SQL, la deuxième langue la plus parlée par les data analystes. Et bien souvent, nous utilisons les mêmes fonctions par habitude, ou par confort, mais il nous arrive parfois de ne pas obtenir les bons résultats.
Dans cet article, nous vous présentons quatre fonctions SQL trop peu connues avec des exemples pratiques.
Fonction SOUNDEX() pour nettoyer les données en fonction de la phonétique des mots
Probablement l’une des fonctions SQL les moins connues mais aussi l’une des plus intéressantes !
La fonction SQL SOUNDEX() est utilisée pour convertir une chaîne de caractères en une représentation phonétique, ce qui est particulièrement utile pour rechercher et faire correspondre des chaînes qui peuvent avoir des orthographes différentes mais des sons similaires.
La fonction SOUNDEX() fonctionne en attribuant un code de quatre caractères à chaque chaîne en fonction de sa prononciation. Les chaînes qui ont des sons similaires auront des valeurs SOUNDEX identiques ou similaires.
Voici la syntaxe de base de la fonction SOUNDEX() :
SOUNDEX(string)Le résultat du SOUNDEX() sur ‘string’ est S365.
Voici comment la fonction SOUNDEX() convertit les caractères en chiffres :
| Chiffres | Caractères |
|---|---|
| 1 | b, f, p, v |
| 2 | c, g, j, k, q, s, x, z |
| 3 | d, t |
| 4 | l |
| 5 | m, n |
| 6 | r |
Les caractères suivants sont ignorés : a, e, i, o, u, h, w et y.
Maintenant, voyons un exemple d’application :
Utiliser SOUNDEX() pour nettoyer des noms de villes
Supposons que vous avez une table avec un champ de nom de ville, et que ces données sont saisies manuellement. Le risque est d’avoir des orthographes différentes pour une même ville, par exemple :
| Nom de la ville |
|---|
| Springfield |
| Springfeld |
| Sprintfield |
| Smithtown |
| Smythton |
Au lieu d’avoir trois versions différentes de ‘Springfield’, nous ne devrions en avoir qu’une seule, tout comme pour ‘Smithtown’.
Utilisons maintenant la fonction SOUNDEX() pour trouver des noms à sonorité similaire :
| Ville | Résultats SOUNDEX |
|---|---|
| Springfield | S165 |
| Springfeld | S165 |
| Sprintfield | S165 |
| Smithtown | S530 |
| Smythton | S530 |
Voilà !
La fonction SOUNDEX() nous permet de détecter les noms de villes qui sont en réalité orthographiés différemment mais ne devraient pas l’être.
C’est un exemple simple de la façon dont vous pouvez utiliser la fonction SOUNDEX() en SQL pour trouver des correspondances approximatives basées sur la similarité phonétique des chaînes.
Pro tip : Pour détecter le vrai nom de la ville, une base de données de villes peut être utilisée, ou si elle n’est pas disponible, vous pouvez compter le nombre d’occurrences de chaque valeur. Ensuite, vous pouvez supposer que le bon est celui avec la valeur la plus élevée.
Attention, SOUNDEX a quelques limitations ! Par exemple, le nombre de caractères à encoder. Voici un exemple avec un nom de lieu plus long :
SOUNDEX('Riverdale Town')
SOUNDEX('Riverdale Park')Les deux retourneront R163 car les lettres suivantes donneront ces résultats :
R > R
V > 1
R > 6
D > 3
Seules les quatre premières consonnes sont encodées (R, V, R, D) et tout ce qui vient après n’affectera pas les résultats de SOUNDEX. C’est pourquoi les mots longs avec les mêmes premières lettres auront les mêmes résultats SOUNDEX().
Fonction LAG pour analyser les données dans le temps
En SQL, la fonction LAG est très pratique lorsque vous cherchez à trouver la valeur précédente ou suivante d’une ligne. Par exemple, nous l’avons utilisée lorsque nous voulions comparer une différence entre deux périodes.
