit :
Cela permet d’aider à évaluer la solvabilité des demandeurs de prêts. Les arbres de décision assistent dans la sélection des caractéristiques et la classification initiale, tandis que les réseaux de neurones affinent le processus de scoring en apprenant des motifs complexes dans les données.
Marketing
- Segmentation et Ciblage des Clients : L’algorithme de clustering (apprentissage non supervisé) identifie les segments de clients, tandis que les analyses prédictives supervisées prévoient les réponses des clients à différentes stratégies marketing. Cela permet de segmenter les clients en groupes distincts en fonction de leur comportement d’achat et de les cibler avec des campagnes marketing personnalisées.
- Systèmes de Recommandation : Le filtrage collaboratif utilise les données d’interaction utilisateur-article pour suggérer des articles correspondant aux préférences individuelles, tandis que le filtrage basé sur le contenu utilise les caractéristiques des articles et des utilisateurs pour recommander des articles similaires. Cela permet de recommander des contenus favoris aux utilisateurs.
Transport
- Véhicules Autonomes : La vision par ordinateur (apprentissage supervisé) et l’apprentissage par renforcement améliorent la reconnaissance des systèmes de conduite autonome. La vision par ordinateur traite les entrées visuelles pour détecter et reconnaître les objets, tandis que l’apprentissage par renforcement optimise les stratégies de conduite à travers un cycle de récompense et de pénalité en temps réel.
- Gestion du Trafic : Les modèles d’analyse de séries temporelles prévoient les motifs de trafic basés sur des données historiques, et les algorithmes de clustering regroupent des conditions de trafic similaires pour mettre en œuvre des stratégies de gestion du trafic efficaces. Cela permet de prédire et de gérer le flux de trafic.
Problèmes d’Apprentissage Résolus par Différents Modèles
Différents modèles d’apprentissage automatique résolvent divers problèmes, les rendant adaptés à différents cas d’utilisation.
Voyons quels sont principaux problèmes que rencontrent les modèles de classification, de régression, ainsi que ceux de détection d’anomalies ou de reconnaissance de patterns.
Problèmes de Classification (Binaire et Multiclasse)
Les algorithmes de classification apprennent des motifs à partir de données d’entraînement étiquetées et classifient les nouvelles données en différentes catégories selon ces apprentissages.
- Classification Binaire : Par exemple, un filtre anti-spam pour emails est un système de classification binaire qui détermine si un email est « spam » ou « non spam ». De même, la reconnaissance faciale sur un smartphone est un modèle binaire qui identifie les utilisateurs comme « non reconnus » ou « reconnus ». Ces systèmes utilisent souvent la régression logistique pour la classification binaire.
- Classification Multiclasse : Par exemple, la fonctionnalité de recommandation d’emplois sur LinkedIn classe les offres d’emploi en différents secteurs comme la technologie, la finance, ou le marketing, en fonction de l’activité des utilisateurs. Les algorithmes multiclasses comme les arbres de décision et les machines à vecteurs de support permettent d’atteindre ces résultats.
Problèmes de Régression : Prédiction des Résultats Continus
Les algorithmes de régression prévoient des résultats continus, comme les prévisions météorologiques ou les pertes financières, en se basant sur des conditions pertinentes.
Par exemple, les algorithmes de régression analysent les tendances historiques et d’autres facteurs pour prévoir les prix du marché boursier.
Un autre usage est la prévision de la valeur à vie du client (CLV) pour les entreprises eCommerce, où les algorithmes analysent les habitudes d’achat et les comportements de dépense pour prédire les achats futurs et ainsi aider à la formation de stratégies commerciales.
Détection d’Anomalies et Reconnaissance de Modèles
Les systèmes de détection d’anomalies identifient les comportements ou motifs anormaux et alertent les parties prenantes pour prendre des mesures correctives.
- Sécurité : Par exemple, les algorithmes de détection d’anomalies en cybersécurité repèrent et signalent les comportements suspects pour éviter les menaces potentielles. Les sociétés de cartes de crédit utilisent également ces modèles pour détecter les activités frauduleuses en analysant les motifs de transactions des clients.
- Reconnaissance de Modèles : Les systèmes de reconnaissance de modèles sont souvent utilisés dans les applications de conversion de la voix en texte, comme l’assistant vocal de Google ou les services de transcription, pour convertir les caractéristiques audio en équivalents textuels.
Machine Learning et perspectives d’avenir

Le Rôle Croissant de l’Automatisation
L’automatisation va permettre aux modèles d’apprentissage automatique de générer et d’optimiser d’autres modèles de manière autonome, rendant le processus plus efficace et précis.
L’Apprentissage Automatique Quantique
En combinant l’informatique quantique avec l’apprentissage automatique, on pourra traiter des quantités massives de données à des vitesses beaucoup plus élevées, transformant ainsi le traitement des données et l’optimisation.
L’Apprentissage Automatique Respectueux de la Vie Privée
Des techniques comme l’apprentissage fédéré et la confidentialité différentielle vont protéger les données personnelles tout en permettant des analyses avancées, répondant ainsi aux préoccupations croissantes sur la vie privée.
Exploration de Nouveaux Domaines
Les chercheurs explorent comment ces technologies peuvent résoudre des problèmes inédits, comme analyser des œuvres d’art ou prédire les mouvements de marchés volatils, ouvrant la voie à de nouvelles innovations.
Bien que les algorithmes actuels répondent efficacement à divers défis, le potentiel des avancées futures est immense. Que ce soit pour lutter contre le changement climatique en améliorant les prévisions météorologiques ou révolutionner les soins de santé avec des outils de diagnostic plus précis, l’apprentissage automatique est une force puissante qui nous guide vers de nouvelles possibilités.

