Dashboards don’t fall apart because of pretty charts. They fall apart because revenue means one thing in Sales, another in Finance, and a third in Marketing.
When every analyst writes their own SQL from scratch, definitions drift, and trust erodes.
This guide shows how modular SQL, reusable, layered queries built with common table expressions, keep KPIs consistent across BI dashboards, make SQL queries easier to maintain, and scale with your data pipelines.
Let’s dive in!
Why Modular SQL Matters
Modular SQL fixes data standardization by putting one clear definition at the center, and letting every report reuse it.
- The problem: KPI logic lives in dozens of places, each with tiny differences.
- The impact: Confusion, “why don’t these numbers match?”, slow debugging, lost credibility.
- The fix: Write the metric once, use it everywhere. Modular SQL standardizes logic, cuts duplication, and reduces risk.
New to KPI-first reporting? Start with this quick primer on why KPI dashboards work and what they unlock for teams.
Foundations of Modular SQL
Modular SQL means writing queries as small, reusable pieces, so a KPI is defined once and used everywhere. Those building blocks are CTEs (Common Table Expressions).
CTEs break a big query into LEGO-like steps, each step does one thing (filter, join, aggregate). That makes your SQL:
- Readable: follow the story top-to-bottom.
- Testable: SELECT * FROM <cte> to validate a step in isolation.
- Reusable: pull the same block into multiple queries instead of copy-pasting.
- Collaborative: shared, named steps make reviews and handoffs easy.
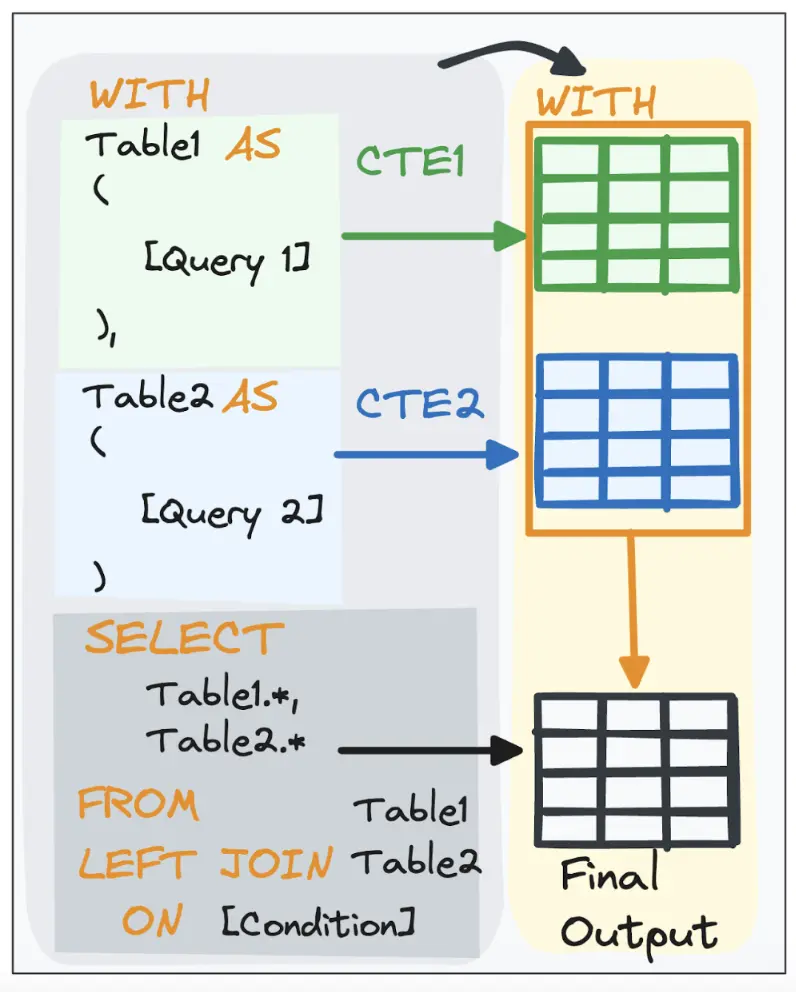
Understanding CTEs.
To illustrate, this article uses two simple demo tables throughout:
- Agents: A small lookup table with one row per support agent, including their ID, name, and region.

Agents table. It contains three main columns: agent_id, agent_name, and region.
- Tickets: The event table with one row per support ticket: who handled it (agent_id), when it opened/resolved, CSAT score, and priority. Perfect for KPIs like on-time resolution and average CSAT.

Tickets table. It contains three main columns: ticket_id, agent_id, opened_at, resolved_at, csat_score, and priority.
To make this concrete, let’s build a regional SLA leaderboard that indicates which regions are both fast and well-rated right now. You can cram all of that into one long SQL statement, as you can observe below.