Dans la plupart des cas, vous travaillez avec des données présentées comme ceci :
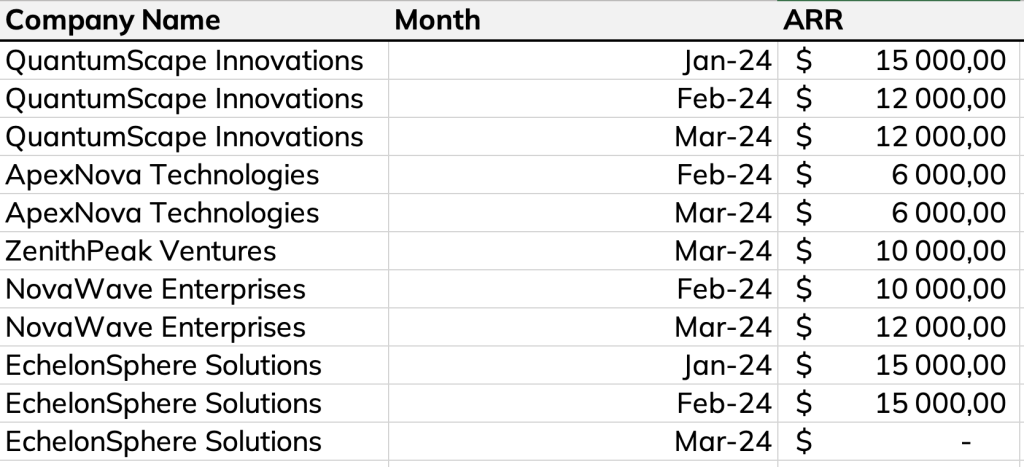
Dans cet exemple, nous examinons une table d’abonnement avec une ligne par client et le montant de leur abonnement pour chaque mois.
Avec cette table, vous pouvez analyser le MRR par client ou le MRR total au fil du temps. Mais vous ne pouvez pas obtenir le nouveau MRR à un moment donné.
Avec la fonction LAG, vous pouvez rapidement effectuer cette analyse. Voici à quoi ressemble la fonction:
LAG(ARR, 0) OVER (PARTITION BY [Month], [Customer] ORDER BY [Month] DESC)Comment lire cette fonction :
- 0 correspond à la valeur par défaut
- LAG sera effectué pour chaque client, par mois (partition by)
- desc parce que nous recherchons la valeur du mois précédent
Pour mesurer le nouveau MRR pour chaque mois, nous recommandons de suivre cette méthode :
- Ajouter une colonne « ARR Previous Month »
- Ajouter une colonne « Delta » qui n’est pas obligatoire mais simplifie les conditions
- Ajouter une colonne « Type » pour identifier les clients Nouveaux, Expansion, Contraction ou Churned.
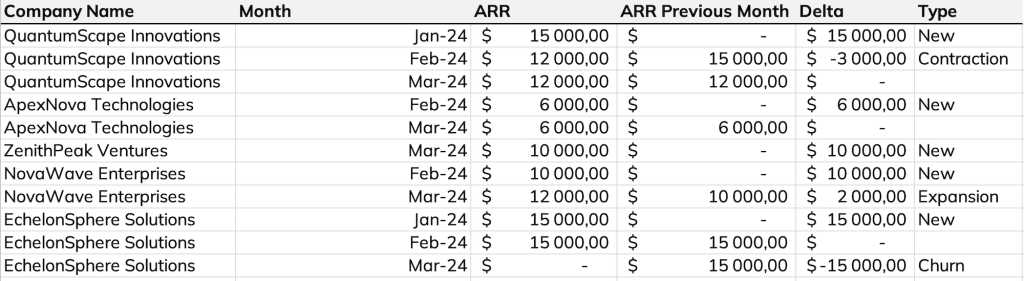
Pour créer la dernière colonne, nous pouvons utiliser l’instruction CASE WHEN avec la logique suivante :
CASE
WHEN LAG([ARR], 0) OVER (PARTITION BY [Month], [Customer] ORDER BY [Month] DESC) IS NULL THEN 'NEW'
WHEN [ARR] > LAG([ARR], 0) OVER (PARTITION BY [Month], [Customer] ORDER BY [Month] DESC) THEN 'EXPANSION'
WHEN [ARR] = 0 THEN 'CHURN'
WHEN [ARR] < LAG([ARR], 0) OVER (PARTITION BY [Month], [Customer] ORDER BY [Month] DESC) THEN 'CONTRACTION'
ELSE 'NO CHANGE'
ENDAvec la colonne Delta, qui est la différence entre ARR et ARR du mois dernier, vous pouvez simplement faire :
CASE
WHEN DELTA > 0 AND [Delta] = [ARR] THEN 'NEW'
WHEN [Delta] > 0 THEN 'EXPANSION'
WHEN [ARR] = 0 THEN 'CHURN'
WHEN [Delta] < 0 THEN 'CONTRACTION'
ELSE 'NO CHANGE'
ENDLa colonne Delta est souvent une meilleure option car elle peut être utilisée dans les tableaux de bord : par exemple, elle révèle qu’en février nous avions +13k $ de ARR et aucune perte, et qu’en janvier le ARR a augmenté de +30k $ sans perte – et que votre équipe commerciale fait un excellent travail ! ️
Fonction PARTITION BY + BETWEEN pour calculer les valeurs sur des périodes glissantes
La fonction SQL PARTITION BY est très courante, mais elle est rarement couplée avec la fonction BETWEEN. Elle peut être très pratique !
