Comment livrer un dashboard fiable, autonome et toujours à jour
Si vous êtes utilisateur de données ou créateur de dashboards, vous ne voulez pas simplement une visualisation ponctuelle.
Vous voulez un dashboard qui reste à jour tout seul, au moment où vous en avez besoin, avec des données qui se rafraîchissent comme prévu et des graphiques qui restent stables dans le temps. Et avec lequel, si quelque chose casse, vous recevez une alerte avant que votre direction ne découvre le problème.
La bonne nouvelle, c’est que tout cela est possible grâce à quelques bonnes pratiques et aux fonctionnalités de ClicData, que nous allons parcourir étape par étape.
Dans cet article, vous allez voir :
- Les fondamentaux pour construire des dashboards à rafraichissement automatique et durables.
- Un walkthrough des fonctionnalités clés de ClicData, avec un mini data pipeline utilisant des données factices: connexion aux sources, transformations, scheduling, alerting et visualisation.
Partie 1 – Quels concepts et bonnes pratiques permettent de construire un dashboard à rafraichissement automatique?
Cette section est une courte checklist des bonnes pratiques pour garantir que les données utilisées dans votre dashboard restent fiables et à jour.
L’objectif est simple: des données correctes, fraîches, et exploitables à chaque ouverture du dashboard, avec un minimum d’effort opérationnel.
1) Comment définir ce que “auto-actualisé” signifie vraiment?
Toutes les situations ne nécessitent pas des données en temps réel. Il peut être utile de vous poser les bonnes questions qui vous aideront à définir ce que signifie vraiment “rafraîchissement automatique” dans votre contexte et à choisir la bonne approche.
- À quelle fréquence avez-vous réellement besoin que les données soient mises à jour?
Le dashboard doit-il afficher des données à la seconde près, ou une mise à jour quotidienne ou hebdomadaire suffit-elle?
Cela dépend de l’usage. Si votre dashboard sert à suivre des performances mensuelles, hebdomadaires ou quotidiennes, un batch quotidien est largement suffisant. Le streaming en temps réel n’est nécessaire que pour des usages très spécifiques. - Comment souhaitez-vous rafraîchir les données?
Souhaitez-vous recharger l’ensemble du dataset à chaque exécution, ou seulement les lignes nouvelles ou modifiées?- L’incremental load est généralement plus rapide, moins coûteux et exerce moins de pression sur les systèmes sources.
- Le full reload est plus lent et plus coûteux, mais parfois utile lorsqu’une reconstruction complète est nécessaire.
2) Comment modéliser pour la durabilité, et pas seulement pour aujourd’hui?
Travaillez en couches pour garder chaque étape simple et réutilisable:
- Raw: ingestion des données telles quelles.
- Transform: nettoyage minimal (types, nulls, normalisation, joins, pre-aggregations).
- Presentation: dataset final dénormalisé, prêt pour le dashboard.
Pour une architecture robuste, pensez aussi à:
- Indexing: choisissez une clé primaire fiable (ou créez-en une).
- Slowly Changing Dimensions (SCD): si vos sources réécrivent l’historique, utilisez created_ts / updated_ts + soft delete.
- Pre-aggregations: regrouper par jour / région / catégorie réduit fortement le coût et la variabilité des queries.
3) Comment rendre votre pipeline de refresh idempotent?
Un pipeline à rafraichissement automatique doit pouvoir rerun proprement, sans dupliquer ni casser quoi que ce soit.
Pour cela:
- Inputs déterministes : Utilisez un champ updated_since ou une fenêtre de 24–48 h pour gérer les retards d’arrivée des données.
- Merges : Faites des upserts sur les clés uniques au lieu d’append-only.
Si un run échoue, relancer ne doit pas créer de doublons. - Outputs atomiques : Écrivez d’abord dans une table temporaire, puis remplacez la table finale seulement si tout a réussi.
- Retries : Essentiel pour les APIs sujettes aux timeouts ou quotas.
4) Comment gérer les contrôles de qualité et les alertes?