-- Non-modular (no CTEs) equivalent
SELECT
rk.region,
rk.total_tickets,
rk.on_time_rate_pct,
rk.avg_csat,
aa.active_agents,
ROUND(rk.total_tickets::numeric / NULLIF(aa.active_agents, 0), 2) AS tickets_per_agent
FROM (
SELECT
rr.region,
COUNT(*) AS total_tickets,
100.0 * SUM(rr.on_time)::float / COUNT(*) AS on_time_rate_pct,
AVG(rr.csat_score)::numeric(3,2) AS avg_csat
FROM (
SELECT
a.region,
EXTRACT(EPOCH FROM (t.resolved_at - t.opened_at))/3600.0 AS resolution_hours,
CASE WHEN (t.resolved_at - t.opened_at) <= INTERVAL '24 hours' THEN 1 ELSE 0 END AS on_time,
t.csat_score
FROM tickets t
JOIN agents a ON a.agent_id = t.agent_id
WHERE t.opened_at >= DATE '2025-10-01'
AND t.resolved_at IS NOT NULL
) AS rr
GROUP BY rr.region
) AS rk
LEFT JOIN (
SELECT region, COUNT(*) AS active_agents
FROM agents
GROUP BY region
) AS aa
ON aa.region = rk.region
ORDER BY tickets_per_agent DESC, rk.on_time_rate_pct DESC;
That would give us the following final table:

Regional SLA leaderboard table.
It gets the job done, but it’s a pain to live with.
A single, nested query is harder to read, test, and reuse. The intent is buried; it’s not obvious which part computes what, and if you need active_agents somewhere else, you’ll probably rewrite the logic from scratch.
The modular (CTE) version delivers the same result in small, named steps. You can see what each step does, validate it in isolation, and reuse the pieces across dashboards.
Need a refresher on the plumbing beneath your queries? This ETL basics guide grounds the extract-transform-load flow your CTEs sit on.
#1 Write Once, Use Everywhere
If a metric matters, it deserves a single, shared definition. Don’t copy-paste the math into five dashboards and hope they line up later.
- Centralize logic for metrics (like for the number of active agents per region or active_agents).
- Publish the metric once, either as a database view or a managed model in your stack such as dbt or ClicData’s Data Script SQL, and have every downstream query reference it.
- Change it once and let the update flow downstream.
For instance, if we need to know the number of active agents all the time, we should define a simple query that computes this and always refer to this same query to add this indicator to any other calculation.
– Compute the number of active agents by region
SELECT
region,
COUNT(*) AS active_agents
FROM agents
GROUP BY region
Now we can easily plug this query as an independent CTE where it is required, which brings us to the next natural step.
#2 Use Common Table Expressions (CTEs) to Structure Queries
Instead of one giant query, as we first saw in the beginning, we can split the work into small steps where each step has one simple job. That makes the logic easy to read, easy to test, and easy to reuse elsewhere.
- CTE 1 – active_agents (independent): read straight from agents and count how many agents operate in each region. No dependencies. This is a small, stable lookup you can reuse in other models.
- CTE 2 – recent_resolved (shaping): take raw tickets, join to agents to bring in the region, and derive the SLA fields ( on-time flag, number of tickets). This concentrates all the “per-ticket” logic in one place.
- CTE 3 – region_kpis (aggregating): roll recent_resolved up to the region grain to compute the KPIs you care about (total tickets, on-time rate, average CSAT). Now you have a clean, dashboard-ready surface per region.
- Final SELECT (presentation): join KPIs with active_agents to add a capacity signal (e.g., tickets per agent) and apply any thresholds/sorting a specific dashboard needs.
Think of it as a thread of temporary tables you can reference:
WITH
active_agents AS (...),-- counts agents by region (raw → lookup)
recent_resolved AS (...),-- tickets + region + SLA fields (raw → shaped)
region_kpis AS (...) -- KPIs at region grain (shaped → aggregated)
SELECT ... -- presentation: join KPIs to headcount
FROM region_kpis
LEFT JOIN active_agents USING (region);
Why this works:
- Readable: top-to-bottom tells a clear story (lookup → shape → aggregate → present).
- Testable: SELECT * FROM recent_resolved to validate SLA math without digging through nested subqueries.
- Reusable: active_agents and region_kpis can be promoted to views/dbt models and reused across other dashboards. No copy-paste logic, no drift.
Quality of data is the multiplier; here’s why data accuracy matters and how to defend it as you modularize.
#3 Separate business logic from presentation logic
It is important to know our data journey doesn’t end in the SQL query output. Usually, we then lead this data into a BI solution (like a dashboard) to show to the stakeholders. This is why it is important to learn how to differentiate between Business logic and Presentation logic:
- Business logic (source of truth): where KPIs live. Encode rules like on-time, active agents, and so on.