Par exemple, si vous voulez calculer les ventes mensuelles de chaque commercial et leurs ventes sur les 12 derniers mois glissants.
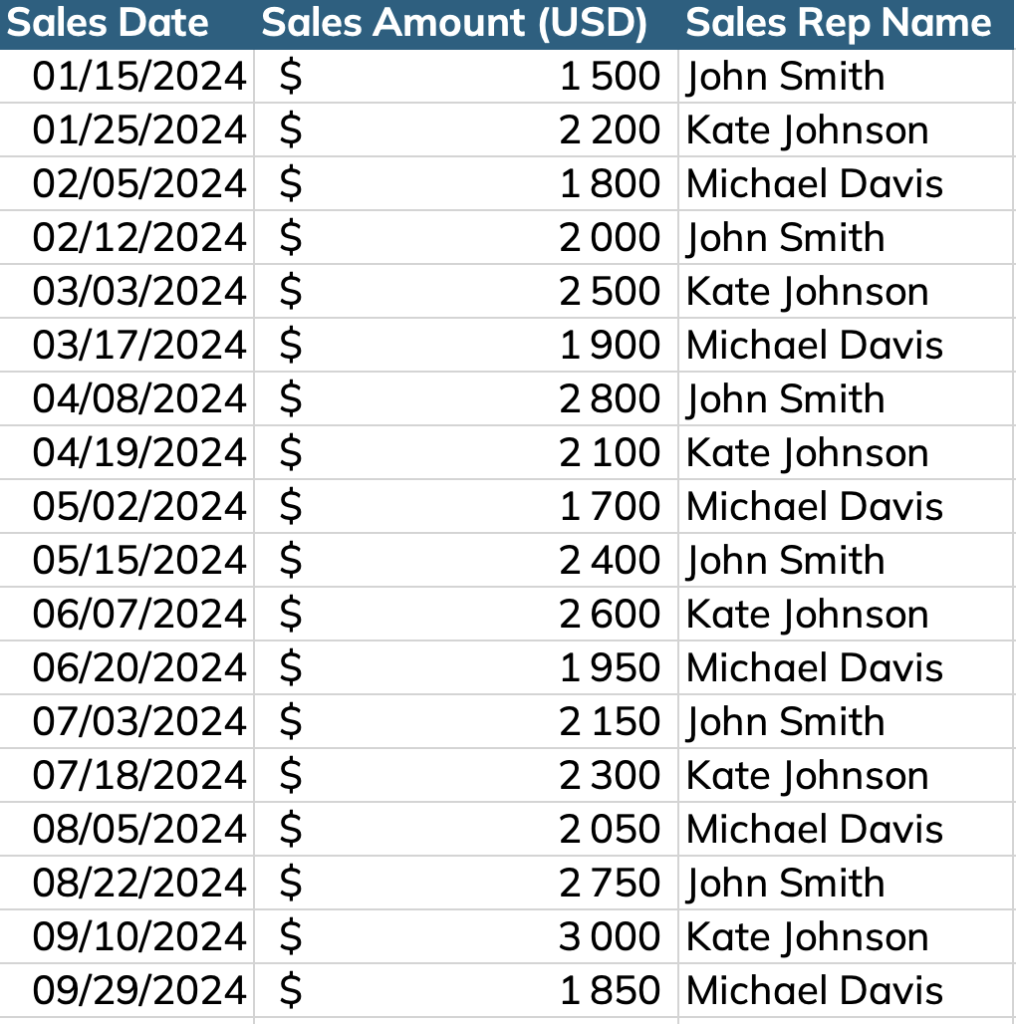
C’est facile dans Excel car il suffit de sélectionner les cellules pour obtenir ces chiffres.
Mais en SQL, ce n’est pas si simple, surtout lorsque les lignes du jeu de données ne sont pas ordonnées ou agrégées au bon niveau et lorsque vous souhaitez analyser les données sur deux types de périodes différentes en parallèle – dans notre exemple, les ventes par mois et les ventes sur 12 mois glissants.