La qualité des données doit être vérifiée dès le début du pipeline. Pour cela, posez-vous les bonnes questions à chaque étape.
- Contrôles de volume : Est-ce que le nombre de lignes attendu est toujours supérieur à 0? Comment évoluent les moyennes mobiles? Une baisse soudaine peut révéler un flux partiel.
- Contrôles de schéma : Est-ce que les noms de colonnes ou les types peuvent changer? Que doit-il se passer si une nouvelle colonne apparaît dans la source?
- Règles métier : Le conversion rate peut-il être négatif? Est-il normal que le revenu tombe soudainement à 0%?
- Alertes actionnables : Les alertes doivent être envoyées au bon canal, avec suffisamment de contexte pour diagnostiquer rapidement: dataset concerné, étape, run ID, dernière exécution réussie, et un lien pour investiguer.
5) Documentation
- Documentez clairement les transformations du mini-pipeline qui alimente votre dashboard.
- Pensez à ajouter un fichier README.md pour capturer des informations plus détaillées comme la data lineage, les paramètres utilisés ou toute logique spécifique.
6) Prendre en compte la performance et le coût
- Privilégiez les incremental ou delta loads plutôt que les full refreshes lorsque c’est possible.
Ces approches ne chargent que les données mises à jour, au lieu de recharger l’ensemble du dataset. - Évitez une fréquence de rafraîchissement trop élevée si elle n’est pas nécessaire.
- Limitez les joins trop volumineux ainsi que les colonnes texte très larges dans la couche Presentation.
- Surveillez l’historique des refresh et les taux d’échec pour détecter les dérives ou fragilités du pipeline.
Partie 2 – Walkthrough des fonctionnalités ClicData
Voyons maintenant comment utiliser certaines fonctionnalités clés de ClicData en construisant un data pipeline structuré (présenté ici sur un jeu de données simplifié pour l’exemple) qui sera visualisé dans un dashboard et se rafraîchira automatiquement.
Les données factices incluent :
- commandes : détails de commande (date, produits, quantité, prix)
- clients : région, segment/type
- produits : catégorie, marque
- dépenses marketing : spend_date, canal, montant
Étape 1 : Connecter les sources de données
Ajoutez chaque source comme dataset. ClicData propose de nombreux connecteurs (API, fichiers, spreadsheets, OData, bases de données).
Dans cet exemple, nous avons ajouté: orders.csv, customers.csv, products.csv, marketing.csv.
Conseils
- Normalisez les types de datas dès l’ingestion (dates, nombres).
- Pour les APIs, identifiez les paramètres nécessaires (pagination, périodes).
- Pour les fichiers, verrouillez la structure des onglets pour éviter les ruptures en aval.
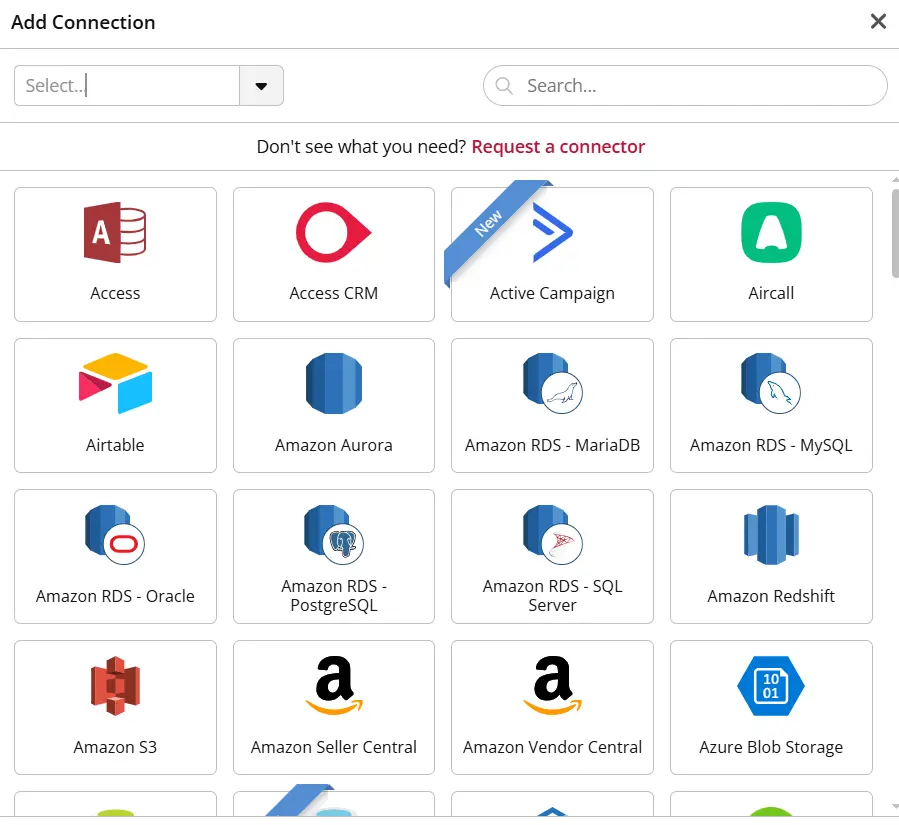
Étape 2 : Construire un Data Flow pour les transformations
Créez un Data Flow avec quatre inputs : commandes, clients, produits, marketing.