- Presentation (per-dashboard slice): Lightweight filters, sorts, thresholds, and column renames. No math here, just shape the already-defined KPIs for a specific audience in your BI tool.
Rule of thumb: If changing a chart requires editing the KPI formula, your layers are mixed. Move the formula into the business layer; let the dashboard layer only select/where/order.
Building Modular SQL in Practice
Now that you have understood the logic behind modular SQL, let’s exemplify this with our main goal: let’s build a modular SQL query that computes a regional SLA leaderboard.
#4 Create Reusable KPI Definitions
Below we compute two shared service KPIs (active_agents and avg_csat) and then surface a compact regional snapshot you can reuse across BI dashboards or promote to a view/dbt model.
If we follow the logic described in Section #2, we would obtain the following SQL query:
WITH
-- Independent CTE: purely from raw 'agents'
active_agents AS (
SELECT
region,
COUNT(*) AS active_agents
FROM agents
GROUP BY region
),
-- Tickets stream: filter scope + SLA fields, then attach region
recent_resolved AS (
SELECT
t.ticket_id,
a.region,
EXTRACT(EPOCH FROM (t.resolved_at - t.opened_at))/3600.0 AS resolution_hours,
CASE WHEN (t.resolved_at - t.opened_at) <= INTERVAL '24 hours' THEN 1 ELSE 0 END AS on_time,
t.csat_score
FROM tickets t
JOIN agents a ON a.agent_id = t.agent_id
WHERE t.opened_at >= DATE '2025-10-01'
AND t.resolved_at IS NOT NULL
),
-- Aggregate KPI math at the region grain
region_kpis AS (
SELECT
region,
COUNT(*) AS total_tickets,
100.0 * SUM(on_time)::float / COUNT(*) AS on_time_rate_pct,
AVG(csat_score)::numeric(3,2) AS avg_csat
FROM recent_resolved
GROUP BY region
)
-- Final presentation: add capacity signal (tickets per agent)
SELECT
rk.region,
rk.total_tickets,
rk.on_time_rate_pct,
rk.avg_csat,
aa.active_agents,
ROUND(rk.total_tickets::numeric / NULLIF(aa.active_agents, 0), 2) AS tickets_per_agent
FROM region_kpis rk
LEFT JOIN active_agents aa USING (region)
ORDER BY tickets_per_agent DESC, rk.on_time_rate_pct DESC;
So let’s learn what this does in plain English.
CTE 1 — active_agents
Counts how many support agents operate in each region, straight from the agents. Independent CTE = easy to reuse anywhere.
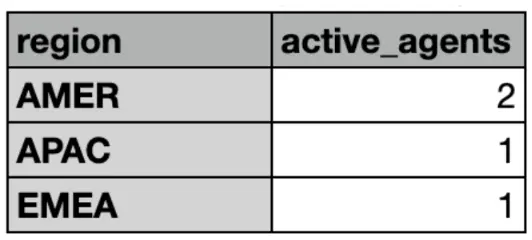
CTE 1 active_agents result. Temporary Table.
CTE 2 — recent_resolved
Starts from raw tickets, joins to agents to bring in the region, and derives:
- resolution_hours: time to close (resolved_at − opened_at, in hours)
- on_time: 1 if resolved within 24h, else 0

CTE 2 recent_resolved result. Temporary Table.
CTE 3 — region_kpis
Rolls ticket rows up to the region grain and computes:
- Total_tickets
- on_time_rate_pct (% of tickets closed within 24h)
- avg_csat (average customer satisfaction)

CTE 3 region_kpis result. Temporary Table.
Final result — regional snapshot
Joins KPIs with headcount to add capacity context, then calculates a simple productivity proxy: tickets_per_agent. The final SELECT is purely presentation: ordering and the extra derived column. There’s no KPI math here.

Final result of the modular query.
So… why does this design work?
Each CTE has a single responsibility (headcount, scoped tickets, regional KPIs). You can test any step with SELECT * FROM <cte>, reuse active_agents or region_kpis elsewhere, and keep your dashboard query paper-thin.
#5 Layer Your Queries for Clarity
Think in three layers so code reviews, audits, and changes stay boring (in a good way):
- Raw / Staging clean and standardize Fix types, dedupe rows, normalize time zones. Keep it close to the source but trustworthy. Examples: recent_resolved.
- Business / KPI define the math once Encode the rules that matter (SLA windows, KPI formulas, exclusions). This is your source of truth. Example: active_agents, region_kpi → publish as temporary views.
- Presentation slice for dashboards
Apply thresholds, sorting, and labeling for a specific view. No new math here. Example: regional SLA leaderboard using the final SELECT.