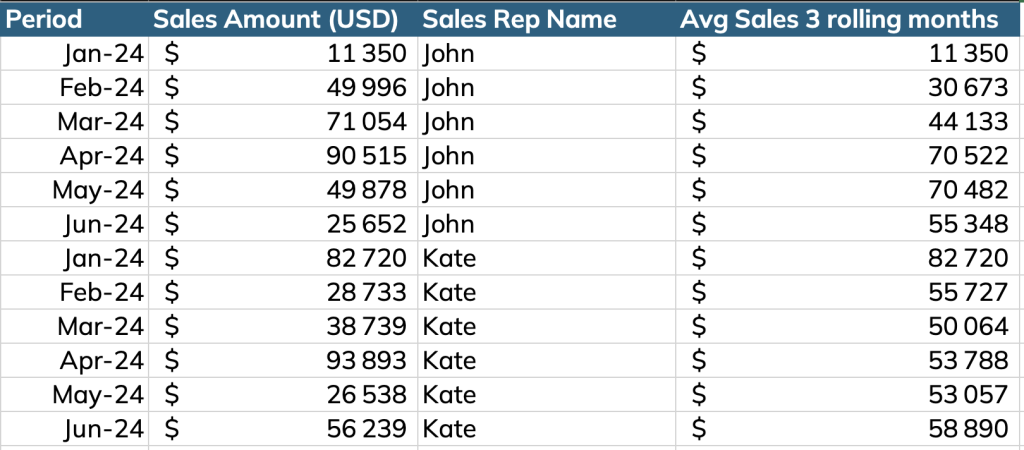
Dans notre exemple, nous voulons analyser les ventes sur 3 mois glissants pour simplifier le jeu de données. Voici les étapes à suivre :
Étape 1 – Convertir la date de vente au format date
En supposant que la date de vente est déjà dans un format standard comme YYYY-MM-DD.
Étape 2 – Calculer le montant moyen des ventes par mois pour chaque représentant commercial
SELECT
EXTRACT(YEAR FROM sales_date) AS sales_year,
EXTRACT(MONTH FROM sales_date) AS sales_month,
sales_rep_name,
SUM(sales_amount) AS sales_amount
FROM
your_sales_table_name
GROUP BY
EXTRACT(YEAR FROM sales_date),
EXTRACT(MONTH FROM sales_date),
sales_rep_name;Étape 3 – Utiliser PARTITION BY et BETWEEN pour agréger les données par mois pour chaque représentant commercial
SELECT
sales_year,
sales_month,
sales_rep_name,
sales_amount AS Sales_per_month,
AVG(sales_amount) OVER (PARTITION BY sales_rep_name ORDER BY sales_rep_name, sales_year, sales_month RANGE BETWEEN 2 PRECEDING AND CURRENT ROW) AS 3months_moving_avg_sales_amount
FROM (
SELECT
EXTRACT(YEAR FROM sales_date) AS sales_year,
EXTRACT(MONTH FROM sales_date) AS sales_month,
sales_rep_name,
SUM(sales_amount) AS sales_amount
FROM
your_sales_table_name
GROUP BY
EXTRACT(YEAR FROM sales_date),
EXTRACT(MONTH FROM sales_date),
sales_rep_name
) AS subquery_alias;Voici la table retournée :
Fonction ROW_NUMBER pour créer des identifiants uniques ou des classements
La fonction ROW_NUMBER peut être utilisée pour de nombreux cas, mais nous l’avons utilisée pour deux scénarios principaux : créer un identifiant unique et créer des classements tout en gérant les valeurs égales. Examinons ces deux cas avec des exemples.
Cas 1 : Utiliser ROW_NUMBER pour créer un identifiant unique
Dans cette simple table, nous avons une liste de 5 publications sur les réseaux sociaux avec le nombre de likes et de commentaires pour chacune d’elles.
ROW_NUMBER() OVER (PARTITION BY [post title] ORDER BY [likes] DESC)Retournera :

La valeur égale à 1 retourne le post avec le plus de likes en raison de l’ordre DESC.
Cas 2 : Utiliser ROW_NUMBER au lieu de RANK pour créer un classement lorsque les valeurs sont égales
Nous voulions vous montrer la différence entre les fonctions ROW_NUMBER et RANK dans un exemple concret. Vous pouvez choisir entre l’une ou l’autre lorsque vous souhaitez créer un classement des publications basé sur le nombre de likes. Dans ce cas, nous avons deux publications qui ont généré le même nombre de likes, 312.
ROW_NUMBER ne permet pas d’avoir deux valeurs identiques, elles seront différenciées en fonction de l’ORDER BY.
La fonction RANK donnera le même ID.

Dans ce cas, en utilisant la fonction ROW_NUMBER, le post « Unlock Business Insights: 5 Analytical Strategies for Success » est classé 1er parce que le titre du post commence par un U, et nous avons utilisé ORDER BY DESC.
Optimisez votre code SQL avec ces 4 fonctions
La transformation des données prend une grande partie de notre temps, alors chaque fois que nous apprenons de nouvelles astuces pour la rendre plus efficace, nous les testons !
Nous utilisons SOUNDEX, LAG, PARTITION BY BETWEEN et ROW_NUMBER assez souvent pour nos projets internes et clients, et l’équipe data les adore !
Si vous connaissez d’autres fonctions SQL sous-utilisées, partagez-les avec nous !
Pro tip : couplez vos fonctions SQL avec les formules ClicData pour affiner le traitement et l’analyse de vos données :