Les étapes typiques incluent :
- Nettoyage : cast des types, trim des textes, standardisation des statuts
- Enrichissement : joins entre les datasets
- Agrégation : calcul de métriques quotidiennes (revenue, nombre de commandes)
- Sortie : définition des tables finales
Étape 3 : Orchestrer avec un planning quotidien
Créez un calendrier unique qui exécute les tâches dans le bon ordre :
- Rafraîchissement des sources en mode incremental
- Recalcul des transformations
- Mise à jour de la table finale utilisée par le dashboard
- Ajout de notifications (email/Slack/webhook) et d’une simple retry policy
Étape 4 : Ajouter des alertes de niveau production
Définissez des règles d’alerte qui inspectent les métriques une fois le Data Flow exécuté.
Quelques exemples :
- Revenue dip : le revenue chute au-delà d’un seuil défini
- Conversion anomaly : le taux de conversion sort de sa plage attendue
- Zero data : le row count est égal à 0
Les alertes sont ensuite envoyées aux bonnes équipes (BI, DataOps, support analytics).
Étape 5 : Finaliser le dashboard
ClicData propose des visualisations claires et faciles à configurer.
Fonctionnalités utiles :
- User/Team parameters : définir une région ou une équipe par défaut pour chaque utilisateur
- Dashboard parameters : filtres interactifs pour l’exploration ad hoc
- Indicateur de fraîcheur : pour afficher la dernière date d’extraction
Étape 6 : Monitorer et ajuster dans le temps
- Consultez régulièrement l’historique du schedule pour repérer les temps de traitement qui s’allongent ou les échecs intermittents.
- Surveillez également les durées de rafraîchissement. Si elles commencent à augmenter, plusieurs stratégies peuvent aider: réduire la fenêtre d’historique traitée, ajouter des indexes ou des clés pour accélérer la déduplication, ou encore appliquer des pré-agrégations plus tôt dans le pipeline.
Paramétrer une tâche dans ClicData ne demande que quelques clics, ce qui permet à vos pipelines de se relancer automatiquement.
Conclusion
Un dashboard qui se rafraîchit automatiquement ne devrait pas être un luxe, mais la norme.
Quand vous concevez correctement vos couches de données, que vous planifiez vos pipelines et que vous intégrez des contrôles de qualité dès le départ, vos dashboards cessent d’être des rapports fragiles pour devenir de véritables produits analytics fiables au quotidien.
Et le meilleur dans tout ça?
Vous n’avez pas besoin d’assembler tout cela vous-même.
Les fonctionnalités d’automatisation de ClicData rendent la planification, le rafraîchissement et le monitoring presque transparents. Vous passez moins de temps à “surveiller” vos dashboards et plus de temps à analyser vos données.
Pourquoi ne pas essayer et voir combien de temps vous pouvez gagner grâce à l’automatisation?