Why it works: when Finance changes the SLA to 12h, you update a single rule in staging/business (the recent_resolved CTE). Every downstream dashboard stays consistent, no hunting through ad-hoc queries.
#6 Standardize Naming Conventions
Names are your first line of documentation. Make them boring, consistent, and anchored to the grain/purpose.
Use these patterns (aligned to our examples):
- CTEs: active_agents, recent_resolved, region_kpis
- Staging models: stg_agents, stg_tickets
- Business/KPI models (published): kpi_agent_quality, kpi_region_kpis
- Presentation views: dash_support_leaderboard, dash_region_snapshot
Column conventions:
- Keys: *_id → agent_id, ticket_id
- Timestamps (UTC): opened_at, resolved_at, created_at
- Flags/booleans: on_time, is_active
- Metrics: on_time_rate_pct, avg_csat, total_tickets, tickets_per_agent
- Attributes: region, agent
Simple rules that scale:
- One concept per name. No cryptic abbreviations.
- Include grain when helpful. e.g., kpi_region_daily, kpi_agent_weekly.
- Prefer business terms over tool jargon. customer_tier > attr_01.
- Be consistent. snake_case for tables/columns, all lowercase.
Follow these conventions, plus reusable KPIs and clear layering, and your SQL becomes a shared asset, not a stack of one-offs.
Advantages of Modular SQL
Clean SQL is great. But modular SQL pays off in ways the business actually feels, like fewer “why don’t these numbers match?” threads, faster fixes, and less copy-paste risk.
#7 Consistency Across Dashboards
When a KPI lives in one shared model, every dashboard pulls from the same definition.
- Single source of truth: kpi_agent_quality (or kpi_revenue) becomes the place where the math lives.
- No drift: Exec, Ops, and Finance all see the same value because they query the same view/model.
- Low-friction rollouts: Change the rule (e.g., SLA 24h → 12h) once; every chart updates on the next run.
Result: fewer alignment meetings, more confidence in board decks.
#8 Easier Maintenance and Debugging
Layering and reuse turn “hunt through 12 queries” into “fix the model.”
- Edit once → propagate everywhere: Update one CTE or shared KPI model; consumers inherit the fix.
- Faster root cause: If results are wrong in dashboards but right in stg_, the bug lives in the business layer; if wrong in stg_, it’s ingestion.
- Safer changes: Small, named CTEs make code reviews focused—one responsibility per block, one test per rule.
Result: hours saved per incident, fewer hotfixes.
#9 Improved Collaboration
Modular SQL is a shared language your team can read at a glance.
- Readable by default: recent_resolved_tickets and agent_kpi explain themselves—no decoder ring required.
- Reusable by design: New dashboards start from published models instead of rewriting math.
- Clear ownership: Each KPI/view has an owner, tests, and docs, so questions go to the right person.
Result: Analysts ship faster, engineers review faster, and your pipeline becomes a product, not a folder of one-offs.
Common Pitfalls (and how to dodge them)
- CTE soup
- Smell: 300 lines, a dozen nested WITH blocks.
- Fix: Give each CTE a single job, collapse trivial steps, and promote shared logic into a reusable artifact such as a database view, a dbt model, or a ClicData Data Script SQL object (persisted as a view or materialized table).
2. Mystery math
- Smell: No one knows why active_user excludes trials.
- Fix: Add a one-line docstring (what/why) above each CTE/model and link to the metric definition in your catalog.
3. KPIs buried in the BI tool
- Smell: Five dashboards, five “revenue” formulas.
- Fix: Put KPI logic in SQL/dbt (or a semantic layer) and reference it from charts. Treat BI as a presentation only.
4. Messy names
- Smell: q1_report.sql joining tbl_abc to x_users.
- Fix: Use predictable prefixes (stg_, dim_, fct_, kpi_) and consistent keys (*_id, created_at, updated_at). Rename cryptic fields to business terms.
5. Mixed layers
- Smell: Cleaning, business rules, and dashboard filters in one query.
- Fix: Keep the split: raw/staging (types & dedupe) → business/KPI (rules) → presentation (filters/sort).
6. No tests
- Smell: Numbers look off and nothing caught it.
- Fix: Add schema tests (not null, unique), data tests (row-count baselines), and invariants (e.g., net_revenue >= 0). Make critical tests blocking.
Scaling up? If your footprint is moving beyond a warehouse, start here with a practical buyer’s guide to data lake tools.
To sum it up
Modular SQL isn’t a new dialect; it’s a disciplined way to write queries so one definition powers many dashboards. Centralize KPI logic, layer your transformations, and name things so humans can read them. Then back it up with docs and tests.
Treat your SQL like code: version it, document it, reuse it.
Bookmark this framework and pull it out any time you’re building KPI-heavy dashboards or untangling mismatched numbers.
Your future self and your stakeholders will thank you.